pangda/chatgpt-paraphrases-zh
收藏Hugging Face2023-11-06 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/pangda/chatgpt-paraphrases-zh
下载链接
链接失效反馈官方服务:
资源简介:
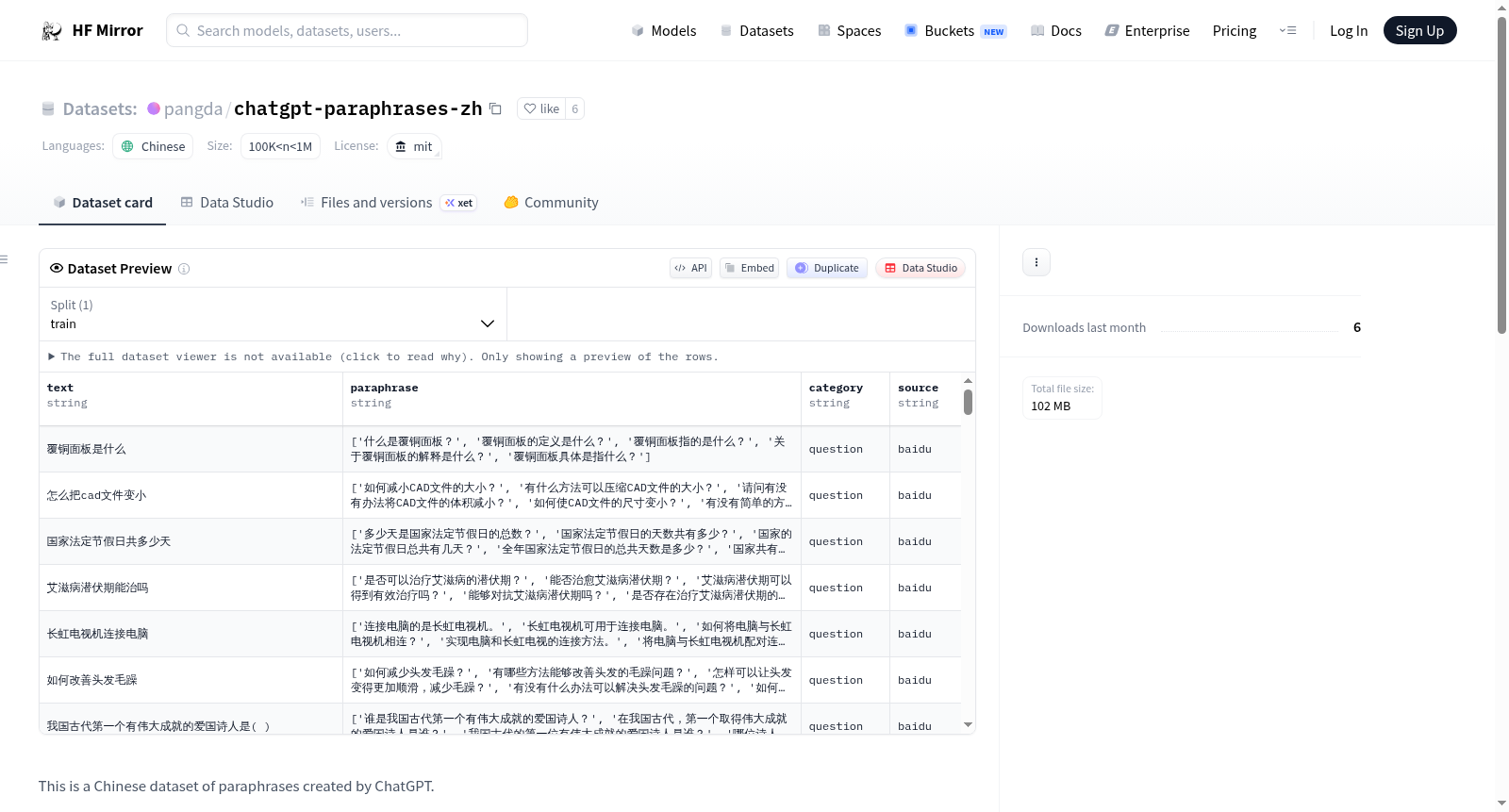
这是一个由ChatGPT生成的中文改写数据集。数据集基于百度和知乎的查询生成,每个样本生成了5个改写,总共有约238k行数据。数据集的结构包括原始句子或问题、5个改写、类别(问题/句子)和来源(百度/知乎)。
This is a Chinese paraphrasing dataset generated by ChatGPT. The dataset is created based on queries from Baidu and Zhihu, with each sample paired with 5 paraphrased versions, totaling approximately 238k rows. The dataset structure includes the original sentence or question, 5 paraphrased versions, category (question/sentence), and source (Baidu/Zhihu).
