TACO-Cobalt
收藏Hugging Face2026-01-27 更新2026-01-28 收录
下载链接:
https://huggingface.co/datasets/osunlp/TACO-Cobalt
下载链接
链接失效反馈官方服务:
资源简介:
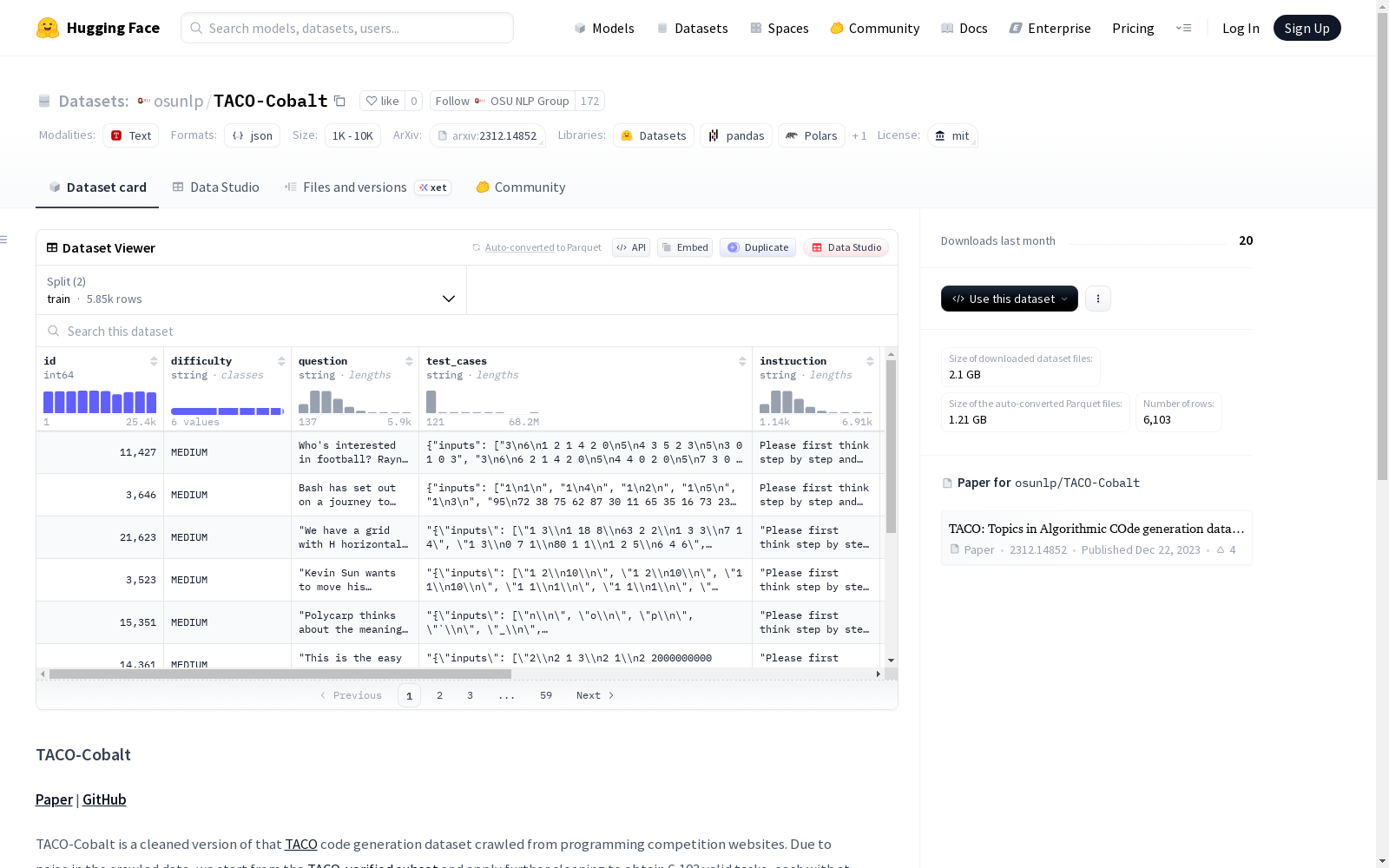
TACO-Cobalt 是一个经过清理的代码生成数据集,源自编程竞赛网站爬取的 TACO 数据集。由于原始数据存在噪声,该数据集基于 TACO-verified 子集进一步清理,最终包含 6,103 个有效任务,每个任务至少包含 8 个测试用例。每个任务的测试用例根据 Qwen2.5-Coder-7B-Instruct 模型在 16 次尝试中通过的可能性进行难度排序,并选择四个最简单的测试用例作为公开测试集(平局时随机选择),其余作为隐藏测试集。此外,从五个标注的难度级别中随机选取 50 个示例,形成包含 250 个示例的验证集,其余 5,853 个示例构成训练集。该数据集适用于代码生成及相关研究任务。
TACO-Cobalt is a curated code generation dataset derived from the TACO dataset scraped from programming competition websites. Due to the noise inherent in the original raw data, this dataset is further cleaned using the TACO-verified subset, ultimately resulting in 6,103 valid tasks, each containing at least 8 test cases. For each task, test cases are ranked by difficulty based on the pass probability of the Qwen2.5-Coder-7B-Instruct model after 16 inference attempts. Four of the simplest test cases are selected as the public test set (randomly chosen in the event of tied difficulty scores), with the remaining test cases reserved as the hidden test set. Additionally, 50 examples are randomly sampled from each of the five annotated difficulty levels, creating a validation set with a total of 250 examples. The remaining 5,853 examples constitute the training set. This dataset is suitable for code generation and related research tasks.
