LiveDRBench
收藏Hugging Face2025-08-08 更新2025-08-09 收录
下载链接:
https://huggingface.co/datasets/microsoft/LiveDRBench
下载链接
链接失效反馈官方服务:
资源简介:
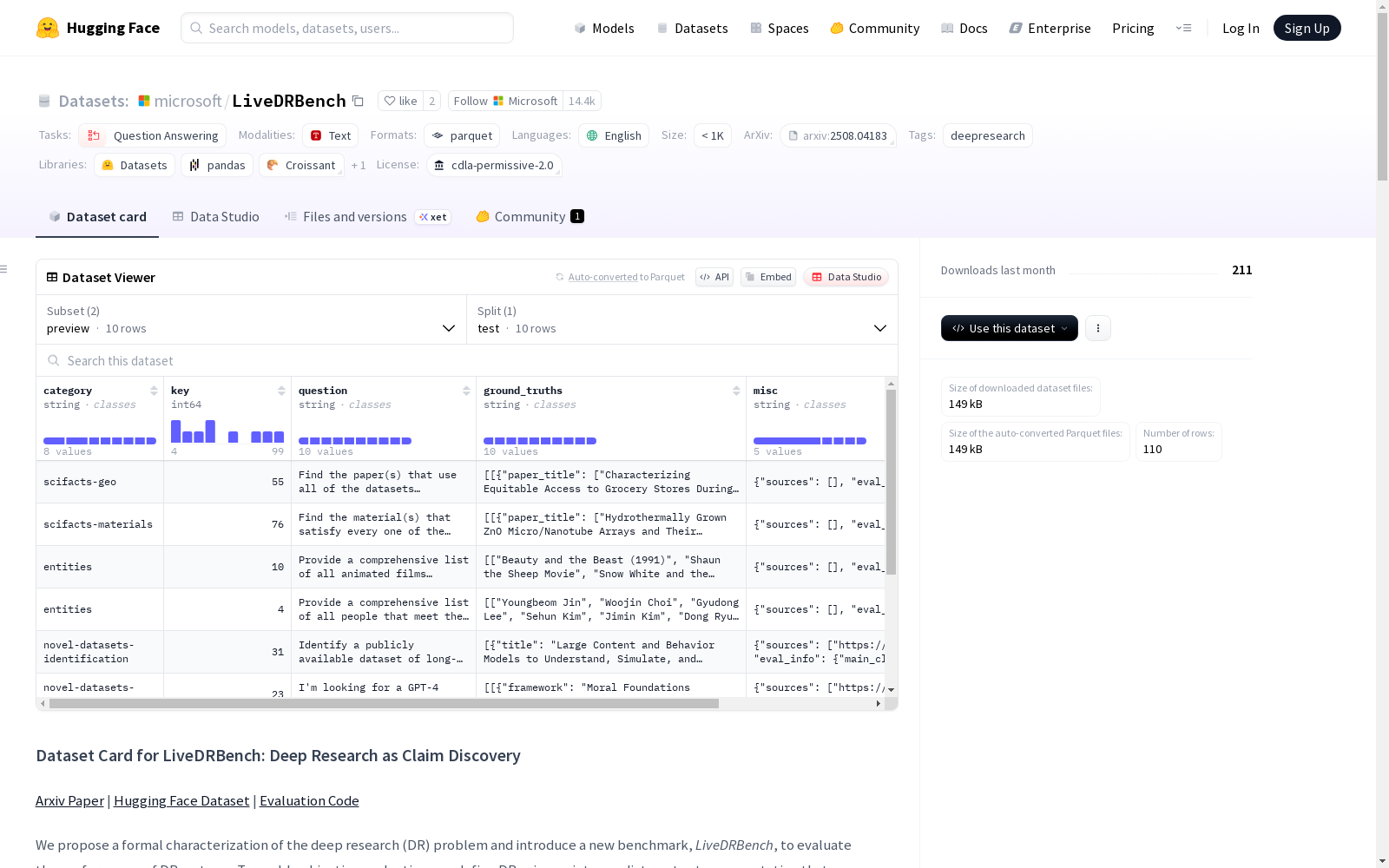
LiveDRBench是一个用于评估深度研究(DR)系统性能的新基准,包含100个具有挑战性的科学主题和公共兴趣事件的任务。数据集包含了任务提示以及地面真实JSON,其中包含了应该发现的声明和参考文献。该基准旨在与Github仓库一起使用,以促进结果的再现和该领域的进一步研究。
LiveDRBench is a novel benchmark for evaluating the performance of deep research (DR) systems. It includes 100 challenging tasks covering scientific topics and public-interest events. The dataset provides task prompts and ground-truth JSON files that contain the target claims and reference materials to be identified. This benchmark is designed to be used alongside its GitHub repository to facilitate result reproducibility and advance further research in this domain.
