reddit_ds_295492
收藏Hugging Face2025-04-04 更新2025-04-07 收录
下载链接:
https://huggingface.co/datasets/zkpbeats/reddit_ds_295492
下载链接
链接失效反馈官方服务:
资源简介:
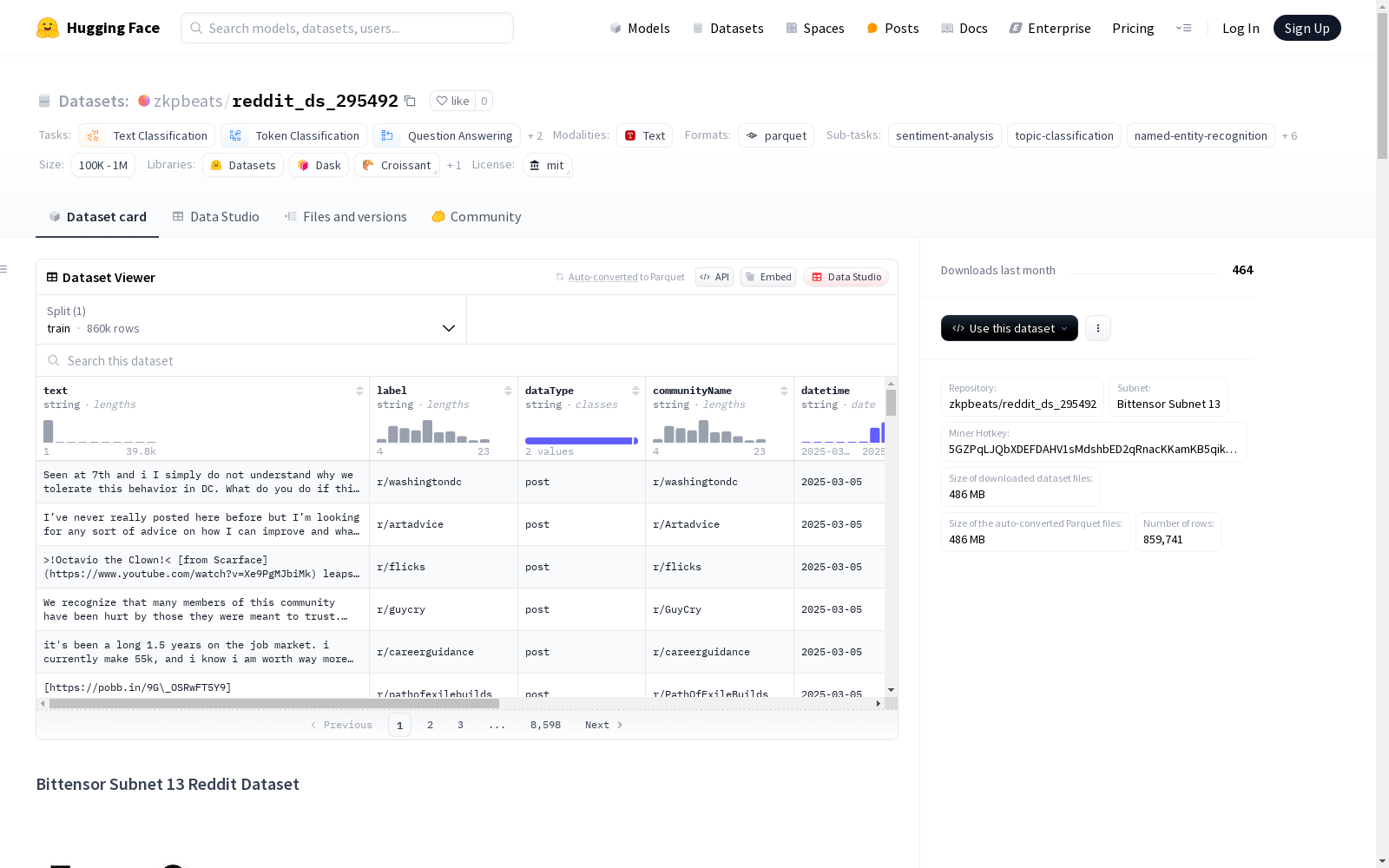
Bittensor Subnet 13 Reddit数据集是一个去中心化网络中的预处理的Reddit数据集,数据由网络矿工持续更新,提供实时的Reddit内容流,适用于各种分析和机器学习任务。数据集支持多种任务,如情感分析、主题建模、社区分析和内容分类等。数据集主要是英文的,但由于创建方式的去中心化,也可能包含多语言内容。每个数据实例代表一个Reddit帖子或评论,包含文本内容、标签、数据类型、社区名称、时间戳、编码后的用户名和URL等字段。数据集不断更新,没有固定的分割,用户应根据数据的时间戳创建自己的分割。数据来源于Reddit的公共帖子和评论,遵守平台的服务条款和API使用指南。所有用户名和URL都经过编码以保护用户隐私。
The Bittensor Subnet 13 Reddit Dataset is a preprocessed Reddit dataset operating on a decentralized network. It is continuously updated by network miners, delivering a real-time stream of Reddit content suitable for diverse analytical and machine learning tasks. The dataset supports multiple downstream tasks including sentiment analysis, topic modeling, community analysis, content classification, and more. While primarily composed of English-language content, it may also include multilingual materials due to the decentralized creation process. Each data instance corresponds to a Reddit post or comment, featuring fields such as text content, labels, data type, community name, timestamp, encoded usernames, and URLs. The dataset undergoes continuous updates without pre-defined data splits, and users are required to construct their own splits based on the timestamps of individual entries. All data is sourced from public Reddit posts and comments, adhering to the platform's Terms of Service and API usage guidelines. All usernames and URLs within the dataset have been encoded to safeguard user privacy.
