IVY-FAKE
收藏github2025-06-15 更新2025-07-01 收录
下载链接:
https://github.com/Pi3AI/Ivy-Fake
下载链接
链接失效反馈官方服务:
资源简介:
IVY-FAKE是第一个为多模态可解释AIGC检测设计的大规模数据集,包含150K+训练样本(图像+视频)、18.7K评估样本,以及细粒度注释,包括空间和时间伪影分析、自然语言推理和带有解释的二进制标签。
IVY-FAKE is the first large-scale dataset designed for multimodal explainable AIGC detection. It comprises over 150K training samples (image + video) and 18.7K evaluation samples, along with fine-grained annotations including spatial and temporal artifact analysis, natural language inference, and binary labels with explanations.
创建时间:
2025-06-02
原始信息汇总
IVY-FAKE数据集概述
数据集基本信息
- 名称: IVY-FAKE
- 类型: 多模态可解释AIGC检测基准数据集
- 规模:
- 训练样本: 150K+ (图像+视频)
- 评估样本: 18.7K
- 许可证: CC BY-SA 4.0
核心特点
- 首个大规模多模态可解释AIGC检测数据集
- 细粒度标注:
- 空间和时间伪影分析
- 自然语言推理(<think>...</think>)
- 带解释的二元标签(<conclusion>real/fake</conclusion>)
关联模型
- IVY-xDETECTOR:
- 视觉语言检测模型
- 功能:
- 识别图像/视频中的合成伪影
- 生成逐步推理
- 在多个基准测试中达到SOTA性能
评估方法
- 环境要求:
- Python 3.10
- 依赖项见requirements.txt
- 评估脚本:
- 测试LLM在基于推理的AIGC检测上的性能
- 需要设置OPENAI_API_KEY和OPENAI_BASE_URL环境变量
- 输入格式:
- JSON数组,包含:
- rel_path: 文件相对路径
- label: 真实/伪造标签
- raw_ground_truth: 原始推理过程
- infer_result: 模型推理结果
- JSON数组,包含:
相关资源
- 论文: https://arxiv.org/abs/2506.00979
- Hugging Face数据集: https://huggingface.co/datasets/AI-Safeguard/Ivy-Fake
- GitHub代码: https://github.com/Pi3AI/Ivy-Fake
搜集汇总
数据集介绍
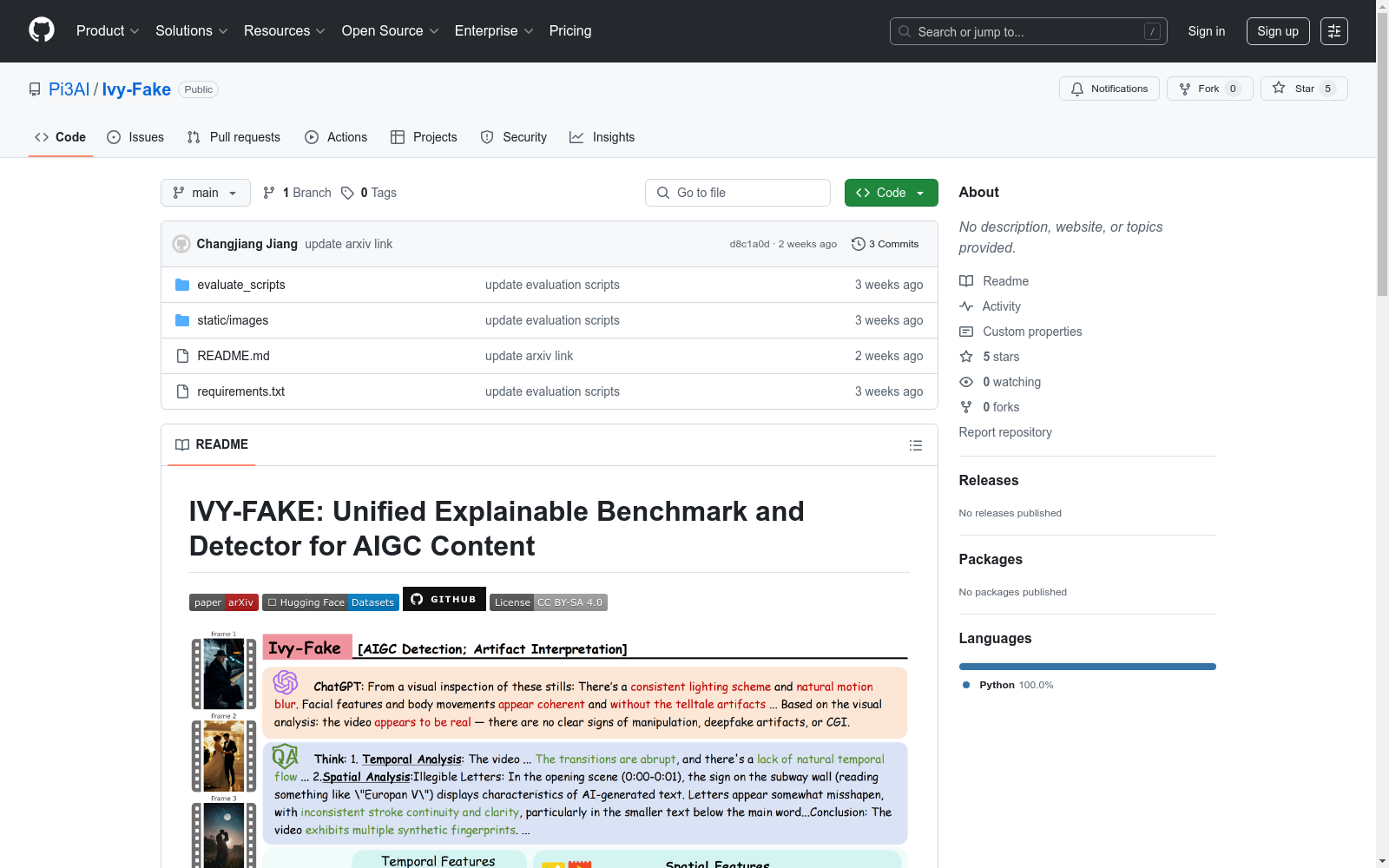
构建方式
在人工智能生成内容检测领域,IVY-FAKE数据集通过系统化的数据采集与标注流程构建而成。研究团队整合了超过15万份多模态训练样本,涵盖图像与视频两种媒介形式,并创新性地采用细粒度标注体系,包括空间伪影分析、时序异常检测以及自然语言推理标注。每个样本均配备二元分类标签及对应的解释性文本,标注过程融合了计算机视觉专家与语言学家的双重校验机制,确保数据质量的可靠性。
