Cantonese-Radio-Description-Instructions
收藏Hugging Face2025-06-08 更新2025-06-09 收录
下载链接:
https://huggingface.co/datasets/mesolitica/Cantonese-Radio-Description-Instructions
下载链接
链接失效反馈官方服务:
资源简介:
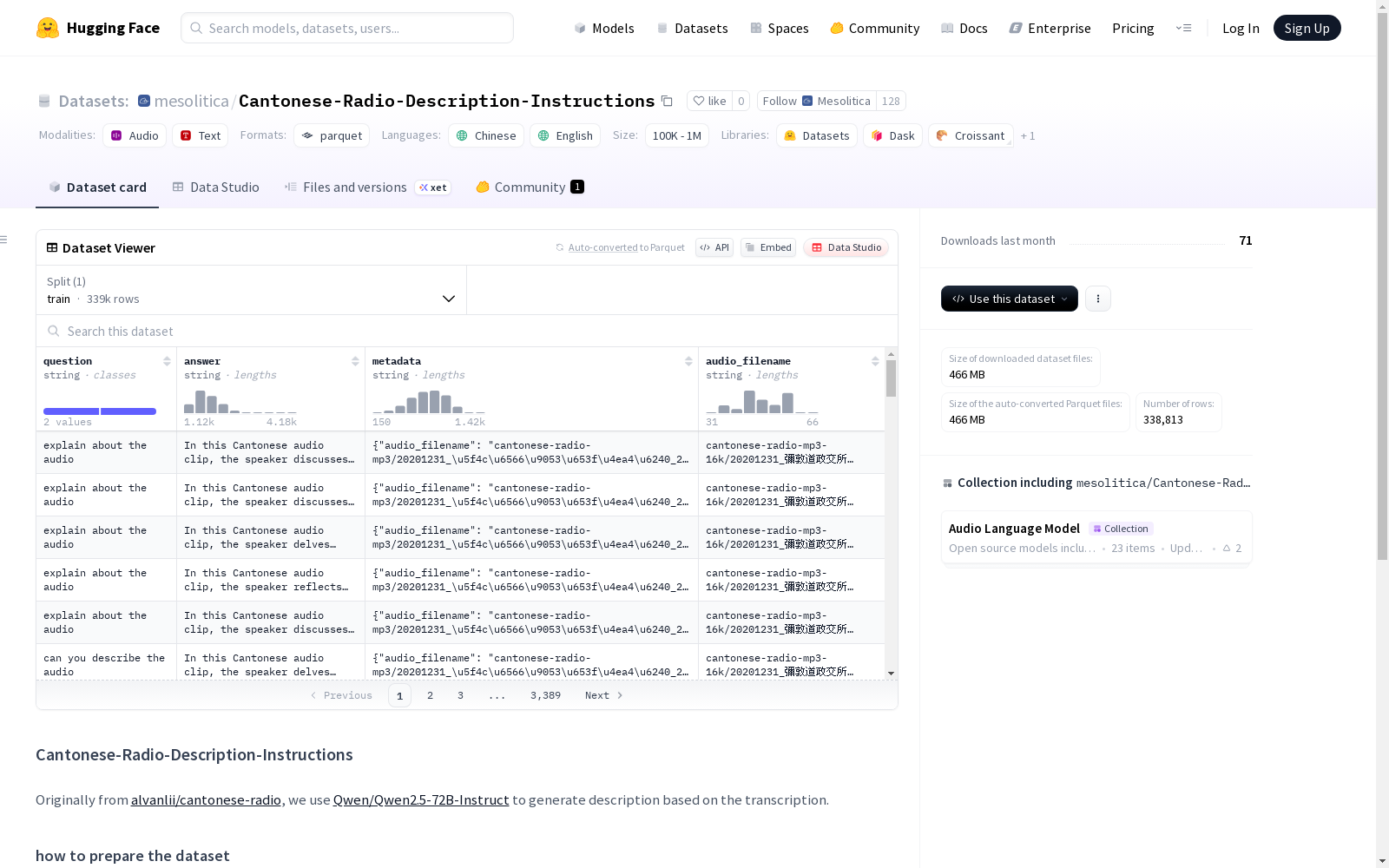
这是一个包含问题、答案、元数据和音频文件名的 Cantonese-Radio 数据集,用于训练和测试语言模型。数据集由训练集组成,共有338813个示例,适用于粤语语音识别和文本生成任务。
This is a Cantonese-Radio dataset containing questions, answers, metadata, and audio filenames, which is designed for training and testing language models. This dataset is a training set comprising 338,813 examples, and is applicable to Cantonese speech recognition and text generation tasks.
