multi_task_multi_modal_knowledge_retrieval_benchmark_M2KR_CN
收藏Hugging Face2024-12-17 更新2024-12-18 收录
下载链接:
https://huggingface.co/datasets/BByrneLab/multi_task_multi_modal_knowledge_retrieval_benchmark_M2KR_CN
下载链接
链接失效反馈官方服务:
资源简介:
M2KR是一个用于多模态知识检索的基准数据集,包含一系列用于训练和评估多模态知识检索模型的任务和数据集。数据集经过预处理,格式统一,并为每个数据集编写了任务特定的提示指令。M2KR基准包含三种类型的任务:图像到文本(I2T)检索、问题到文本(Q2T)检索以及图像与问题到文本(IQ2T)检索。该数据集主要面向计算机视觉、自然语言处理、机器学习和人工智能领域的研究人员和爱好者。
M2KR is a benchmark dataset for multimodal knowledge retrieval, comprising a suite of tasks and datasets designed for training and evaluating multimodal knowledge retrieval models. All datasets within the benchmark have been preprocessed to adopt unified formats, with task-specific prompt instructions compiled for each individual dataset. The M2KR benchmark includes three types of tasks: image-to-text (I2T) retrieval, question-to-text (Q2T) retrieval, and image-and-question-to-text (IQ2T) retrieval. This dataset is primarily targeted at researchers and enthusiasts in the fields of computer vision, natural language processing, machine learning, and artificial intelligence.
创建时间:
2024-12-16
原始信息汇总
M2KR 数据集概述
数据集详情
数据集类型: M2KR 是一个用于多模态知识检索的基准数据集。它包含一系列任务和数据集,用于训练和评估多模态知识检索模型。
我们对数据集进行了预处理,并为其编写了任务特定的提示指令。M2KR 基准包含三种类型的任务:
图像到文本(I2T)检索
这些任务评估检索器根据输入图像找到相关文档的能力。包含的任务有 WIT、IGLUE-en、KVQA 和 CC3M。
问题到文本(Q2T)检索
该任务基于 MSMARCO,用于评估多模态检索器在经过图像检索训练后,是否仍然保留文本检索的能力。
图像与问题到文本(IQ2T)检索
这是最具挑战性的任务,要求对问题和图像进行联合理解以进行准确检索。包含的任务有 OVEN、LLaVA、OKVQA、Infoseek 和 E-VQA。
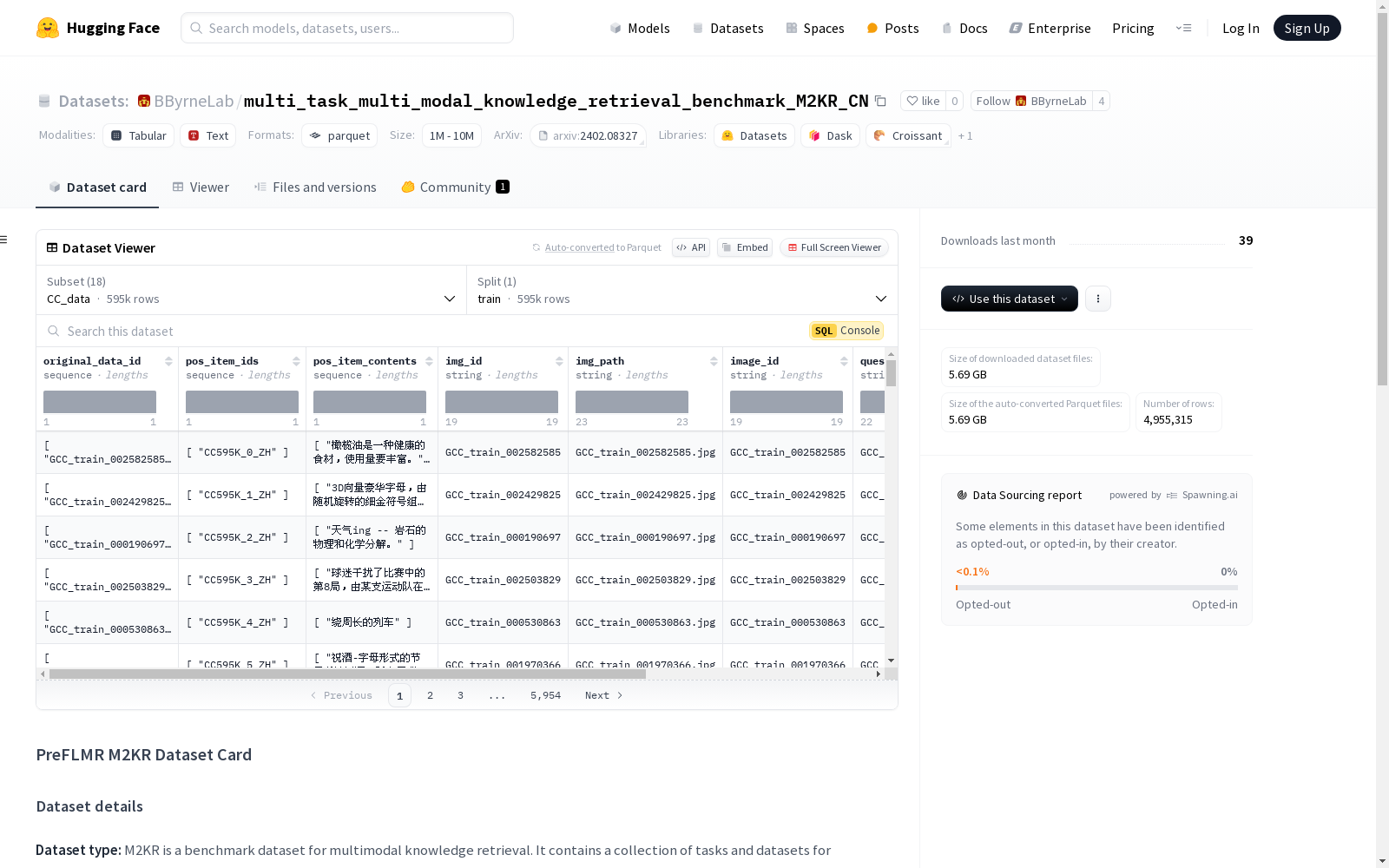
数据集配置
CC_data
- 特征:
original_data_id: 字符串序列pos_item_ids: 字符串序列pos_item_contents: 字符串序列img_id: 字符串img_path: 字符串image_id: 字符串question_id: 字符串question: 空值instruction: 字符串
- 分割:
train: 595375 个样本,167043170 字节
- 下载大小: 67120273 字节
- 数据集大小: 167043170 字节
CC_passages
- 特征:
language: 字符串original_data_id: 字符串img_id: 字符串img_path: 字符串passage_id: 字符串passage_content: 字符串
- 分割:
train_passages: 595375 个样本,121036651 字节
- 下载大小: 54850143 字节
- 数据集大小: 121036651 字节
EVQA_data
