NeCTIS-Dataset
收藏Hugging Face2025-07-29 更新2025-07-30 收录
下载链接:
https://huggingface.co/datasets/sanganaka/NeCTIS-Dataset
下载链接
链接失效反馈官方服务:
资源简介:
DepNeCTI-LSTM是一个针对梵语的嵌套化合物类型识别数据集,包含领域内散文和领域外诗歌两个子数据集。数据集标注了粗粒度和细粒度的语义类型,粗粒度有四种类型,细粒度有86种子类型。数据集基于Pāṇinian语法和传统注释进行标注,并经过多级别质量检查和验证。
DepNeCTI-LSTM is a dataset dedicated to Sanskrit nested compound type recognition, which comprises two subsets: in-domain prose and out-of-domain poetry. The dataset is annotated with both coarse-grained and fine-grained semantic categories, including four coarse-grained types and 86 fine-grained subtypes. All annotations are conducted based on Pāṇinian grammar and traditional commentaries, and the dataset has undergone multi-level quality checks and validations.
创建时间:
2025-07-27
原始信息汇总
NeCTIS-Dataset 概述
数据集简介
- 目的:用于梵语中的嵌套复合类型识别,特别关注多组分复合词(尤其是超过2个组分的复合词)。
- 包含两种数据集:
- NeCTIS:域内数据(散文)
- NeCTIS-OOD:域外数据(诗歌)
关键特性
- 注释类型:
- 粗粒度:4种复合类型:
- Avyayībhava(不变词)
- Bahuvrīhi(外中心)
- Tatpurusha(内中心)
- Dvandva(并列)
- 细粒度:86种详细子类型
- 粗粒度:4种复合类型:
数据集统计
| 数据集 | 嵌套复合词数量 | 训练集 | 测试集 | 开发集 | 复合类型 |
|---|---|---|---|---|---|
| NeCTIS | 17,656 | 12,431 | 3,493 | 2,405 | 4 (86) |
| NeCTIS-OOD | 1,189 | — | 1,189 | — | 4 (86) |
领域与体裁
- NeCTIS:哲学、文学和阿育吠陀领域 → 散文
- NeCTIS-OOD:史诗文学领域 → 诗歌
注释过程
- 资助:DeitY(2009–2012)作为梵语-印地语机器翻译项目的一部分
- 注释机构:6个机构,每个机构约10名成员,分为3个专业级别:
- 初级语言学家(梵语硕士)
- 高级语言学家(梵语博士)
- 专业语言学家(教授)
- 质量检查:多级质量检查和跨机构验证