提供机构:
Microsoft
创建时间:
2025-07-31
搜集汇总
数据集介绍
构建方式
在深度研究领域,LiveDRBench数据集通过问题反转方法构建,将现有推理问题转化为新颖的搜索任务。该过程始于选取长文本推理问题,随后反转问题与答案的关系,形成需要探索性搜索的新问题。为确保答案唯一性,问题经过精心细化并补充额外属性,最终由专业研究人员验证参考答案的准确性与完整性。
特点
LiveDRBench涵盖科学发现与公共事件两大领域,包含材料科学、地理空间分析和计算机科学等八个专业类别。数据集以加密形式存储参考答案,有效防止测试集泄露,并采用标准化JSON格式存储问题与参考答案。其动态更新机制确保基准测试能够持续反映前沿研究需求,为深度研究系统提供多维度的评估框架。
使用方法
研究人员可通过Hugging Face数据集库加载LiveDRBench,利用其评估脚本计算精确率、召回率和F1分数。预测结果需遵循特定JSON格式,通过多线程并行处理提升评估效率。评估过程依赖大型语言模型作为评判工具,用户需配置API密钥并遵循负责任人工智能实践准则。
背景与挑战
背景概述
深度研究作为人工智能领域的前沿方向,旨在通过系统性的信息检索与推理机制解决复杂知识发现任务。LiveDRBench由微软研究院于2025年5月至6月期间构建,核心研究团队包括Abhinav Java、Amit Sharma等学者。该数据集通过形式化定义深度研究问题,构建了包含科学发现与公共事件分析的百项挑战性任务,其创新性在于将推理过程与表面报告生成分离,采用中间输出表征编码关键主张,为评估深度研究系统的性能提供了标准化基准。
当前挑战
该数据集致力于解决深度研究中的主张发现挑战,涵盖科学事实验证、新材料发现、先验艺术检索等多领域复杂推理问题。构建过程中面临双重挑战:一是通过问题反转技术将现有推理问题转化为需独立搜索的任务时,需确保答案唯一性与逻辑一致性;二是跨学科知识覆盖的均衡性难题,尽管涵盖材料科学、地理空间分析等领域,仍存在学科覆盖广度与深度不足的局限性。此外,外部数据源链接的缺失要求模型仅能依赖公开信息进行推理,进一步增加了构建难度。
常用场景
经典使用场景
在深度研究领域,LiveDRBench数据集被设计用于评估系统在复杂科学主题和公共事件中的深度信息挖掘能力。该数据集通过100个具有挑战性的研究任务,涵盖材料发现、数据集识别、先验艺术检索等多个维度,要求系统从海量信息中提取关键主张并验证其准确性。每个任务包含详细的问题描述和期望的输出格式,研究者可利用该数据集测试系统在真实研究场景中的综合推理与信息整合性能。
解决学术问题
LiveDRBench通过定义深度研究的中间输出表示形式,有效解决了传统评估方法难以区分推理能力与表面报告生成的学术难题。该数据集将研究过程解构为可量化的主张发现任务,使研究者能够客观衡量系统在科学事实核查、新颖性发现和文献检索等核心研究环节的效能。这种范式转变促进了深度研究领域的标准化评估,为构建更可靠的研究辅助系统提供了理论基础。
衍生相关工作
LiveDRBench的发布催生了多项深度研究系统的创新工作,其中最具代表性的是基于检索增强生成(RAG)架构的混合研究系统。这些系统结合大型语言模型与专业数据库,实现了更精准的主张提取和验证机制。同时,该数据集推动了评估方法的革新,衍生出基于信息检索指标的三元评估体系(精确率、召回率和F1值),为后续研究如Curie基准的扩展和跨领域研究评估框架奠定了方法论基础。
以上内容由遇见数据集搜集并总结生成


