pii-masking-400k
收藏Hugging Face2024-08-29 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/ai4privacy/pii-masking-400k
下载链接
链接失效反馈官方服务:
资源简介:
Ai4Privacy PII 300k数据集是世界上最大的开放隐私屏蔽数据集。该数据集有助于训练和评估模型,以从文本中移除个人身份和敏感信息,特别是在AI助手和大型语言模型的背景下。数据集包含406,896条记录,总共有20,564,179个令牌,其中2,357,029个是PII令牌。它支持六种语言,并在八个司法管辖区内具有强大的本地化。数据集分为训练集和验证集,分别占80%和20%。该数据集是使用专有算法生成的合成数据,确保不会违反隐私。
The Ai4Privacy PII 300k Dataset is the world's largest open privacy masking dataset. This dataset aids in training and evaluating models to remove personally identifiable information (PII) and sensitive data from text, particularly in the context of AI assistants and Large Language Models (LLMs). The dataset contains 406,896 records, totaling 20,564,179 tokens, of which 2,357,029 are PII tokens. It supports six languages and features robust localization across eight jurisdictions. The dataset is split into training and validation sets, accounting for 80% and 20% respectively. This dataset is synthetic data generated using proprietary algorithms, ensuring no privacy violations.
创建时间:
2024-08-29
原始信息汇总
Ai4Privacy PII 300k Dataset 概述
数据集目的和特点
- 目的:用于训练和评估模型,以从文本中移除个人身份和敏感信息,特别是在AI助手和大型语言模型的背景下。
- 特点:全球最大的开放隐私掩码数据集。
数据集统计信息
- 总条目数:406,896
- 总词数:20,564,179
- 总PII词数:2,357,029
- 公共数据集中的PII类别数:17
- 扩展数据集中的PII类别数:63
