HuRTE
收藏Hugging Face2025-01-17 更新2025-01-18 收录
下载链接:
https://huggingface.co/datasets/NYTK/HuRTE
下载链接
链接失效反馈官方服务:
资源简介:
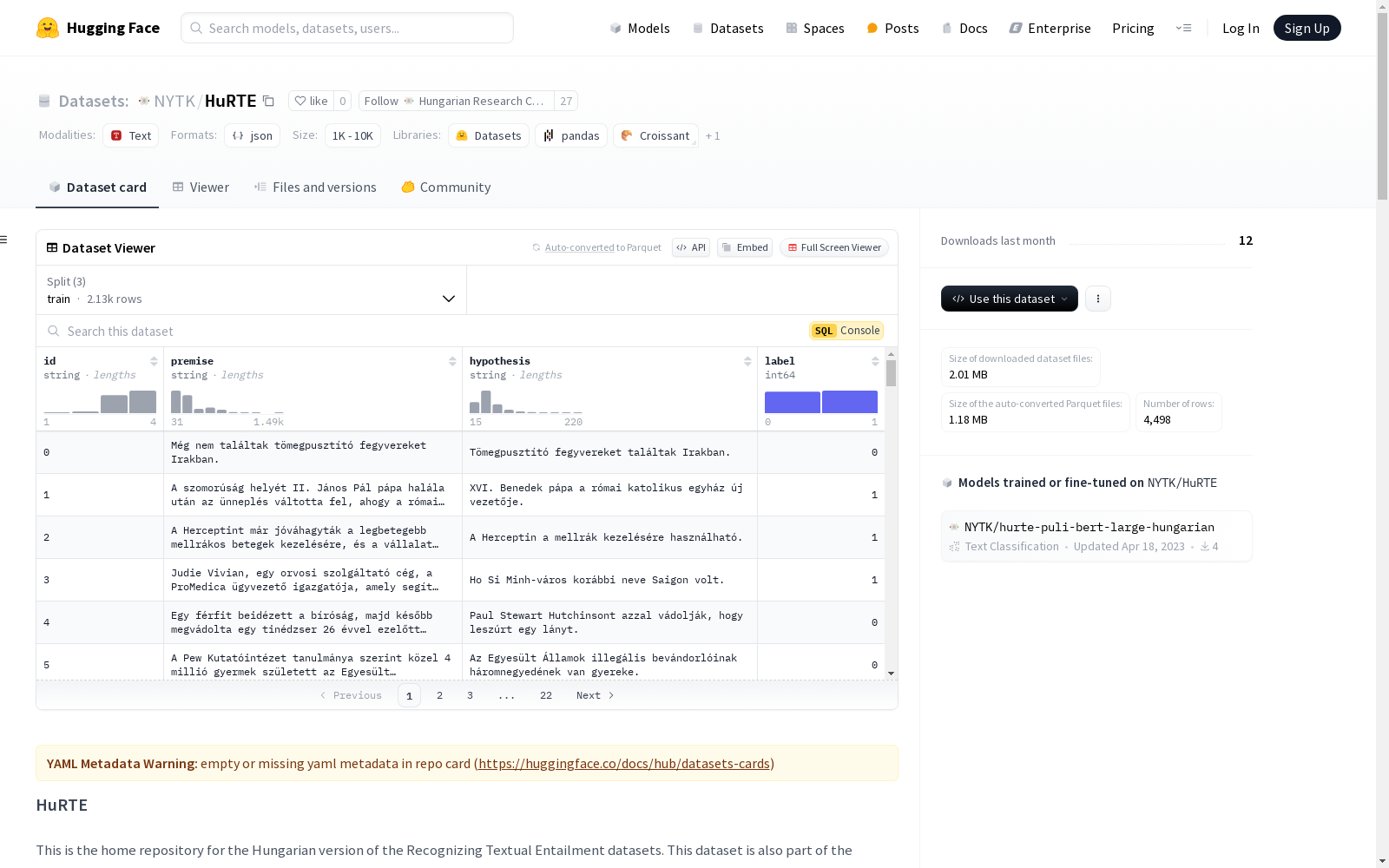
HuRTE数据集是匈牙利语版本的Recognizing Textual Entailment (RTE)数据集,属于匈牙利语言理解评估基准工具包(HuLU)的一部分。该数据集通过翻译和重新注释GLUE基准中的RTE数据集实例创建。数据集包含4,504个实例,每个实例包含一个(有时是多句的)前提和一个单句假设,任务是判断前提是否蕴含假设,属于二分类任务。数据集分为训练集、验证集和测试集,分别包含2,131、242和2,131个实例。测试集不包含标签,评估模型需联系作者或访问HuLU网站。数据格式为JSON,包含id、premise、hypothesis和label四个键。
The HuRTE dataset is the Hungarian version of the Recognizing Textual Entailment (RTE) dataset, which forms part of the Hungarian Language Understanding Evaluation Benchmark Toolkit (HuLU). This dataset was developed by translating and re-annotating the RTE dataset instances from the GLUE benchmark. The dataset contains 4,504 instances in total, each consisting of a (sometimes multi-sentence) premise and a single-sentence hypothesis. The task of this dataset is to determine whether the premise entails the hypothesis, which is a binary classification task. The dataset is split into training, validation and test sets, which hold 2,131, 242 and 2,131 instances respectively. The test set does not include ground-truth labels, and researchers intending to evaluate their models should contact the dataset authors or visit the HuLU official website. The data is formatted as JSON, with four core keys: id, premise, hypothesis and label.