特点
作为首个面向可解释性AIGC检测的大规模多模态基准,IVY-FAKE展现出三大核心特征:其跨模态特性支持图像与视频内容的联合分析,突破传统单模态检测的局限;内置的思维链标注体系为模型决策提供可追溯的逻辑依据,包含<think>推理过程</think>与<conclusion>最终结论</conclusion>的结构化表达;数据分布覆盖主流生成模型的输出特征,包含18.7K经人工验证的评估样本,为检测算法的泛化能力提供严谨测试环境。
使用方法
使用者可通过Hugging Face平台直接加载数据集,或参照GitHub仓库的配置指南建立Python3.10虚拟环境。评估阶段需预先设置OPENAI_API_KEY等环境变量,运行eva_scripts.py脚本时将自动比对模型预测与标注真值,输出包含错误分析的JSON日志。输入数据需严格遵循特定格式,要求每个样本提供相对路径、真实标签及完整的推理链,其中infer_result字段需包含待评估模型的自解释性输出,系统将自动计算检测准确率与推理一致性等核心指标。
背景与挑战
背景概述
IVY-FAKE数据集由Pi3AI团队于2024年发布,是首个专注于多模态可解释性AI生成内容检测的大规模基准数据集。该数据集旨在应对生成式人工智能技术快速发展带来的内容真实性验证挑战,其核心研究问题聚焦于跨图像和视频模态的合成内容检测与解释。作为领域内首个同时包含空间-时间伪影分析和自然语言推理标注的资源,IVY-FAKE通过15万训练样本和1.87万评估样本,为可解释性检测模型提供了细粒度的学习框架,显著推动了数字内容鉴伪领域的标准化进程。
当前挑战
该数据集主要解决AI生成内容检测领域存在的两大挑战:跨模态统一检测框架的缺失,以及传统二分类方法缺乏可解释性决策依据。在构建过程中,研究团队面临多模态数据对齐的复杂性,需要协调图像空间伪影与视频时序伪影的特征表征;同时细粒度标注体系的建立耗费大量人工成本,特别是自然语言推理部分需确保逻辑一致性。此外,动态演进的生成技术导致数据集需要持续更新以维持检测有效性,这对基准的长期维护提出严峻考验。
常用场景
经典使用场景
在人工智能生成内容(AIGC)检测领域,IVY-FAKE数据集作为首个大规模多模态可解释基准,为研究者提供了丰富的图像和视频样本。该数据集通过细粒度标注和时空伪影分析,成为训练和评估检测模型的黄金标准,尤其在跨模态一致性验证和生成痕迹识别方面展现出独特价值。其自然语言推理标签体系为理解模型决策过程提供了透明化路径,推动了可解释AI在内容鉴伪方向的发展。
实际应用
该数据集在数字内容安全领域具有广泛落地场景,包括社交媒体虚假信息过滤、影视版权溯源认证、金融身份验证防伪等关键场景。基于IVY-FAKE训练的IVY-xDETECTOR模型已展现出实际应用潜力,能够自动识别深度伪造视频中的面部微表情异常,检测AI生成图像的频域不一致特征,并为执法机构提供符合司法证据要求的可解释检测报告。在OpenAI等企业的内容审核系统中,此类技术正逐步实现工业化部署。
衍生相关工作
IVY-FAKE的发布催生了多个重要研究方向,包括基于多模态对比学习的生成检测框架xDETECTOR、结合大语言模型的可解释推理系统TruthTracer等。其数据标注范式被后续研究如GenForgeryBenchmark广泛借鉴,时空伪影分析模块更成为CVPR 2023最佳论文ArtifactSleuth的核心组件。该数据集支撑的研究成果已在IEEE TPAMI等顶刊形成专题论文集,推动形成了AIGC安全检测的学术共同体。
以上内容由遇见数据集搜集并总结生成