提供机构:
OSU NLP Group
创建时间:
2026-01-25
原始信息汇总
TACO-Cobalt 数据集概述
数据集基本信息
- 数据集名称:TACO-Cobalt
- 许可证:MIT
- 来源:基于编程竞赛网站爬取数据清理而成
数据集描述
TACO-Cobalt 是从编程竞赛网站爬取的 TACO 代码生成数据集的清理版本。由于原始爬取数据存在噪声,本数据集从 TACO-verified 子集开始,经过进一步清理,最终包含 6,103 个有效任务,每个任务至少包含 8 个测试用例。
数据处理与划分
- 测试用例难度排序:针对每个任务,根据 Qwen2.5-Coder-7B-Instruct 模型在 16 次尝试中通过测试用例的可能性对测试用例难度进行排序。
- 公开与隐藏划分:
- 选择四个最简单的测试用例作为公开拆分,用于测试时交互(平局时随机选择)。
- 其余测试用例作为隐藏拆分。
- 数据集划分:
- 从五个标注难度级别中随机选择 50 个示例,组成包含 250 个示例的验证集。
- 其余 5,853 个示例包含在训练集中。
相关资源
- 原始论文:https://arxiv.org/abs/2312.14852
- GitHub 仓库:https://github.com/OSU-NLP-Group/cobalt
- 基础数据集:https://huggingface.co/datasets/likaixin/TACO-verified
引用信息
如果使用本数据集,请引用原始论文: bibtex @misc{li2023tacotopicsalgorithmiccode, title={TACO: Topics in Algorithmic COde generation dataset}, author={Rongao Li and Jie Fu and Bo-Wen Zhang and Tao Huang and Zhihong Sun and Chen Lyu and Guang Liu and Zhi Jin and Ge Li}, year={2023}, eprint={2312.14852}, archivePrefix={arXiv}, primaryClass={cs.AI}, url={https://arxiv.org/abs/2312.14852}, }
搜集汇总
数据集介绍
构建方式
在代码生成领域,高质量的数据集对于模型训练至关重要。TACO-Cobalt数据集源于对编程竞赛网站爬取的原始TACO数据集进行深度清洗的成果。研究团队以TACO-verified子集为基础,通过严格筛选流程,最终保留了6,103个有效任务,每个任务均配备至少8个测试用例。为了区分测试难度,团队利用Qwen2.5-Coder-7B-Instruct模型在16次尝试中的通过率对测试用例进行排序,选取四个最简单的作为公开交互部分,其余则作为隐藏测试集。此外,从五个标注难度级别中随机抽取50个样本,构成包含250个样本的验证集,剩余5,853个样本则纳入训练集,确保了数据结构的科学性与实用性。
特点