创建时间:
2025-01-14
搜集汇总
数据集介绍
构建方式
HuRTE数据集的构建基于匈牙利语版本的文本蕴含识别任务,其核心数据来源于GLUE基准中的RTE数据集。通过翻译和重新标注这些数据实例,研究团队确保了数据集在匈牙利语语境下的适用性和准确性。数据集包含4,504个实例,每个实例由一个前提和一个假设组成,任务是通过二元分类判断前提是否蕴含假设。训练集、验证集和测试集分别包含2,131、242和2,131个实例,测试集未提供标签,需通过特定渠道获取评估结果。
特点
HuRTE数据集的特点在于其专注于匈牙利语的文本蕴含任务,填补了匈牙利语自然语言处理领域的空白。数据集结构清晰,每个实例包含唯一ID、前提、假设和标签,便于模型训练和评估。其数据格式采用JSON,便于数据处理和集成。此外,数据集作为匈牙利语言理解评估基准工具包(HuLU)的一部分,为匈牙利语的自然语言理解研究提供了重要支持。
使用方法
使用HuRTE数据集时,用户需下载数据文件并加载JSON格式的数据。数据集适用于二元分类任务,用户可通过训练集和验证集进行模型训练和调优。测试集未提供标签,需通过联系数据集维护团队或访问HuLU网站进行自动评估。评估指标为马修斯相关系数(MCC),确保评估结果的科学性和可靠性。用户在使用时需遵循Creative Commons Attribution-ShareAlike 4.0国际许可协议,并在相关研究中引用数据集的相关文献。
背景与挑战
背景概述
HuRTE数据集是匈牙利语版本的文本蕴含识别(Recognizing Textual Entailment, RTE)数据集,隶属于匈牙利语言理解评估基准工具包(HuLU)。该数据集由匈牙利科学院语言研究所的研究团队创建,主要研究人员包括Noémi Ligeti-Nagy等人。数据集的核心研究问题是通过对GLUE基准中的RTE数据集进行翻译和重新标注,构建匈牙利语的文本蕴含识别任务。该任务旨在判断前提(premise)是否蕴含假设(hypothesis),属于二分类问题。HuRTE的创建不仅丰富了匈牙利语的自然语言处理资源,还为匈牙利语的语言理解模型提供了重要的评估基准。
当前挑战
HuRTE数据集面临的挑战主要体现在两个方面。首先,文本蕴含识别任务本身具有较高的复杂性,尤其是在多语言环境下,语言结构和语义表达的差异可能导致模型难以准确捕捉前提与假设之间的逻辑关系。其次,数据集的构建过程中,翻译和重新标注的步骤需要高度的语言学专业知识,以确保匈牙利语版本的准确性和一致性。此外,由于匈牙利语属于低资源语言,数据集的规模相对较小,可能限制了模型的训练效果和泛化能力。这些挑战为研究者提供了进一步优化模型和扩展数据集的方向。
常用场景
经典使用场景
HuRTE数据集在自然语言处理领域中被广泛用于文本蕴含识别任务。该数据集通过提供匈牙利语版本的文本蕴含实例,支持研究人员在匈牙利语环境下进行文本蕴含模型的训练与评估。其经典使用场景包括在匈牙利语自然语言理解基准测试中,作为评估模型性能的重要工具。
衍生相关工作
HuRTE数据集衍生了多项经典研究工作,例如匈牙利语自然语言理解基准测试工具包HuLU的开发。此外,基于该数据集的研究还推动了匈牙利语文本蕴含模型的创新,例如结合预训练语言模型的改进方法,以及多语言文本蕴含任务的跨语言迁移学习研究。
数据集最近研究
最新研究方向
在自然语言处理领域,文本蕴含识别(Recognizing Textual Entailment, RTE)一直是研究热点之一。HuRTE数据集作为匈牙利语版本的RTE数据集,为多语言文本蕴含任务提供了新的研究平台。近年来,随着多语言模型的快速发展,HuRTE数据集在跨语言迁移学习和低资源语言处理中的应用备受关注。研究者们通过该数据集探索了多语言预训练模型在匈牙利语上的表现,并进一步推动了匈牙利语自然语言理解技术的发展。此外,HuRTE数据集还被用于评估模型在低资源语言环境下的泛化能力,为多语言模型的优化提供了重要参考。这些研究不仅丰富了多语言文本蕴含任务的实验数据,也为低资源语言的智能化处理开辟了新的研究方向。
以上内容由遇见数据集搜集并总结生成


