inference-sim-datasets
收藏Hugging Face2025-09-15 更新2025-09-16 收录
下载链接:
https://huggingface.co/datasets/llm-d/inference-sim-datasets
下载链接
链接失效反馈官方服务:
资源简介:
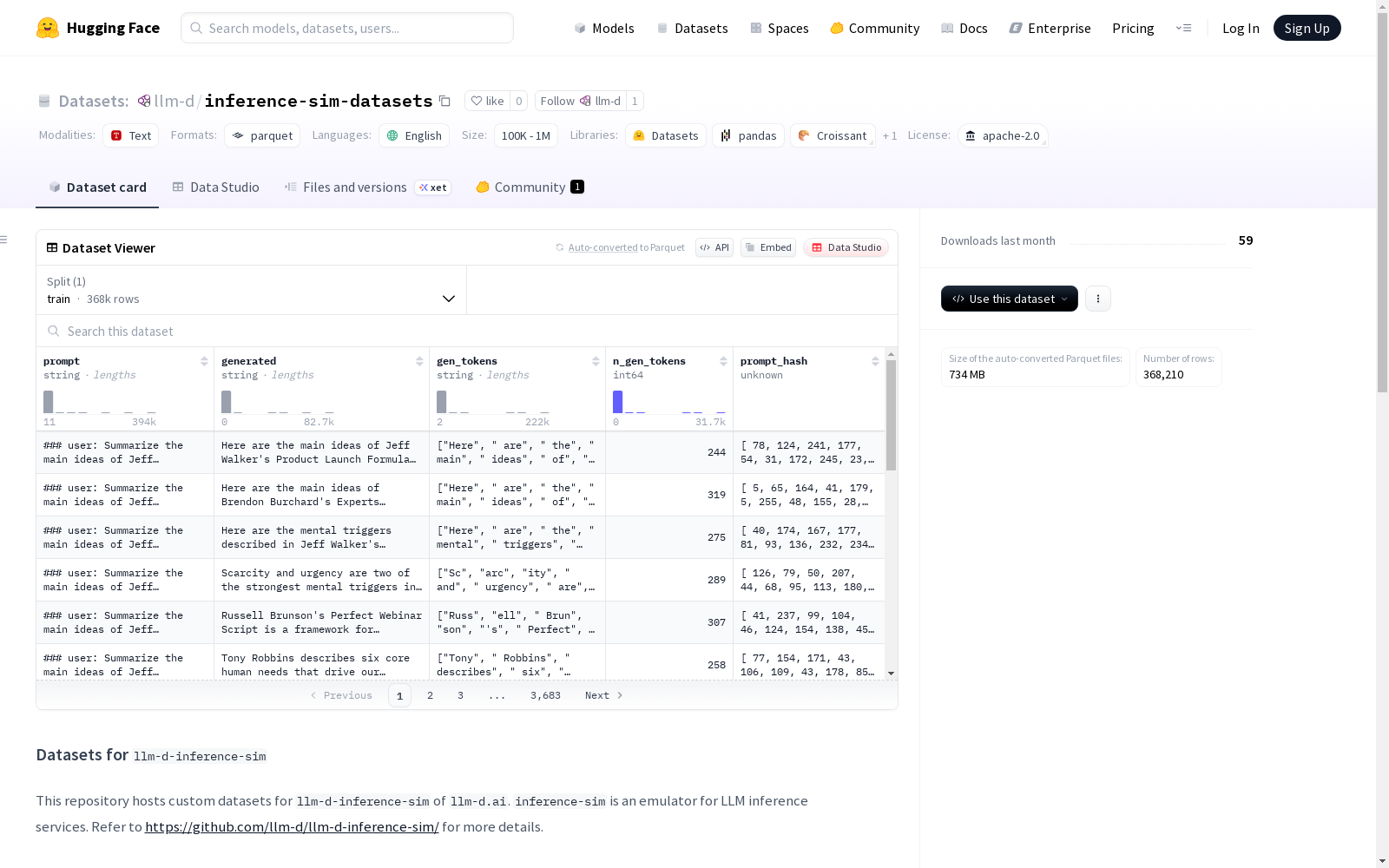
该数据集是针对llm-d.ai的llm-d-inference-sim模块定制的,用于模拟LLM推理服务。数据集包括未经过滤的ShareGPT Vicuna对话数据,以SQLite3数据库文件的形式存在。数据库中包含了一个名为llmd的表,其中包含prompt_hash、gen_tokens和n_gen_tokens三个字段。
This dataset is customized for the llm-d-inference-sim module of llm-d.ai, and is used to simulate LLM inference services. The dataset includes unfiltered ShareGPT Vicuna conversation data, stored in the form of SQLite3 database files. The database contains a table named `llmd` with three fields: prompt_hash, gen_tokens, and n_gen_tokens.