语言分布
- 英语 (en):85,321
- 意大利语 (it):81,007
- 法语 (fr):80,249
- 德语 (de):79,880
- 荷兰语 (nl):38,916
- 西班牙语 (es):41,523
地区分布
- 英国 (GB):41,853
- 美国 (US):43,468
- 意大利 (IT):40,629
- 法国 (FR):40,026
- 瑞士 (CH):119,440
- 荷兰 (NL):38,916
- 德国 (DE):41,041
- 西班牙 (ES):41,523
数据集分割
- 训练集:325,517 (80.00%)
- 验证集:81,379 (20.00%)
关键事实
- 数据为合成数据,使用专有算法生成,无隐私侵犯。
- 包含6种语言,8个司法管辖区的强本地化。
- 扩展数据集包含63个PII类别,提供更全面的敏感信息覆盖。
数据集结构
- 每行数据:一个包含自然语言文本的JSON对象,文本中包含PII的占位符。
- 示例行:
source_text:包含PII的自然文本。target_text:源文本的掩码版本。privacy_mask:隐私掩码标签的显式格式。span_labels:文本中私人信息的精确映射跨度。mberttokens:多语言BERT的文本分词。mbert_bio_labels:使用BERT标记的BIO标签任务的标签。id:条目的ID,用于未来参考和反馈。language:内容的语言。locale:与数据相关的地区。split:机器学习集的类型(训练或验证)。
兼容的机器学习任务
- 标记分类
- 文本生成
使用案例和应用
- 聊天机器人
- 客户支持系统
- 电子邮件过滤
- 数据匿名化
- 社交媒体平台
- 内容审核
- 在线表单
- 协作文档编辑
- 研究和数据共享
- 内容生成
许可
- 学术用途鼓励,需遵循类似许可条款并提供适当引用。
- 商业实体应联系
licensing@ai4privacy.com获取许可查询和额外数据访问。
支持和维护
- AI4Privacy 项目隶属于 Ai Suisse SA。
搜集汇总
数据集介绍
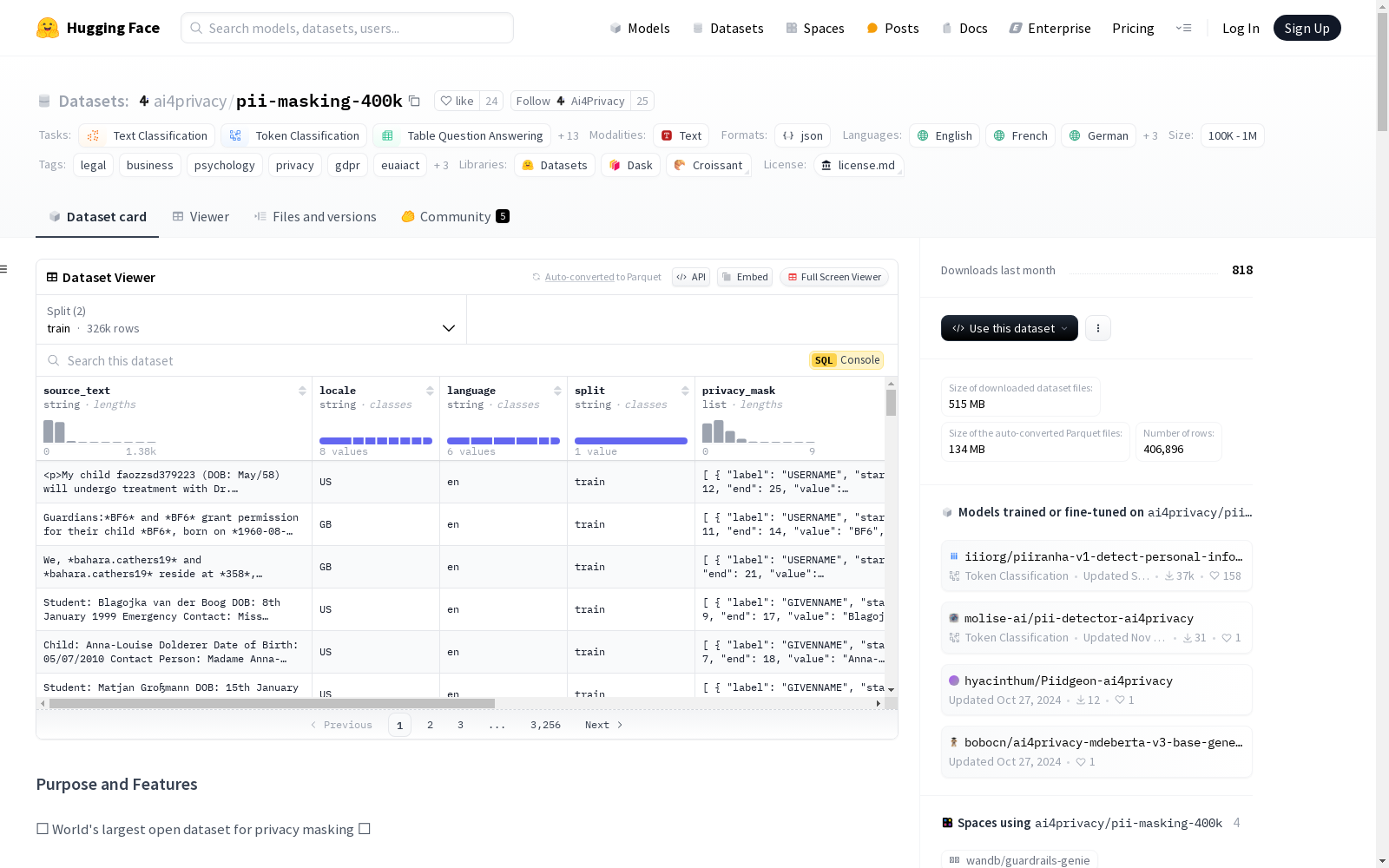
构建方式
pii-masking-400k数据集通过专有算法生成,确保了数据的合成性,避免了隐私泄露的风险。该数据集涵盖了六种语言,并在八个司法管辖区进行了本地化处理。数据集的构建基于自然语言文本,其中包含个人身份信息(PII)的占位符,并通过算法生成相应的掩码版本。数据集分为训练集和验证集,分别占80%和20%,确保了模型训练和评估的平衡性。
特点
pii-masking-400k数据集是全球最大的隐私掩码开放数据集,包含406,896条文本条目,总词数达20,564,179个,其中PII词数为2,357,029个。数据集覆盖了17个PII类别,扩展版本则包含63个类别,提供了更全面的敏感信息覆盖。数据集的多语言特性使其适用于多种语言环境,尤其在英语、意大利语、法语、德语、荷兰语和西班牙语中表现突出。此外,数据集还提供了详细的PII分布和文本长度信息,便于模型优化。
