PSG-coco-format
收藏PSG — Panoptic Scene Graph (COCO format) 数据集概述
数据集简介
这是一个以标准COCO-JSON格式重新整理的**全景场景图(PSG)**基准数据集,适用于目标检测和场景图生成任务。该数据集由SGG-Benchmark框架生成,并用于训练REACT论文中描述的模型。
重要说明:此数据集不包含原始的分割掩码,仅包含边界框和类别标签。因此,它不是一个全景分割数据集,而是一个仅可用于训练基于边界框的场景图生成模型的场景图数据集。
数据集详情
- 任务类别:目标检测
- 标签:场景图、视觉关系检测、全景场景图、COCO格式
- 语言:英语
- 数据规模:10K < n < 100K
- 许可证:MIT
标注概述
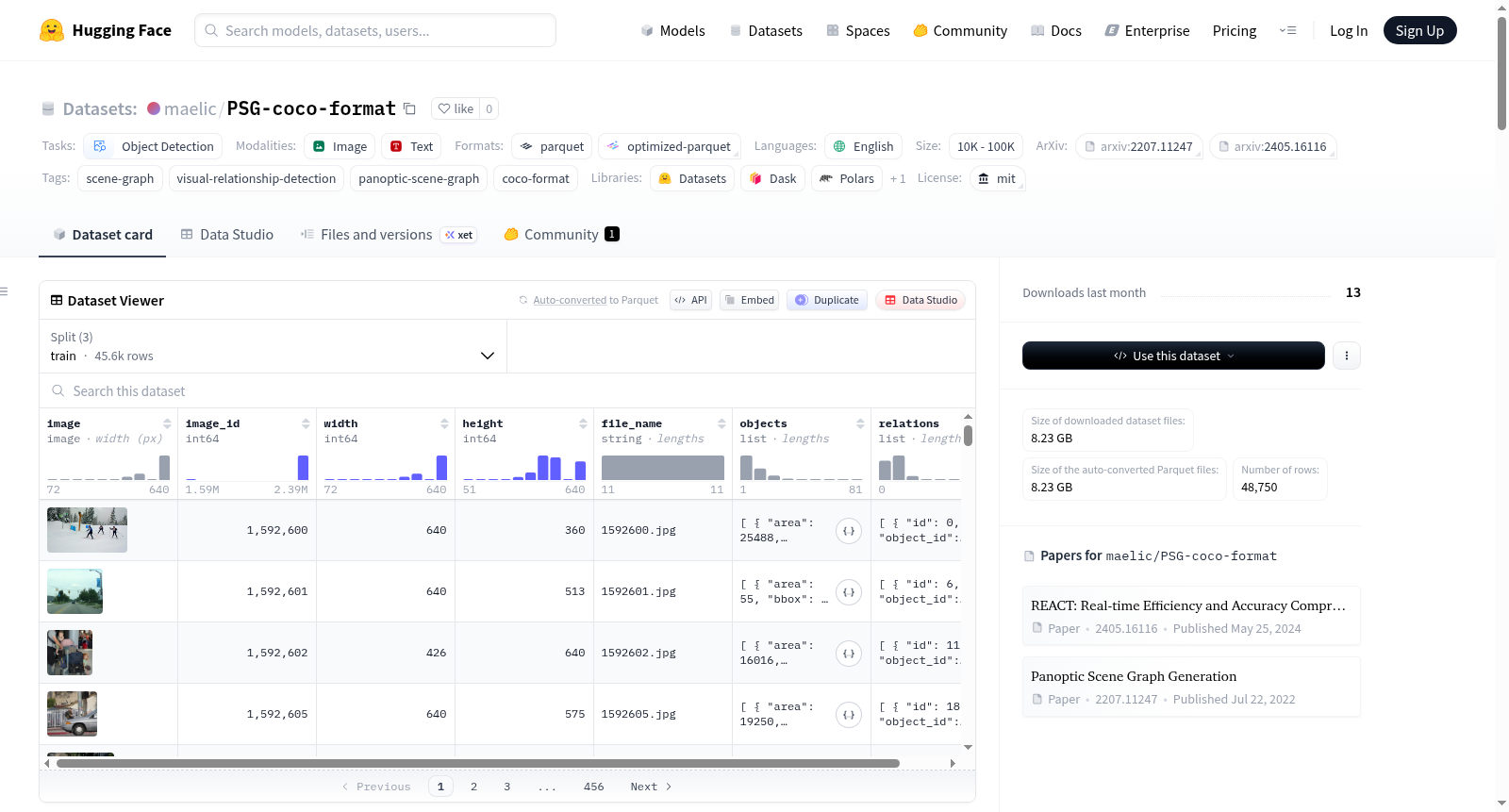
每张图像包含:
- 目标边界框:133个COCO目标类别。
- 场景图关系:56个谓词类别,以有向的
(主语,谓词,宾语)三元组形式连接目标对。
数据集统计
| 数据分割 | 图像数量 | 目标标注数量 | 关系数量 |
|---|---|---|---|
| 训练集 | 45,564 | 494,213 | 254,214 |
| 验证集 | 1,000 | 19,039 | 7,458 |
| 测试集 | 2,186 | 24,910 | 13,705 |
类别信息
- 目标类别(133类):标准的133类COCO全景词汇表(完整列表嵌入在
dataset_info.description中)。 - 谓词类别(56类):包括over、in front of、beside、on、in、attached to、hanging from、on back of、falling off、going down、painted on、walking on、running on、crossing、standing on、lying on、sitting on、flying over、jumping over、jumping from、wearing、holding、carrying、looking at、guiding、kissing、eating、drinking、feeding、biting、catching、picking、playing with、chasing、climbing、cleaning、playing、touching、pushing、pulling、opening、cooking、talking to、throwing、slicing、driving、riding、parked on、driving on、about to hit、kicking、swinging、entering、exiting、enclosing、leaning on。
数据结构
数据集采用DatasetDict结构,包含train、val、test三个分割。每个数据集包含以下特征:image、image_id、width、height、file_name、objects、relations。
每条记录包含的字段:
| 字段名 | 类型 | 描述 |
|---|---|---|
image |
Image |
PIL图像 |
image_id |
int |
原始COCO图像ID |
width / height |
int |
图像尺寸 |
file_name |
str |
原始文件名 |
objects |
List[dict] |
包含id、category_id、bbox (xywh)、area、iscrowd、segmentation的字典列表 |
