thinkprm-1K-verification-cots
收藏Hugging Face2025-04-26 更新2025-04-27 收录
下载链接:
https://huggingface.co/datasets/launch/thinkprm-1K-verification-cots
下载链接
链接失效反馈官方服务:
资源简介:
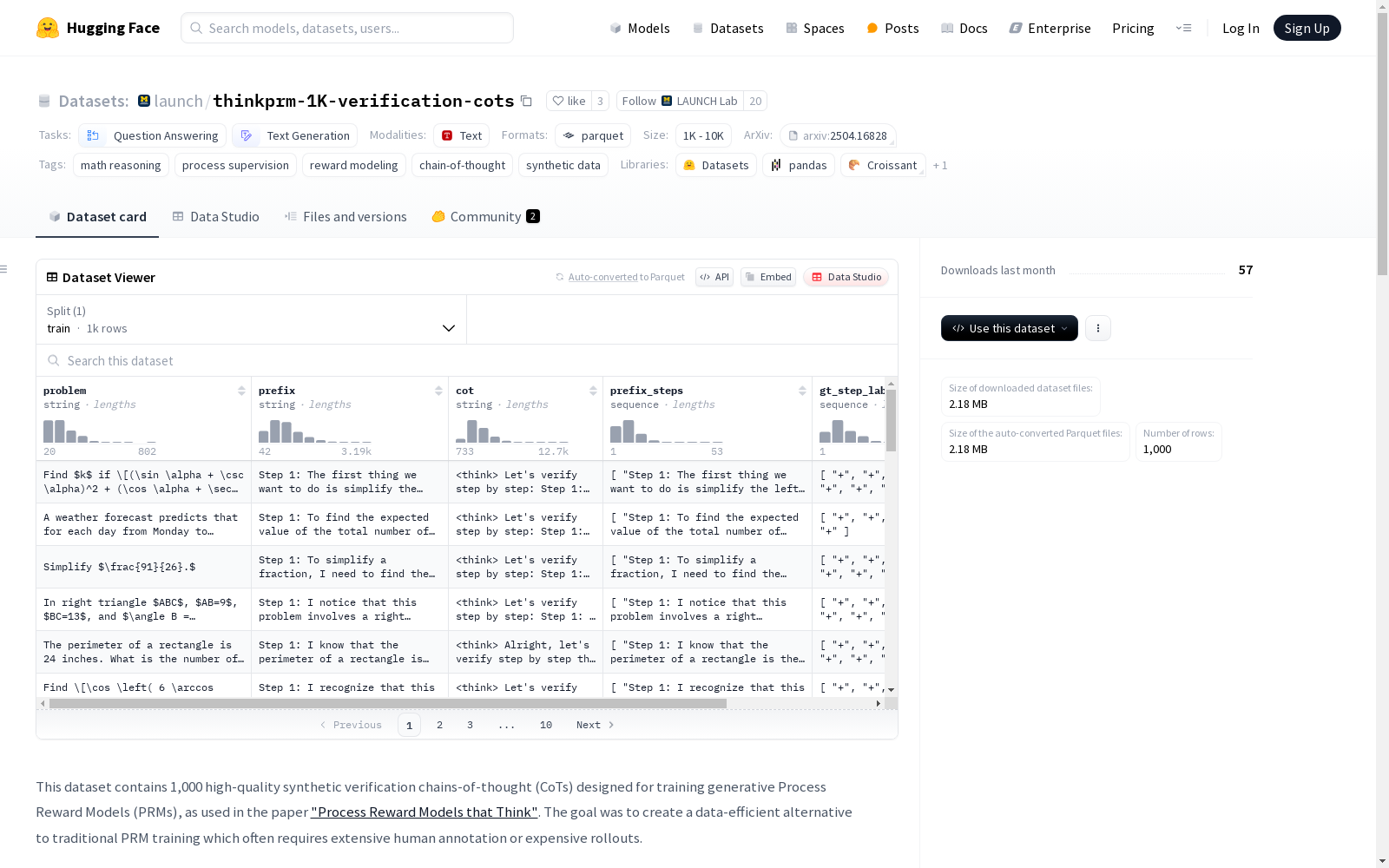
这是一个包含1000个高质量合成验证链的数据集,设计用于训练生成性过程奖励模型(PRM)。每个实例包括一个数学问题、一个相应的多步骤解决方案前缀,以及一个由QwQ-32B-Preview生成的详细验证链。验证链对解决方案前缀的每一步进行批评并提供正确性判断。数据集通过匹配地面真实步骤标签进行过滤,以确保生成高质量的训练数据。
This is a dataset consisting of 1,000 high-quality synthetic verification chains, designed for training generative process reward models (PRM). Each instance includes a mathematical problem, a corresponding multi-step solution prefix, and a detailed verification chain generated by QwQ-32B-Preview. The verification chain critiques each step of the solution prefix and provides correctness judgments. The dataset is filtered by matching against ground-truth step labels to ensure the generation of high-quality training data.
