Everything_Instruct_Multilingual
收藏Hugging Face2024-10-09 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/rombodawg/Everything_Instruct_Multilingual
下载链接
链接失效反馈官方服务:
资源简介:
Everything Instruct (多语言版) 是一个庞大的alpaca指令格式数据集,包含广泛的主题,旨在将开源AI模型提升到一个新的水平。该数据集完全未经过滤,支持多种语言,包括英语、俄语、中文、韩语、乌尔都语、拉丁语、阿拉伯语、德语、西班牙语、法语、印地语、意大利语、日语、荷兰语和葡萄牙语。数据集涵盖科学、社交媒体、常识、烹饪、写作、医学、历史、法律、角色扮演、新闻、编码、数学、函数调用和一般指令等多个类别。
Everything Instruct (Multilingual Version) is a large-scale Alpaca-style instruction dataset that covers a wide range of topics, designed to advance open-source AI models to a new level. This dataset is fully unfiltered and supports multiple languages, including English, Russian, Chinese, Korean, Urdu, Latin, Arabic, German, Spanish, French, Hindi, Italian, Japanese, Dutch, and Portuguese. It covers various categories such as science, social media, common sense, cooking, writing, medicine, history, law, role-playing, news, coding, mathematics, function calling, and general instruction.
创建时间:
2024-10-09
原始信息汇总
Everything Instruct (Multilingual Edition)
概述
- 数据集名称: Everything Instruct (Multilingual Edition)
- 许可证: Apache 2.0
- 语言:
- 英语
- 俄语
- 中文
- 韩语
- 乌尔都语
- 拉丁语
- 阿拉伯语
- 德语
- 西班牙语
- 法语
- 印地语
- 意大利语
- 日语
- 荷兰语
- 葡萄牙语
- 标签:
- Num_Rows = 7,799,967
- Max_length = 8180
数据集特点
- 科学: 12,580 行
- 社交媒体: 18,405 行
- 常识: 906,346 行
- 多语言: 2,937,785 行
- 烹饪: 20,763 行
- 写作: 414,646 行
- 医学: 36,738 行
- 历史: 10,178 行
- 法律: 90,394 行
- 角色扮演: 433,205 行
- 新闻: 124,542 行
- 编程: 2,872,975 行
- 数学: 262,039 行
- 函数调用: 112,960 行
- 通用指令: 998,854 行
数据来源
科学
- antiven0m/physical-reasoning-dpoScience
- LawalAfeez/science-dataset
社交媒体
- Kyle1668/AG-Tweets
- euclaise/reddit-instruct-curated