提供机构:
Mesolitica
创建时间:
2025-06-07
搜集汇总
数据集介绍
构建方式
在粤语广播数据处理领域,该数据集源自alvanlii/cantonese-radio原始语料,通过采用Qwen2.5-72B-Instruct大模型对转录文本进行智能化描述生成。构建过程中充分保留了音频文件名与元数据的对应关系,形成了包含33万余条样本的大规模训练集,每条数据均包含问题、回答、元数据及音频文件名的完整映射体系。
使用方法
使用者可通过huggingface-cli工具直接下载数据集压缩包,配合定制Python解压脚本完成数据预处理。该数据集适用于粤语语音识别、音频描述生成及多模态指令微调任务,可加载至深度学习框架中训练端到端的语音-文本转换模型,或作为粤语对话系统的训练基底。
背景与挑战
背景概述
粤语广播描述指令数据集源于alvanlii团队构建的粤语广播语料库,由Mesolitica研究机构通过Qwen2.5-72B-Instruct大模型对原始转录文本进行智能化描述生成。该数据集聚焦于低资源方言的语义理解与生成任务,通过结合音频文件与多模态文本标注,为粤语自然语言处理研究提供了大规模高质量的指令微调数据,显著推动了方言计算语言学的发展。
当前挑战
该数据集核心解决粤语语音识别与语义解析的双重挑战,包括方言音系特征建模、口语化表达歧义消解以及跨模态对齐问题。构建过程中需克服音频转录噪声干扰、方言语法规则数字化缺失以及大模型生成内容的一致性验证等难点,同时需平衡语言真实性指令与机器学习可用性之间的张力。
常用场景
经典使用场景
在粤语语音理解与生成的研究领域中,Cantonese-Radio-Description-Instructions数据集通过结合音频转录与智能生成的描述文本,为语音到文本的跨模态学习提供了重要支撑。该数据集广泛应用于训练和评估语音识别模型,特别是在处理粤语这种方言变体时,能够有效提升模型对口语化表达和地域性语言特征的理解能力。
解决学术问题
该数据集显著解决了低资源语言处理中的标注数据稀缺问题,为粤语自然语言处理研究提供了大规模、高质量的训练样本。其意义在于推动了方言保护与人工智能技术的结合,促进了多语言模型在语音识别、语义理解等任务中的性能提升,对语言技术公平性与包容性发展具有深远影响。
实际应用
在实际应用中,该数据集可用于构建智能语音助手、粤语广播内容自动摘要系统以及方言教育工具。例如,在媒体行业,能够实现粤语节目的实时字幕生成与内容检索;在文化保护领域,可为粤语口语资料的数字化存档与检索提供技术基础,增强语言资源的可利用性。
数据集最近研究
最新研究方向
随着粤港澳大湾区语言资源保护需求的日益凸显,粤语语音理解数据集成为方言计算语言学的前沿焦点。Cantonese-Radio-Description-Instructions数据集通过大语言模型生成高质量音频描述指令,为低资源方言的语音-文本跨模态学习提供了关键支撑。当前研究集中于构建粤语语音指令跟随系统,结合端到端语音识别与语义理解技术,推动方言媒体内容智能化处理。该数据集助力突破方言与通用语言间的技术壁垒,对文化遗产数字化保存及多语言语音助手本土化应用具有深远意义。
以上内容由遇见数据集搜集并总结生成