创建时间:
2025-04-25
搜集汇总
数据集介绍
构建方式
在数学推理与过程监督领域,thinkprm-1K-verification-cots数据集通过合成验证链式思维(CoTs)的创新方法构建而成。该数据集从PRM800K中提取数学问题及对应多步解答前缀,利用QwQ-32B-Preview模型生成详细的验证CoTs,并通过严格的质量控制流程筛选数据。具体而言,仅保留所有步骤判断与PRM800K人工标注完全匹配的CoTs,同时过滤格式错误或长度异常的样本,确保数据的高可靠性。
特点
该数据集的核心价值在于其精心设计的结构化特征与高质量合成数据。每个样本包含数学问题、解答前缀、验证CoTs及分步标签,其中验证CoTs提供对解答步骤的详细批判性分析。独特之处在于采用过程监督机制,通过匹配黄金步骤标签进行数据过滤,相比传统结果监督方法,显著提升了生成数据的质量与训练效率,为生成式过程奖励模型(PRMs)的研究提供了精准的训练基础。
使用方法
该数据集专为训练生成式过程奖励模型而设计,适用于数学推理与链式思维验证任务。使用时应重点关注验证CoTs与分步标签的对应关系,通过微调强推理模型来提升验证性能。典型工作流程包括加载数据集、解析结构化字段(如prefix_steps与gt_step_labels),并利用验证CoTs进行模型训练。数据集的代码库与论文提供了详细的实现指导,建议结合PRM800K的原始标注进行交叉验证,以确保模型训练的严谨性。
背景与挑战
背景概述
ThinkPRM-Synthetic-Verification-1K数据集由Muhammad Khalifa等研究人员于2025年构建,旨在为生成式过程奖励模型(PRMs)提供高质量的训练数据。该数据集基于PRM800K数据集中的数学问题及其多步解决方案前缀,利用QwQ-32B-Preview模型生成详细的验证链式思考(CoTs),并通过严格的过滤机制确保数据质量。其核心研究问题在于如何通过合成数据高效训练PRMs,从而减少对人工标注或昂贵数据生成的依赖。该数据集的推出为数学推理和过程监督领域提供了新的研究工具,显著提升了模型训练的效率和性能。
当前挑战
ThinkPRM-Synthetic-Verification-1K数据集面临的挑战主要包括两个方面。其一,在解决数学推理和过程监督问题时,如何确保合成验证链式思考的准确性和一致性,尤其是在多步推理中避免错误累积或逻辑断裂。其二,在数据构建过程中,需克服合成数据生成中的过拟合或过度思考现象,同时严格匹配PRM800K数据集中的真实标注,以保证数据的可靠性和有效性。这些挑战的解决直接关系到模型训练的效果和泛化能力。
常用场景
经典使用场景
在数学推理与过程监督领域,thinkprm-1K-verification-cots数据集通过合成验证链式思维(CoTs)为生成式过程奖励模型(PRMs)的训练提供了高效解决方案。该数据集特别适用于需要精细评估多步数学问题解决过程的场景,例如在自动化数学解题系统中验证每一步推理的正确性。通过结合PRM800K的标注数据与QwQ-32B-Preview生成的合成CoTs,研究者能够训练出更精准的验证模型,显著提升模型对复杂推理过程的监督能力。
实际应用
在实际应用中,thinkprm-1K-verification-cots数据集被广泛用于开发智能教育工具和自动化数学辅导系统。例如,通过集成该数据集训练的模型,系统能够实时分析学生的解题步骤并提供精准反馈,帮助学生识别推理中的错误。此外,该数据集还可用于增强大型语言模型在数学推理任务中的表现,提升其生成答案的可靠性和可解释性。
衍生相关工作
该数据集的推出催生了一系列围绕过程监督和链式思维验证的研究工作。例如,基于其合成数据训练的生成式PRMs在多项数学推理基准测试中表现优异,相关成果被拓展至代码生成和科学问题求解领域。此外,数据集的过滤方法(如基于黄金步骤标签的匹配)也为其他合成数据生成任务提供了重要参考,推动了高质量合成数据在机器学习中的广泛应用。
以上内容由遇见数据集搜集并总结生成