TACO-Cobalt数据集在代码生成研究中展现出鲜明的特点。其核心优势在于经过多重清洗后数据的高纯净度,有效去除了原始爬取数据中的噪声,提升了任务的可靠性。每个任务均包含丰富的测试用例,且通过模型评估对测试难度进行了精细排序,公开与隐藏测试集的划分增强了评估的鲁棒性。数据集中还引入了难度分级机制,验证集覆盖了不同难度层次,为模型性能的全面评估提供了坚实基础。这些特征共同支撑了该数据集在算法代码生成任务中的广泛应用价值。
使用方法
在代码生成模型的研究与开发中,TACO-Cobalt数据集提供了清晰的使用路径。研究人员可直接将训练集用于模型训练,利用其高质量任务与测试用例优化生成能力。验证集可用于超参数调优与模型选择,其难度分级设计有助于评估模型在不同挑战水平下的表现。评估阶段,公开测试集支持测试时交互策略的探索,而隐藏测试集则用于最终性能的客观衡量,防止过拟合。该数据集的结构化设计便于集成到现有机器学习流程中,推动代码生成技术的进步。
背景与挑战
背景概述
在人工智能与软件工程交叉领域,代码生成任务正逐步从通用编程向算法实现深化。TACO-Cobalt数据集于2023年由俄亥俄州立大学自然语言处理团队构建,作为TACO数据集的净化版本,其核心研究聚焦于提升算法代码生成的可靠性与评估质量。该数据集源自编程竞赛平台,通过系统化清洗与验证,提供了涵盖不同难度等级的六千余项任务,每项任务均配备多组测试用例,旨在推动代码生成模型在复杂逻辑与边界条件处理上的能力演进,对自动化编程与智能教育工具的发展具有显著影响。
当前挑战
该数据集致力于应对算法代码生成中模型对复杂逻辑理解不足与测试覆盖不全面的核心挑战。在构建过程中,研究者面临原始爬取数据噪声显著、测试用例质量参差不齐的难题,需通过多轮验证与难度分级来确保数据的洁净度与实用性。此外,如何设计公平且具区分度的测试用例排序机制,以准确反映模型在不同算法问题上的性能差异,亦是数据集构建中需要克服的关键技术障碍。
常用场景
经典使用场景
在代码生成领域,TACO-Cobalt数据集常被用于评估和训练大语言模型在算法编程任务上的表现。该数据集源自编程竞赛网站,经过严格清洗,每个任务包含多个测试用例,并按难度排序,为模型提供了丰富的交互式测试环境。研究人员利用其公开和隐藏的测试分割,模拟真实编程场景中的逐步调试与反馈过程,从而系统性地衡量模型在复杂逻辑推理和代码正确性方面的能力。
实际应用
在实际应用中,TACO-Cobalt可作为智能编程助手和教育工具的核心训练资源。它能够帮助开发者或学习者通过自动化测试反馈,快速验证代码逻辑的正确性,提升编程效率与技能。在在线编程平台或代码评审系统中,该数据集支持构建更精准的代码生成与错误检测模块,促进软件开发流程的智能化升级,尤其在算法竞赛培训和初级工程师培养中展现出实用价值。
衍生相关工作
围绕TACO-Cobalt数据集,已衍生出一系列经典研究工作,主要集中在代码生成模型的交互式优化与评估框架上。例如,基于其难度排序的测试用例,研究者开发了渐进式学习策略,以增强模型在复杂任务中的适应性。同时,该数据集也被用于构建基准测试套件,比较不同模型在算法问题上的性能,推动了如测试驱动代码生成、多轮反馈修复等前沿方向的学术进展。
以上内容由遇见数据集搜集并总结生成