- 注释指南:基于帕尼尼语法和传统注释
文件结构
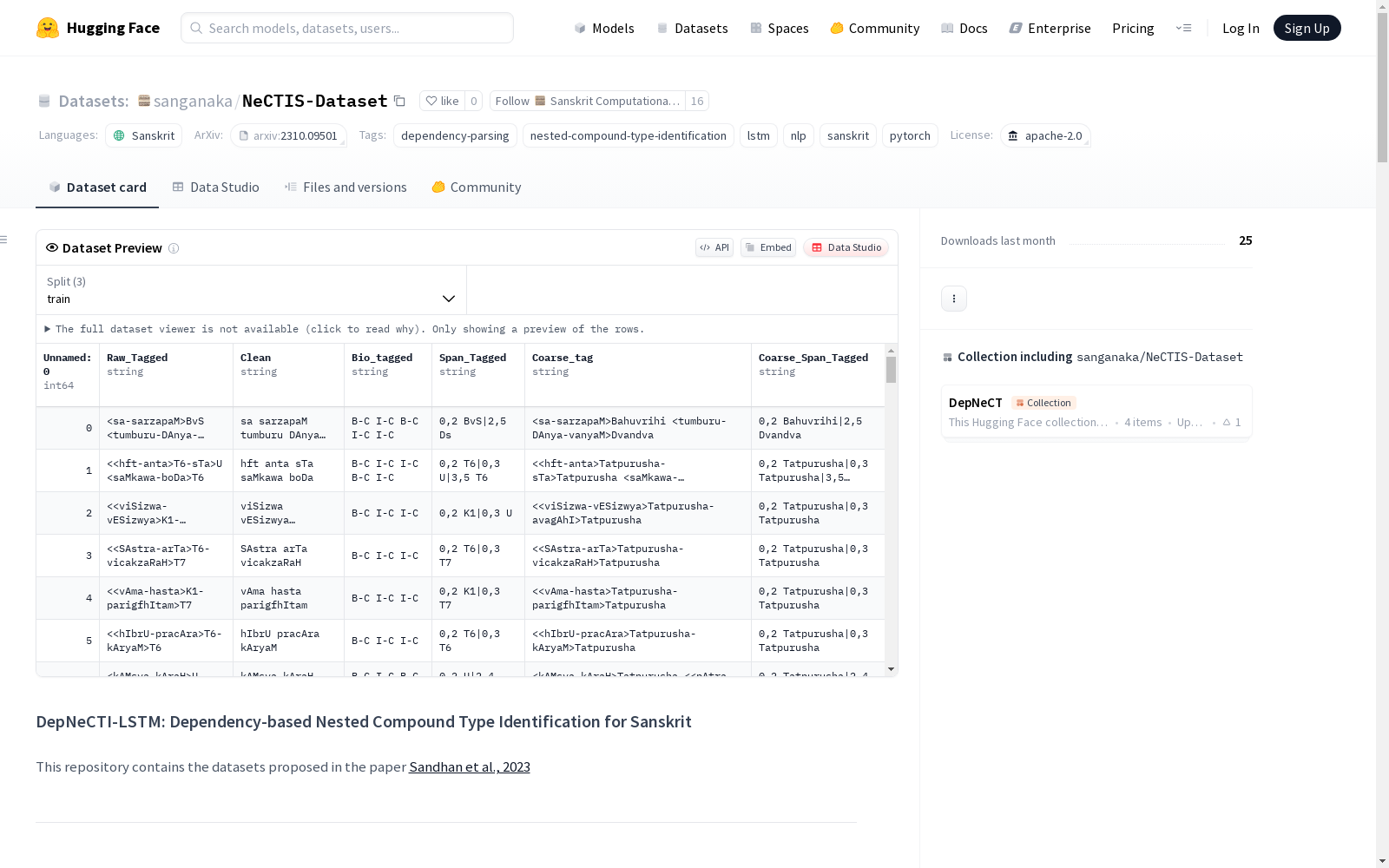
├── No Context CSV files/ │ ├── Combined.csv │ ├── test.csv │ ├── train.csv │ ├── dev.csv │ └── outofDomain.csv ├── With Context CSV files/ │ ├── Combined.csv │ ├── test.csv │ ├── train.csv │ ├── dev.csv │ └── outofDomain.csv
数据集详情
带上下文
- 总行数:15,940行
- 拆分:训练集(69%),测试集(18%),开发集(13%)
- 列说明:
Unnamed: 0:行索引Raw_Tagged:带注释标签的原始文本Clean:清理后的文本Bio_tagged:BIO标记方案Span_Tagged:标记跨度Coarse_tag:粗粒度复合类型Compound_lengths:复合词长度Coarse_Span_Tagged:粗粒度标记跨度Book(仅域外数据集):书籍来源
不带上下文
- 总行数:15,940行
- 列说明:
- 与带上下文数据集相同,但不包含
Compound_lengths列
- 与带上下文数据集相同,但不包含
引用
bibtex @misc{sandhan2023depnecti, title={DepNeCTI: Dependency-based Nested Compound Type Identification for Sanskrit}, author={Jivnesh Sandhan and Yaswanth Narsupalli and Sreevatsa Muppirala and Sriram Krishnan and Pavankumar Satuluri and Amba Kulkarni and Pawan Goyal}, year={2023}, eprint={2310.09501}, archivePrefix={arXiv}, primaryClass={cs.CL} }
原始论文:DepNeCTI: Dependency-based Nested Compound Type Identification for Sanskrit
GitHub仓库:DepNeCTI
搜集汇总
数据集介绍
构建方式
在梵语计算语言学领域,NeCTIS数据集的构建体现了多机构协作的严谨学术范式。该数据集由印度电子信息技术部资助,汇集了六所研究机构的力量,组建了包含初级、高级和专业语言学家三个层级的标注团队。标注过程严格遵循波你尼语法体系和传统注释规范,通过跨机构验证机制确保标注质量。数据集涵盖17,656个嵌套复合词实例,包含散文体(NeCTIS)和诗体(NeCTIS-OOD)两种语料,采用粗粒度(4类)和细粒度(86子类)双重标注体系。
特点