- 特征:
pos_item_ids: 字符串序列pos_item_contents: 字符串序列img_id: 字符串img_path: 字符串image_id: 字符串question_id: 字符串question_type: 字符串instruction: 字符串question: 字符串answers: 字符串序列gold_answer: 字符串
- 分割:
train: 36000 个样本,47852957 字节valid: 9852 个样本,11564219 字节test: 3750 个样本,4663589 字节
- 下载大小: 15364997 字节
- 数据集大小: 64080765 字节
EVQA_passages
- 特征:
language: 字符串passage_id: 字符串passage_content: 字符串
- 分割:
train_passages: 50205 个样本,51823434 字节valid_passages: 50753 个样本,52313584 字节test_passages: 51472 个样本,53178991 字节
- 下载大小: 103224478 字节
- 数据集大小: 157316009 字节
Infoseek_data
- 特征:
question_id: 字符串image_id: 字符串answers: 字符串序列answer_eval: 字符串序列data_split: 字符串wikidata_value: float64wikidata_range: float64 序列entity_id: 字符串entity_text: 字符串image_path: 字符串gold_answer: 字符串objects: 列表attribute_scores: float64 序列attributes: 字符串序列class: 字符串ocr: 空值序列rect: float64 序列
related_item_ids: 字符串序列pos_item_ids: 字符串序列pos_item_contents: 字符串序列ROIs: 空值序列found: 布尔值img_caption: 字符串instruction: 字符串img_path: 字符串question_type: 字符串question: 字符串
- 分割:
train: 676441 个样本,9873778866 字节test: 4708 个样本,76283651 字节
- 下载大小: 3616730931 字节
- 数据集大小: 9950062517 字节
Infoseek_passages
- 特征:
passage_id: 字符串title: 字符串passage_content: 字符串
- 分割:
train_passages: 98276 个样本,64095283 字节test_passages: 98276 个样本,64095283 字节
- 下载大小: 83636124 字节
- 数据集大小: 128190566 字节
KVQA_data
- 特征:
pos_item_ids: 字符串序列pos_item_contents: 字符串序列img_id: 字符串img_path: 字符串image_id: 字符串question_id: 字符串instruction: 字符串question: 字符串
- 分割:
train: 64396 个样本,36821520 字节valid: 13365 个样本,7686458 字节test: 5120 个样本,2986917 字节
- 下载大小: 5917828 字节
- 数据集大小: 47494895 字节
KVQA_passages
- 特征:
language: 字符串img_id: 字符串img_path: 字符串passage_id: 字符串passage_content: 字符串
- 分割:
valid_passages: 4648 个样本,2148672 字节train_passages: 16215 个样本,7402199 字节test_passages: 4648 个样本,2148672 字节
- 下载大小: 5440832 字节
- 数据集大小: 11699543 字节
LLaVA_data
- 特征:
pos_item_ids: 字符串序列pos_item_contents: 字符串序列img_id: 字符串img_path: 字符串image_id: 字符串question_id: 字符串llava_split: 字符串instruction: 字符串question: 字符串
- 分割:
train: 350747 个样本,272814650 字节test: 5120 个样本,4761809 字节
- 下载大小: 131077462 字节
- 数据集大小: 277576459 字节
LLaVA_passages
- 特征:
language: 字符串img_id: 字符串img_path: 字符串passage_id: 字符串llava_split: 字符串passage_content: 字符串
- 分割:
train_passages: 350747 个样本,178974631 字节test_passages: 6006 个样本,3746830 字节
- 下载大小: 91406084 字节
- 数据集大小: 182721461 字节
OKVQA_data
- 特征:
question_id: 字符串img_path: 字符串img_key_full: 字符串img_key: int64img_file_name: 字符串img: 空值img_caption: 结构体caption: 字符串conf: float64
objects: 列表attribute_scores: float64 序列attributes: 字符串序列class: 字符串ocr: 列表score: float64text: 字符串
rect: float64 序列
img_ocr: 列表description: 字符串vertices: int64 序列
pos_item_ids: 字符串序列pos_item_contents: 字符串序列related_item_ids: 字符串序列__index_level_0__: 字符串instruction: 字符串question: 字符串answers: 字符串序列gold_answer: 字符串
- 分割:
train: 9009 个样本,173647643 字节valid: 5046 个样本,96516862 字节test: 5046 个样本,96516785 字节
- 下载大小: 112219296 字节
- 数据集大小: 366681290 字节
OKVQA_passages
- 特征:
passage_id: 字符串title: 字符串passage_content: 字符串
- 分割:
valid_passages: 114809 个样本,76410254 字节train_passages: 114809 个样本,76410254 字节test_passages: 114809 个样本,76410254 字节
- 下载大小: 148464966 字节
- 数据集大小: 229230762 字节
OVEN_data
- 特征:
pos_item_ids: 字符串序列pos_item_contents: 字符串序列img_id: 字符串img_path: 字符串image_id: 字符串question_id: 字符串wiki_entity: 字符串wiki_entity_id: 字符串instruction: 字符串question: 字符串
- 分割:
train: 339137 个样本,346757094 字节valid: 119136 个样本,121607773 字节test: 5120 个样本,5203137 字节
- 下载大小: 81869202 字节
- 数据集大小: 473568004 字节
OVEN_passages
- 特征:
language: 字符串passage_id: 字符串passage_content: 字符串
- 分割:
valid_passages: 3192 个样本,2358385 字节train_passages: 7943 个样本,5970224 字节test_passages: 3192 个样本,2358385 字节
- 下载大小: 7114598 字节
- 数据集大小: 10686994 字节
WIT_data
- 特征:
original_data_id: 字符串序列pos_item_ids: 字符串序列pos_item_contents: 字符串序列img_id: 字符串img_path: 字符串image_id: 字符串question_id: 字符串instruction: 字符串question: 字符串
- 分割:
train: 281067 个样本,417266583 字节test: 512 个样本,778601 字节valid: 1999 个样本,3340871 字节
- 下载大小: 253401927 字节
- 数据集大小: 421386055 字节
WIT_passages