创建时间:
2025-09-13
原始信息汇总
数据集概述
基本信息
- 许可证: Apache 2.0
- 语言: 英语 (en)
数据集用途
该数据集为 llm-d-inference-sim 提供支持,后者是 llm-d.ai 的 LLM 推理服务模拟器。
数据集来源
- 原始数据集:
anon8231489123/ShareGPT_Vicuna_unfiltered - 原始数据集地址: https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered/tree/main
数据处理
-
数据格式转换: 从
ShareGPT_V3_unfiltered_cleaned_split.json创建了 SQLite3 数据库文件。 -
数据库表结构: sql CREATE TABLE llmd ( prompt_hash BLOB PRIMARY KEY, gen_tokens JSON, n_gen_tokens INTEGER );
-
主键生成:
prompt_hash通过 SHA256 哈希生成,源数据为full_prompt。 -
提示词格式: python full_prompt = "" for msg in messages: if msg.role == "human": full_prompt += f"### user: {msg.content} " else: full_prompt += f"### assistant: {msg.content} "
详细信息
更多详情可参考: https://huggingface.co/datasets/llm-d/inference-sim-datasets/tree/980e326f222e3e7390eef9df02a4f5e77d2a6da0/huggingface/ShareGPT_Vicuna_unfiltered
搜集汇总
数据集介绍
构建方式
在大型语言模型推理仿真领域,inference-sim-datasets基于anon8231489123/ShareGPT_Vicuna_unfiltered原始数据集进行重构。通过解析ShareGPT_V3_unfiltered_cleaned_split.json文件,将其转换为结构化的SQLite3数据库。采用SHA256哈希算法对完整对话提示生成唯一标识符作为主键,确保数据条目的唯一性与完整性,每条记录包含生成的令牌序列及其数量,为模型推理过程提供标准化数据支撑。
特点
该数据集显著特点在于其高度结构化的存储形式与可追溯的数据来源。数据库以prompt_hash为主键实现高效检索,完整保留多轮对话中用户与助手角色交替的原始语境。通过规范化处理,既维持了对话数据的自然流畅性,又具备机器学习任务所需的严格数据格式,为LLM推理仿真提供兼具真实性与可操作性的语料资源。
使用方法
研究人员可通过SQLite接口直接访问数据库,利用prompt_hash快速定位特定对话上下文。每条记录中的gen_tokens字段以JSON格式存储生成令牌序列,n_gen_tokens字段提供长度统计,支持推理延迟分析与生成质量评估。该数据集专为llm-d-inference-sim仿真环境设计,可用于模拟不同负载条件下的LLM服务行为,为优化推理系统性能提供实证研究基础。
背景与挑战
背景概述
大型语言模型推理仿真数据集inference-sim-datasets由llm-d.ai研究团队构建,旨在为LLM推理服务仿真器提供高质量的训练与评估数据。该数据集基于经过清洗的ShareGPT对话记录,通过结构化存储和哈希索引技术,为模型推理过程的计算效率优化研究提供数据支撑。其创新性地采用SQLite数据库架构存储对话序列与生成标记的映射关系,推动了分布式推理系统性能评估范式的标准化发展。
当前挑战
该数据集核心解决LLM推理服务中的计算资源分配与延迟优化问题,面临多维度挑战:需精准模拟真实场景中动态对话流的token生成模式,构建过程中需处理海量非结构化对话数据的清洗与标准化,同时保持对话语义完整性与生成序列的可复现性。技术实现上需克服大规模提示词哈希映射的碰撞风险,并确保分布式环境下数据库查询效率与推理仿真的实时性匹配。
常用场景
经典使用场景
在大规模语言模型推理优化研究中,该数据集通过结构化存储真实对话交互记录,为推理过程模拟提供高质量的输入输出序列。研究者利用其包含的多轮对话数据,能够精确模拟不同负载条件下的模型响应行为,为推理延迟和吞吐量分析建立可靠基准。
实际应用
在实际应用层面,该数据集被广泛应用于云原生LLM服务的容量规划与弹性伸缩策略设计。工程团队可基于其构建的负载测试场景,准确评估推理集群在不同查询模式下的性能表现,从而优化硬件资源配置并保障服务等级协议的有效履行。
衍生相关工作
该数据集催生了多项推理优化领域的创新研究,包括基于历史查询模式的预测性调度框架、动态批处理算法改进以及异构硬件适配方案。相关成果已应用于多个开源推理引擎的优化迭代,显著提升了实际部署场景中的资源利用效率。
以上内容由遇见数据集搜集并总结生成