作为梵语复合词研究的专用语料库,NeCTIS数据集展现出鲜明的专业特性。其核心价值在于针对多组分嵌套复合词的结构解析,特别是超过两个组分的复杂构词现象。数据集创新性地采用双重标注维度:粗粒度标注区分四大古典复合词类型(Avyayībhava、Bahuvrīhi、Tatpurusha、Dvandva),细粒度标注则细化至86种语义子类。语料覆盖哲学、文学、阿育吠陀等散文领域,以及富含韵律特征的史诗诗歌,为模型泛化能力评估提供了理想素材。
使用方法
该数据集以CSV格式提供带语境与无语境两种版本,均包含训练集(12,431例)、测试集(3,493例)和开发集(2,405例)。数据字段设计体现多层次语言信息:Raw_Tagged保留原始标注符号,Bio_tagged采用BIO序列标注,Span_Tagged提供词跨度定位,Coarse_Span_Tagged则融合位置与类型信息。研究者可通过分析Compound_lengths字段研究复合词长度分布,利用跨域对比(散文vs诗歌)验证模型鲁棒性。为保持学术规范性,使用时应引用原始论文并遵循Apache-2.0许可协议。
背景与挑战
背景概述
NeCTIS数据集由Sandhan等学者于2023年提出,专注于梵语嵌套复合词类型识别这一核心自然语言处理任务。该数据集由印度电子信息技术部(DeitY)在2009至2012年间资助的梵印机器翻译项目孵化,汇集了六所研究机构的专业语言学团队,采用帕尼尼语法体系进行多层次标注。数据集包含17,656个嵌套复合词实例,涵盖哲学、文学、阿育吠陀等散文领域(NeCTIS)及史诗诗歌领域(NeCTIS-OOD),通过4种粗粒度类型和86种细粒度子类型标注体系,为印欧语系古老语言的形态学分析提供了重要基准。其创新性地区分域内与跨域测试集的设计,显著提升了模型对梵语复杂构词现象的泛化能力评估效度。
当前挑战
该数据集主要面临双重挑战:在学术层面,梵语高度自由的语序和嵌套复合词的递归特性,使得传统基于规则或统计的方法难以准确识别深层语义关系;多组分复合词(超过2个组分)的边界模糊性进一步加剧了类型判定的困难。在构建层面,标注过程需协调不同资历语言学家(从硕士到教授)的认知差异,通过跨机构验证机制确保标注一致性;诗歌体裁中受韵律约束的创新复合词,则对标注指南的完备性提出更高要求。此外,如何平衡粗粒度分类的包容性与细粒度子类型的区分度,成为标注体系设计中的核心矛盾。
常用场景
经典使用场景
在梵语自然语言处理领域,NeCTIS数据集为多组分复合词的嵌套结构识别提供了基准测试平台。该数据集通过散文体和诗歌体两种语料,系统性地捕捉了梵语复合词在哲学文献与史诗文学中的形态差异,其细粒度标注体系支持从传统语法规则到现代机器学习方法的跨范式验证。
解决学术问题
该数据集有效解决了梵语计算语言学中复合词结构歧义解析的难题,其包含的17,656个嵌套复合词实例为基于依赖关系的类型识别模型提供了训练基础。通过建立86种精细子类型的分类体系,填补了传统潘尼尼语法与现代统计学习方法之间的理论鸿沟,显著提升了复杂复合词成分边界的判定准确率。
衍生相关工作
基于该数据集衍生的DepNeCTI-LSTM模型开创了依赖关系与双向LSTM结合的混合架构,相关研究已扩展至其他古典语言处理领域。后续工作如《Sanskrit Compound Processing》等系列论文,进一步探索了注意力机制在多层次复合词解析中的应用,推动了形态复杂语言的计算分析方法革新。
以上内容由遇见数据集搜集并总结生成