常识
- NousResearch/CharacterCodex_Characters
- jstet/quotes-500k_Famous_Quotes
- FronkonGames/steam-games-dataset_Video_Games
- totuta_youtube_subs_howto100M_HowTo
多语言
- Amani27/massive_translation_dataset
- udmurtNLP/udmurt-russian-english-labse
- grosenthal/latin_english
- msarmi9/korean-english-multitarget-ted-talks-task
- HaiderSultanArc/MT-Urdu-English_Translate
- Garsa3112/ChineseEnglishTranslationDataset
烹饪
- andrewsiah/se_cooking_preference_sft
- Hieu-Phamkaggle/food_recipes
写作
- shahules786/PoetryFoundationData
- euclaise/writingprompts
- qwedsacf/ivypanda-essaysEssay
医学
- keivalya/MedQuad-MedicalQnADataset
- nuvocare/MSD
历史
- ambrosfitz10k/history_data_v4
法律
- dzunggg/legal-qa-v1
角色扮演
- roleplay4/fun_CoupleRP
- Undi95andrijdavid/roleplay-conversation-sharegpt
新闻
- RealTimeData/bbc_news_alltime
编程
- layoric/tiny-codes-alpaca
- glaiveai/glaive-code-assistant-v3
- ajibawa-2023/Code-290k-ShareGPT
- chargoddard/commitpack-ft-instruct-rated
- iamtarun/code_instructions_120k_alpaca
- ise-uiuc/Magicoder-Evol-Instruct-110K
- cognitivecomputations/dolphin-coder
- nickrosh/Evol-Instruct-Code-80k-v1
- coseal/CodeUltraFeedback_binarized
- CyberNative/Code_Vulnerability_Security_DPO
数学
- TIGER-Lab/MathInstruct
函数调用
- glaiveai/glaive-function-calling-v2
通用指令
- teknium/OpenHermes-2.5
搜集汇总
数据集介绍
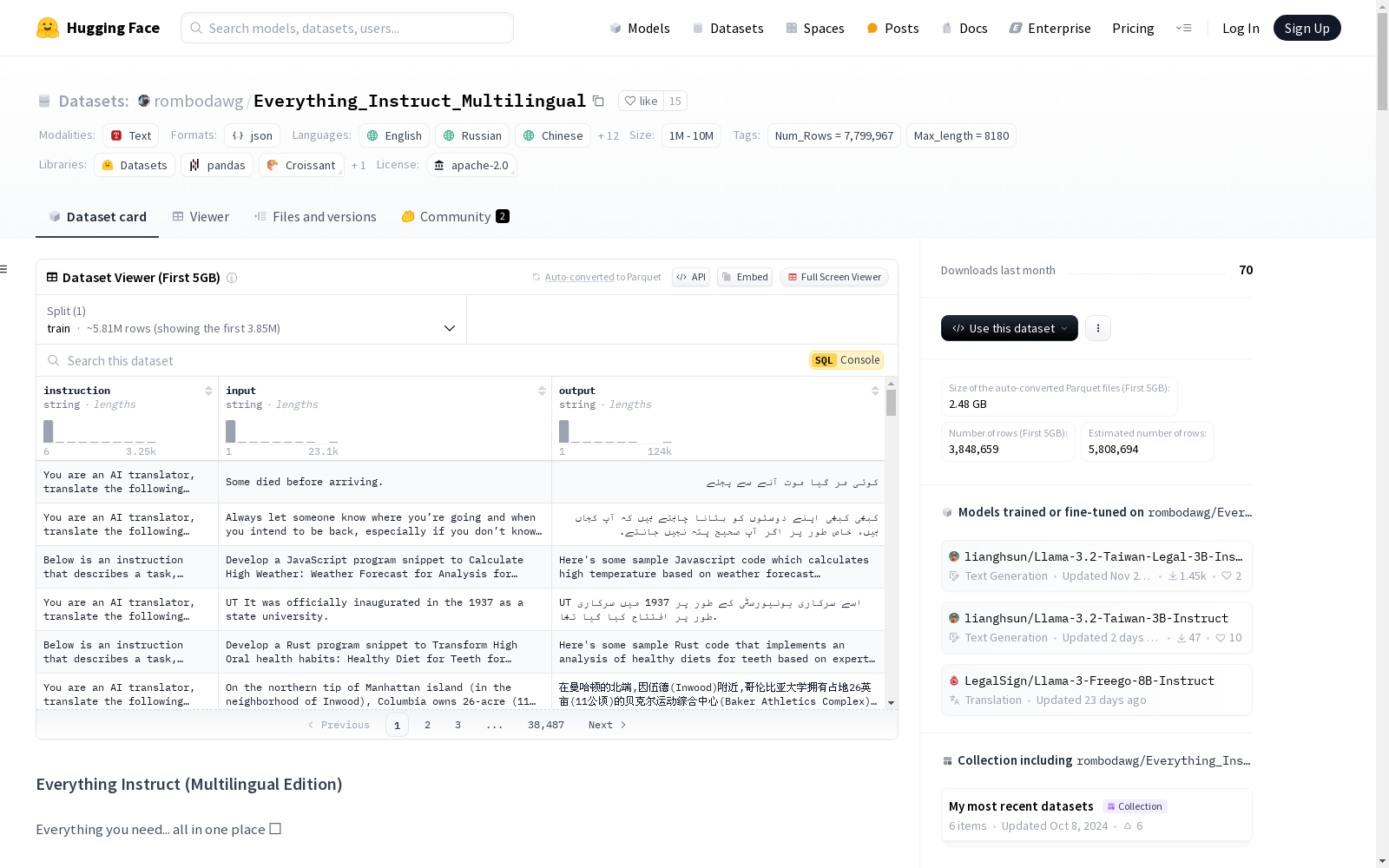
构建方式
Everything_Instruct_Multilingual数据集的构建基于多源数据整合,涵盖了科学、社交媒体、通用知识、多语言、烹饪、写作、医学、历史、法律、角色扮演、新闻、编程、数学、函数调用及通用指令等多个领域。数据来源包括公开的学术数据集、社交媒体内容、通用知识库及特定领域的专业数据集,确保了数据的多样性和广泛性。数据集采用Alpaca指令格式,旨在提升开源AI模型的多语言处理能力。
特点
该数据集的最大特点在于其多语言支持,涵盖了英语、俄语、中文、韩语、乌尔都语、拉丁语、阿拉伯语、德语、西班牙语、法语、印地语、意大利语、日语、荷兰语和葡萄牙语等15种语言。数据集规模庞大,包含7,799,967行数据,最大长度为8180字符。其内容覆盖广泛,从科学、编程到角色扮演,几乎涵盖了所有常见领域,且数据未经审查,适合用于训练无限制的AI模型。