- 特征:
language: 字符串page_url: 字符串image_url: 字符串page_title: 字符串section_title: 字符串hierarchical_section_title: 字符串caption_reference_description: 字符串caption_attribution_description: 字符串caption_alt_text_description: 字符串mime_type: 字符串original_height: int64original_width: int64is_main_image: 布尔值attribution_passes_lang_id: 布尔值page_changed_recently: 布尔值context_page_description: 字符串context_section_description: 字符串
搜集汇总
数据集介绍
构建方式
M2KR数据集通过整合多种任务和数据集,构建了一个多任务多模态知识检索的基准。该数据集的构建方式包括对原始数据进行预处理,将其统一格式化,并为每个数据集编写任务特定的提示指令。这些指令旨在评估模型在图像到文本(I2T)、问题到文本(Q2T)以及图像与问题到文本(IQ2T)检索任务中的表现。数据集的多样性体现在其涵盖了多个子任务,如WIT、KVQA、OVEN等,确保了模型在不同场景下的泛化能力。
特点
M2KR数据集的显著特点在于其多任务和多模态的特性。它不仅包含了传统的文本检索任务,还引入了图像与文本的联合检索任务,使得模型能够同时处理视觉和语言信息。此外,数据集的多样性体现在其涵盖了多个子任务和数据集,如WIT、KVQA、OVEN等,确保了模型在不同场景下的泛化能力。数据集的统一格式和任务特定的提示指令进一步增强了其可扩展性和易用性。
使用方法
M2KR数据集主要用于预训练和评估多模态知识检索模型。用户可以通过加载数据集的不同配置(如CC_data、EVQA_data等)来访问特定的任务数据。数据集提供了详细的提示指令,用户可以根据这些指令设计模型训练和评估流程。此外,数据集还提供了图像和文本的联合检索任务,用户可以利用这些数据进行多模态模型的开发和测试。数据集的HuggingFace实现和相关文档为用户提供了详细的使用指南。
背景与挑战
背景概述
M2KR(Multi-Task Multi-Modal Knowledge Retrieval Benchmark)数据集是由多个任务和数据集组成的基准,旨在评估和训练多模态知识检索模型。该数据集的核心研究问题涉及图像与文本之间的关联检索,涵盖了图像到文本(I2T)、问题到文本(Q2T)以及图像与问题到文本(IQ2T)等多种任务。M2KR的构建旨在推动多模态检索技术的发展,特别是在图像与文本联合理解方面的应用。该数据集的创建时间可追溯至2024年,主要研究人员和机构通过预处理和统一格式化多个数据集,提供了丰富的任务指令,以支持多模态检索模型的训练与评估。
当前挑战
M2KR数据集面临的挑战主要集中在多模态数据的整合与检索任务的复杂性上。首先,图像与文本的联合检索任务(IQ2T)要求模型具备对图像和问题的深度理解,这对模型的多模态融合能力提出了极高的要求。其次,数据集的构建过程中,不同来源的数据格式和质量差异较大,如何确保数据的一致性和有效性是一个重要的挑战。此外,多模态检索模型的训练需要大量的计算资源和时间,如何在有限的资源下实现高效的模型训练也是一个亟待解决的问题。
常用场景
经典使用场景
M2KR数据集的经典使用场景主要集中在多模态知识检索模型的预训练与评估。该数据集通过整合图像与文本数据,支持图像到文本(I2T)、问题到文本(Q2T)以及图像与问题到文本(IQ2T)三种检索任务。这些任务旨在评估模型在不同模态下的知识检索能力,尤其是在图像与文本结合的复杂场景中,模型的表现尤为关键。
解决学术问题
M2KR数据集解决了多模态知识检索领域中的关键学术问题,特别是在图像与文本结合的复杂场景下,如何有效检索相关信息。该数据集通过提供多样化的任务类型,帮助研究者探索多模态模型的潜力,推动了跨模态检索技术的发展。其意义在于为多模态检索模型的性能评估提供了标准化的基准,促进了该领域的技术进步。
衍生相关工作
基于M2KR数据集,研究者们开发了多种多模态检索模型,并在多个学术会议上发表了相关工作。例如,一些研究聚焦于提升图像与文本的联合理解能力,另一些则探索了如何在多任务学习框架下优化检索性能。此外,M2KR还启发了其他多模态数据集的构建,进一步推动了多模态学习与检索技术的发展。
以上内容由遇见数据集搜集并总结生成