relations |
List[dict] |
包含id、subject_id、object_id、predicate_id的字典列表,ID指向objects[*].id |
使用示例
python from datasets import load_dataset import json
ds = load_dataset("maelic/PSG-coco-format")
从嵌入的元数据中恢复标签映射
meta = json.loads(ds["train"].info.description) cat_id2name = {c["id"]: c["name"] for c in meta["categories"]} pred_id2name = {c["id"]: c["name"] for c in meta["rel_categories"]}
sample = ds["train"][0] image = sample["image"] # PIL Image for obj in sample["objects"]: print(cat_id2name[obj["category_id"]], obj["bbox"]) for rel in sample["relations"]: print(rel["subject_id"], "--", pred_id2name[rel["predicate_id"]], "->", rel["object_id"])
引用
如果使用此数据集,请引用原始PSG论文: bibtex @inproceedings{yang2022panoptic, title = {Panoptic scene graph generation}, author = {Yang, Jingkang and Ang, Yi Zhe and Guo, Zujin and Zhou, Kaiyang and Zhang, Wayne and Liu, Ziwei}, booktitle = {European conference on computer vision}, pages = {178--196}, year = {2022}, organization = {Springer}, }
如果使用SGG-Benchmark模型,请同时引用REACT论文: bibtex @inproceedings{Neau_2025_BMVC, author = {Ma"elic Neau and Paulo Eduardo Santos and Anne-Gwenn Bosser and Akihiro Sugimoto and Cedric Buche}, title = {REACT: Real-time Efficiency and Accuracy Compromise for Tradeoffs in Scene Graph Generation}, booktitle = {36th British Machine Vision Conference 2025, {BMVC} 2025, Sheffield, UK, November 24-27, 2025}, publisher = {BMVA}, year = {2025}, url = {https://bmva-archive.org.uk/bmvc/2025/assets/papers/Paper_239/paper.pdf}, }
许可证
本数据集继承原始PSG基准的MIT许可证。详情请参阅MIT许可证。