创建时间:
2025-04-03
搜集汇总
数据集介绍
构建方式
在社交媒体分析领域,reddit_ds_295492数据集通过Bittensor Subnet 13去中心化网络构建,采用实时更新的方式采集Reddit公开帖文与评论数据。数据采集严格遵循平台服务条款与API使用规范,通过分布式矿工节点持续抓取并预处理,确保数据流的时效性与多样性。原始文本经过标准化处理,用户名及URL信息采用加密编码以保护用户隐私,形成包含文本内容、情感标签、社区分类等结构化字段的数据集合。
特点
该数据集展现出鲜明的动态社交媒体特征,覆盖50803条以英文为主的多语言实例,其中评论占比高达98.14%,精准捕捉了Reddit平台实时互动特性。数据维度设计科学,不仅包含基础文本内容,还整合了社区归属、时间戳及加密用户信息等元数据,支持从情感分析到话题建模等多元任务。值得注意的是,数据分布呈现典型的长尾效应,头部社区如r/television占比8.82%,为研究网络群体行为提供了丰富样本。
使用方法
研究者可通过HuggingFace平台直接加载该数据集,建议按时间戳划分训练验证集以应对数据流特性。针对不同任务场景,可利用text字段进行文本生成建模,结合label字段实现细粒度分类,或通过communityName字段开展跨社区对比研究。使用时应建立动态评估机制以应对数据更新,并注意通过消融实验控制社交平台固有偏差的影响。对于时序敏感研究,可利用datetime字段构建时间序列分析模型,充分挖掘社交媒体数据的演化规律。
背景与挑战
背景概述
reddit_ds_295492数据集由Bittensor Subnet 13去中心化网络于2025年构建,旨在提供实时更新的Reddit社交媒体数据流,以支持多样化的自然语言处理任务。该数据集由zkpbeats团队主导开发,作为宏宇宙数据生态系统的一部分,其核心研究问题聚焦于社交媒体动态分析、用户行为建模及内容语义理解。通过整合Reddit公开的帖子和评论数据,该数据集为情感分析、主题建模、社区分析等任务提供了丰富的研究素材,对社交计算和计算社会科学领域具有显著的推动作用。
当前挑战
该数据集在解决社交媒体内容分析的领域问题时,面临诸多挑战。首先,Reddit数据的多样性和动态性导致内容质量参差不齐,存在大量噪声和无关信息,增加了模型训练的复杂度。其次,社交媒体平台固有的偏见和用户群体的局限性可能影响数据的代表性,进而导致分析结果的偏差。在构建过程中,数据采集需严格遵守Reddit的API使用条款,同时需通过编码技术保护用户隐私,这对数据预处理流程提出了较高要求。此外,实时更新的特性使得数据分布随时间变化,可能引入时间维度上的不一致性,对模型的泛化能力构成挑战。
常用场景
经典使用场景
在社交媒体分析领域,reddit_ds_295492数据集以其丰富的文本内容和结构化字段成为研究网络社区行为的理想选择。该数据集最经典的使用场景包括情感分析和主题建模,研究人员能够通过分析Reddit帖子和评论中的文本内容,揭示用户情感倾向和话题分布规律。其多语言特性和实时更新机制,为跨文化比较和动态趋势追踪提供了独特优势。
解决学术问题
该数据集有效解决了社交媒体研究中数据时效性和多样性的关键问题。通过提供编码处理的用户隐私信息,它在满足研究需求的同时遵守了数据伦理规范。其标注的文本分类字段为自然语言处理领域的监督学习任务提供了可靠数据源,特别是在细粒度情感分析和多标签分类等前沿课题上展现出重要价值。
衍生相关工作
围绕该数据集已产生多项重要研究成果,包括基于注意力机制的情感分类模型和跨社区传播动力学分析。部分团队将其与Twitter数据集进行对比研究,探索不同社交平台的话语特征差异。在去中心化网络研究领域,该数据集作为Bittensor子网的典型应用案例,推动了分布式数据采集方法的创新。
以上内容由遇见数据集搜集并总结生成


