McGill-NLP/TopiOCQA
收藏Hugging Face2023-09-29 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/McGill-NLP/TopiOCQA
下载链接
链接失效反馈官方服务:
资源简介:
TopiOCQA是一个信息寻求对话数据集,特别关注于主题切换现象。数据集的语言为英语,由众包工作者提供。数据集的规模在10K到100K之间,适用于文本检索和文本生成任务,特别是语言建模和开放域问答。数据集遵循CC-BY-NC-SA 4.0许可。
TopiOCQA is an information-seeking dialogue dataset specifically focusing on the topic switching phenomenon. It is compiled by crowdworkers and uses English as its language. The dataset has a size ranging from 10,000 to 100,000 examples, and is applicable to text retrieval and text generation tasks, particularly language modeling and open-domain question answering. It is licensed under CC-BY-NC-SA 4.0.
提供机构:
McGill-NLP
原始信息汇总
数据集概述
数据集基本信息
- 名称: TopiOCQA
- 任务类别:
- 文本检索
- 文本生成
- 任务ID:
- 语言建模
- 开放领域问答
- 语言: 英语 (en)
- 多语言性: 单语种
- 大小: 10K<n<100k
- 标签: 对话式问答
数据集描述
- 摘要: TopiOCQA是一个信息检索对话数据集,包含挑战性的主题切换现象。
- 语言: 数据集中的语言为英语,由众包工作者使用。
附加信息
-
许可证: 数据集根据Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License授权。
-
引用信息:
@inproceedings{adlakha2022topiocqa, title={Topi{OCQA}: Open-domain Conversational Question Answering with Topic Switching}, author={Adlakha, Vaibhav and Dhuliawala, Shehzaad and Suleman, Kaheer and de Vries, Harm and Reddy, Siva}, journal={Transactions of the Association for Computational Linguistics}, volume = {10}, pages = {468-483}, year = {2022}, month = {04}, issn = {2307-387X}, doi = {10.1162/tacl_a_00471}, url = {https://doi.org/10.1162/tacl_a_00471}, eprint = {https://direct.mit.edu/tacl/article-pdf/doi/10.1162/tacl_a_00471/2008126/tacl_a_00471.pdf}, }
搜集汇总
数据集介绍
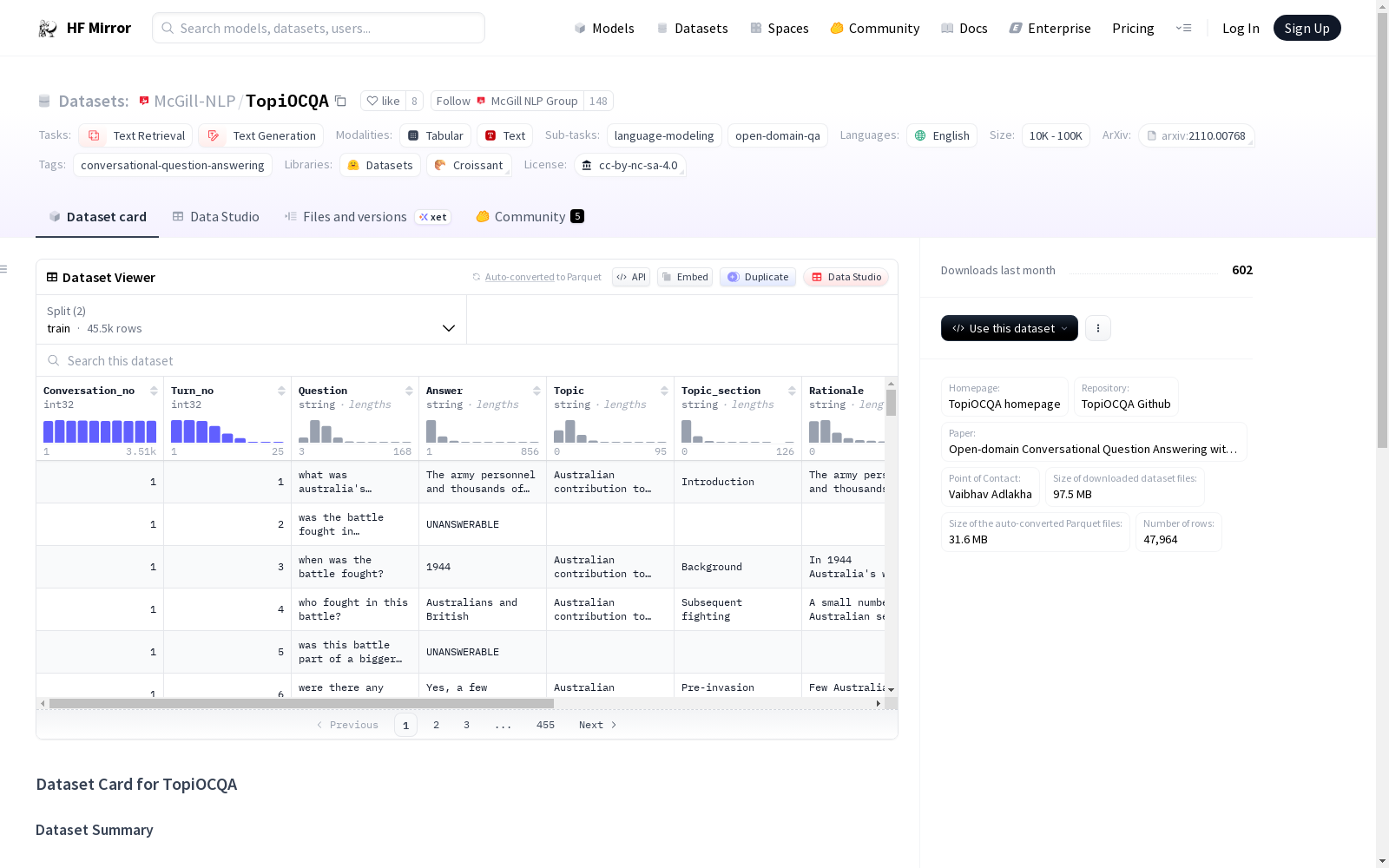