提供机构:
pangda
原始信息汇总
数据集概述
基本信息
- 许可证:MIT
- 语言:中文
- 数据规模:100K<n<1M
数据集描述
- 创建方式:由ChatGPT生成的中文释义数据集。
- 数据来源:基于百度和知乎的查询数据。
- 数据量:约238,000条数据行。
- 生成方法:每条样本生成5条释义,总计可生成710万对训练数据(238,000行,每行5条释义 -> 6x5x238,000 = 714万对双向数据或6x5x238,000/2 = 357万对唯一数据)。
数据构成
- 百度数据集:82,851个问题
- 知乎数据集:154,885个问题
数据结构
- text列:原始句子或问题
- paraphrases列:5条释义的列表
- category列:问题/句子
- source列:baidu/zhihu
法律声明
- 数据基于OpenAI的gpt-3.5-turbo,其使用条款禁止开发与OpenAI竞争的模型。
引用信息
bibtex @inproceedings{chinese_chatgpt_paraphrases_dataset, author={Shen Huang}, title={Chinese ChatGPT Paraphrases Dataset}, year={2023} }
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,高质量的复述数据对于提升模型的语言理解与生成能力至关重要。pangda/chatgpt-paraphrases-zh数据集的构建依托于百度与知乎平台的海量查询数据,通过精心设计的提示指令,利用ChatGPT模型为每个原始文本生成五条语义相近的改写句子。这一过程共涉及超过23.8万条数据行,每条原始文本均衍生出多个复述变体,为后续的大规模训练提供了丰富的语言素材。
使用方法
使用者可通过加载该数据集,直接访问文本列获取原始句子或问题,并利用复述列表进行模型训练或评估。数据集的每一行均可通过组合原始文本与五个复述句子,构建出大量双向或唯一的训练对,适用于复述生成、数据增强及语义匹配等自然语言处理任务。在实际应用中,需注意遵守OpenAI的使用条款,避免用于开发竞争性模型。
背景与挑战
背景概述
在自然语言处理领域,文本复述技术旨在生成语义相同但表达形式多样的句子,对于提升机器翻译、问答系统及文本增强等任务的性能具有关键作用。pangda/chatgpt-paraphrases-zh数据集由研究人员Shen Huang于2023年创建,基于百度与知乎平台的海量查询数据,利用OpenAI的gpt-3.5-turbo模型生成中文复述样本。该数据集包含约23.8万条原始文本,每条文本对应5个复述变体,总计可构建数百万训练对,为中文语言模型的语义理解与生成能力提供了重要资源,推动了对话系统与文本生成研究的进展。
当前挑战
该数据集致力于解决中文文本复述生成中的语义一致性与表达多样性平衡问题,其挑战在于确保复述结果在保留原意的同时避免句式僵化,并需应对中文语法结构与词汇灵活性的复杂性。构建过程中,依赖大规模预训练语言模型可能引入生成偏差,且数据源来自百度与知乎平台,需处理用户生成内容的噪声与不一致性,同时需遵守OpenAI的使用条款,限制模型在竞争性场景中的应用,这为数据集的广泛部署带来了法律与伦理约束。
常用场景
经典使用场景
在自然语言处理领域,文本改写任务旨在生成语义一致但表达多样的句子,以增强模型的泛化能力。该数据集通过ChatGPT对百度与知乎平台的中文问题进行了大规模改写生成,为研究者提供了丰富的平行语料。经典使用场景包括训练文本生成模型,如序列到序列架构,以提升模型在语义保持与语言多样性方面的表现,广泛应用于机器翻译、文本摘要等下游任务中。
解决学术问题
该数据集有效解决了自然语言处理中数据稀缺与多样性不足的学术挑战。通过提供大量高质量的中文改写对,它支持了语义相似性计算、文本生成评估等核心研究问题。其意义在于推动了中文自然语言理解的发展,为模型训练提供了可靠的数据基础,促进了跨语言与跨领域应用的学术探索,对提升人工智能在真实场景中的适应性具有深远影响。
实际应用
在实际应用中,该数据集被广泛用于智能客服系统的开发,通过生成多样化的用户问题表达,提升系统对自然语言查询的理解与响应能力。此外,它在教育技术领域支持自动问答与内容生成工具,帮助创建个性化的学习材料。在信息检索系统中,改写数据可用于优化查询扩展,提高搜索引擎的准确性与覆盖范围,增强用户体验。
数据集最近研究
最新研究方向
在自然语言处理领域,大规模高质量中文改写数据集的构建与应用正成为前沿热点。pangda/chatgpt-paraphrases-zh数据集基于ChatGPT生成,涵盖百度与知乎的查询文本,提供了丰富的语义改写对,为中文文本增强、语义相似度计算及对话系统优化提供了关键资源。该数据集推动了生成式模型在中文语境下的数据增强研究,特别是在低资源场景下的模型鲁棒性提升方面展现出显著潜力。其生成方式与版权声明也引发了学术界对生成式AI数据使用伦理与合规性的广泛讨论,促进了相关领域对数据来源合法性与模型竞争边界的深入思考。
以上内容由遇见数据集搜集并总结生成