使用方法
使用pii-masking-400k数据集时,可通过Python的`datasets`库加载数据。首先安装库并加载数据集,随后可进行文本分类、标记分类、问答系统等多种机器学习任务。数据集中的每条记录包含原始文本、掩码文本及隐私掩码标签,便于模型训练和评估。用户可根据需求选择不同的任务类型,如标记分类任务可使用BERT、ALBERT等模型,文本生成任务则可使用T5家族模型。数据集还支持多语言BERT的分词和BIO标注任务,适用于复杂的自然语言处理应用。
背景与挑战
背景概述
pii-masking-400k数据集由Ai4Privacy团队开发,旨在为隐私保护领域提供大规模、多语言的文本数据,用于训练和评估模型以识别和屏蔽文本中的个人身份信息(PII)。该数据集于近期发布,涵盖了英语、法语、德语、意大利语、西班牙语和荷兰语六种语言,并在八个司法管辖区进行了本地化处理。数据集的核心研究问题是如何在人工智能助手和大语言模型(LLMs)中有效去除敏感信息,确保用户隐私安全。该数据集通过合成数据生成技术,避免了真实数据的隐私泄露风险,为隐私保护技术的进步提供了重要支持。
当前挑战
pii-masking-400k数据集面临的挑战主要包括两个方面。首先,在领域问题方面,隐私信息的多样性和复杂性使得模型在识别和屏蔽PII时面临高难度。例如,不同语言和文化背景下的PII表现形式各异,模型需要具备强大的多语言处理能力和上下文理解能力。其次,在数据集构建过程中,如何生成高质量的合成数据以模拟真实场景中的PII分布,同时确保数据的安全性和多样性,是一个技术难点。此外,数据集的扩展和持续优化也面临挑战,特别是在多语言本地化和PII类别覆盖方面,需要不断改进算法和数据处理流程。
常用场景
经典使用场景
在自然语言处理领域,pii-masking-400k数据集被广泛应用于训练和评估模型,以从文本中移除个人身份信息和敏感数据。特别是在AI助手和大型语言模型(LLMs)的背景下,该数据集通过提供多语言、多地区的文本数据,帮助模型在隐私保护方面达到更高的准确性和鲁棒性。
实际应用
pii-masking-400k数据集在实际应用中具有广泛的价值。例如,在聊天机器人系统中,该数据集可以帮助自动屏蔽用户对话中的敏感信息,确保隐私安全。在客户支持系统中,它能够保护客户数据,避免敏感信息泄露。此外,该数据集还可用于电子邮件过滤、数据匿名化、社交媒体平台的内容审核等多个场景,提升数据隐私保护水平。
衍生相关工作
基于pii-masking-400k数据集,许多经典工作得以衍生。例如,研究人员利用该数据集开发了多种隐私保护模型,如基于BERT、RoBERTa等预训练模型的PII识别与屏蔽系统。此外,该数据集还推动了多语言隐私保护技术的发展,促进了跨语言隐私保护模型的研发与优化。
以上内容由遇见数据集搜集并总结生成