构建方式
在开放域对话问答研究领域,TopiOCQA数据集的构建采用了众包策略,通过精心设计的任务流程,引导参与者模拟真实信息检索场景中的多轮对话。构建过程中,对话被刻意植入了主题转换现象,要求参与者在连续提问中灵活切换话题焦点,从而捕捉自然语言交互中的复杂动态。这一方法不仅确保了对话的多样性和真实性,也为模型训练提供了富含挑战性的语境迁移样本。
特点
TopiOCQA数据集的核心特征在于其蕴含的主题转换现象,这为开放域对话问答任务引入了独特的复杂性。数据集中的对话序列并非局限于单一话题的线性延伸,而是模拟了真实信息寻求过程中常见的话题跳跃与交叉。这种设计使得该数据集超越了传统问答数据集的范畴,成为评估模型在动态语境下理解与推理能力的理想基准。其英语单语属性与中等规模的数据量,进一步保证了研究的可操作性与代表性。
使用方法
该数据集主要应用于开放域对话问答与文本检索等任务,旨在推动对话智能体在复杂信息交互场景下的性能评估。研究人员可依据官方提供的论文与代码库指引,将数据集划分为训练、验证与测试集,用于训练端到端的对话模型或评估检索增强生成系统的效能。使用时应严格遵守知识共享署名-非商业性使用-相同方式共享4.0国际许可协议,并正确引用相关文献,以确保学术研究的规范性与可复现性。
背景与挑战
背景概述
在开放域对话式问答研究领域,传统数据集往往局限于单一话题的连续讨论,难以模拟真实信息寻求场景中频繁的主题转换现象。为此,麦吉尔大学自然语言处理实验室于2022年推出了TopiOCQA数据集,其核心研究目标在于构建一个包含复杂话题切换行为的信息寻求对话语料库。该数据集通过众包方式采集英语对话,旨在推动对话系统在动态话题流中的上下文理解与知识检索能力,为开放域对话智能体的鲁棒性评估提供了关键基准。
当前挑战
TopiOCQA数据集致力于解决开放域对话式问答中话题切换带来的核心挑战,即模型如何在多轮对话中准确追踪跳跃性话题演变并检索分散知识。构建过程中的挑战主要体现在众包设计上:需要精心设计任务框架以引导标注者自然引入话题转换,同时确保对话连贯性与信息真实性;此外,还需平衡话题多样性与知识覆盖度,避免标注偏差影响数据集的泛化能力。
常用场景
经典使用场景
在开放域对话式问答研究领域,TopiOCQA数据集以其独特的主题转换现象为核心,为模型训练与评估提供了关键资源。该数据集通过模拟真实信息检索对话中频繁出现的主题跳跃场景,促使模型在连续问答过程中动态追踪对话历史,并准确捕捉上下文语义的突变。研究者常利用此数据集测试对话代理的连贯性保持能力,以及其在复杂多轮交互中的知识检索与生成性能,从而推动开放域对话系统向更自然、更智能的方向演进。
衍生相关工作
围绕TopiOCQA数据集,已衍生出一系列经典研究工作,这些工作进一步拓展了对话式问答的技术边界。例如,部分研究聚焦于增强模型的上下文建模能力,通过引入记忆网络或图神经网络来显式追踪对话中的主题演变轨迹;另一些工作则探索了多任务学习框架,将主题切换检测与答案生成相结合,以提升整体性能。此外,该数据集也常被用作基准,用于评估预训练语言模型在动态对话环境中的泛化能力,推动了如检索增强生成等前沿方向的发展,为后续学术探索奠定了坚实基础。
数据集最近研究
最新研究方向
在开放域对话问答领域,TopiOCQA数据集因其独特的主题切换现象而备受关注,推动了对话系统理解复杂上下文关联的前沿探索。当前研究聚焦于增强模型对多轮对话中动态主题转换的捕捉能力,结合检索增强生成技术,提升答案的连贯性与准确性。该数据集与热点事件如大型语言模型在对话代理中的应用紧密相连,促进了智能助手在真实场景中的实用化进程,对推动自然语言处理向更人性化、自适应方向发展具有深远意义。
以上内容由遇见数据集搜集并总结生成