使用方法
Everything_Instruct_Multilingual数据集适用于多语言AI模型的微调和训练,特别是在提升模型的多语言理解和生成能力方面具有显著优势。用户可以通过HuggingFace平台直接加载数据集,结合开源AI框架如Transformers进行模型训练。数据集的多领域覆盖使其能够广泛应用于自然语言处理任务,如文本生成、翻译、问答系统等。建议用户根据具体任务需求,选择相关领域的数据进行针对性训练,以最大化模型性能。
背景与挑战
背景概述
Everything_Instruct_Multilingual数据集是一个多语言指令数据集,旨在通过涵盖广泛的主题来提升开源人工智能模型的性能。该数据集由多个领域的子集构成,包括科学、社交媒体、通用知识、多语言内容、烹饪、写作、医学、历史、法律、角色扮演、新闻、编程、数学和函数调用等。数据集的创建时间未明确提及,但其内容来源广泛,涵盖了多个知名数据集和开源项目,如NousResearch、GlaiveAI、TIGER-Lab等。该数据集的核心研究问题在于如何通过多语言、多领域的指令数据,提升大型语言模型(LLMs)的泛化能力和跨领域适应性。其对开源AI社区的影响力显著,尤其是在推动开放与封闭源代码模型之间的界限方面。
当前挑战
Everything_Instruct_Multilingual数据集面临的挑战主要集中在两个方面。首先,数据集的多样性和规模带来了模型训练的复杂性。由于数据集涵盖了15种语言和多个领域,模型需要具备强大的多语言处理能力和跨领域知识迁移能力,这对模型的架构和训练策略提出了更高的要求。其次,数据集的构建过程中,如何确保数据的质量、一致性和平衡性是一个重要挑战。不同来源的数据可能存在格式、语言风格和内容深度的差异,如何有效整合这些数据并避免偏见和噪声的引入,是数据集构建中的关键问题。此外,数据集的完全无审查性质可能导致模型在生成内容时产生不符合伦理或法律要求的输出,这也为模型的后续对齐和优化带来了额外的挑战。
常用场景
经典使用场景
Everything_Instruct_Multilingual数据集广泛应用于多语言大语言模型(LLM)的训练与优化。其丰富的多语言指令数据涵盖了科学、社交媒体、通用知识、烹饪、写作、医学、历史、法律、角色扮演、新闻、编程、数学和函数调用等多个领域,为模型提供了多样化的训练素材。通过该数据集,研究人员能够构建出在多语言环境下表现卓越的AI模型,显著提升模型的理解与生成能力。
衍生相关工作
基于Everything_Instruct_Multilingual数据集,许多经典研究工作得以展开。例如,研究人员利用该数据集开发了多语言指令微调模型,显著提升了模型在多语言任务中的表现。此外,该数据集还被用于研究无审查模型的行为特性,推动了开放源AI模型在伦理与安全性方面的研究进展。
数据集最近研究
最新研究方向
在自然语言处理领域,多语言指令数据集的研究正逐渐成为前沿热点。Everything_Instruct_Multilingual数据集以其庞大的数据规模和广泛的语言覆盖,为多语言大语言模型的训练提供了丰富的资源。该数据集涵盖了科学、社交媒体、通用知识、烹饪、写作、医学、历史、法律、角色扮演、新闻、编程、数学和函数调用等多个领域,尤其在多语言指令生成和跨语言理解方面展现出巨大潜力。近年来,随着开源AI模型的快速发展,该数据集在推动多语言模型的性能提升和跨领域应用方面发挥了重要作用。特别是在编程和数学领域,该数据集为模型提供了高质量的指令数据,助力其在复杂任务中的表现。未来,随着多语言模型的进一步优化,该数据集有望在全球化AI应用中发挥更大的影响力。
以上内容由遇见数据集搜集并总结生成


