Tracebench
收藏Hugging Face2026-01-22 更新2026-01-23 收录
下载链接:
https://huggingface.co/datasets/Schwerli/Tracebench
下载链接
链接失效反馈官方服务:
资源简介:
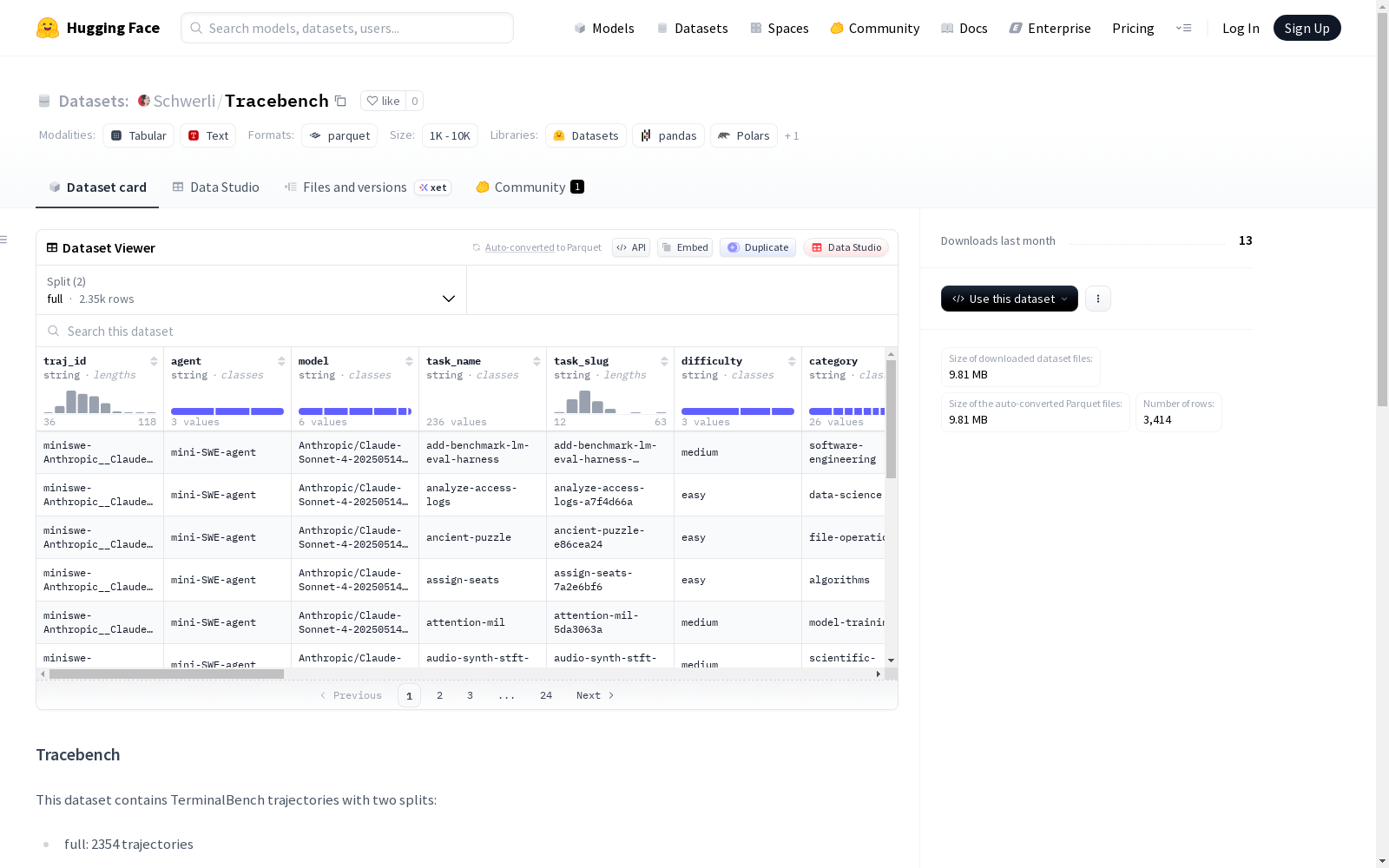
该数据集包含TerminalBench轨迹数据,分为两部分:full(2354条轨迹)和verified(1060条轨迹,经过筛选,step_count>=20,有错误步骤,且错误阶段比例超过阈值)。清单文件包括incorrect_stages信息,记录了错误/无用步骤的分组情况,具体包含stage_id、incorrect_step_ids、unuseful_step_ids和steps的详细信息。数据集还引用了artifact文件,可通过提供的命令进行提取。
This dataset contains TerminalBench trajectory data, split into two subsets: full (2354 trajectories) and verified (1060 filtered trajectories with step_count ≥ 20, containing erroneous steps, and the proportion of erroneous stages exceeding the threshold). The accompanying manifest file includes the incorrect_stages information, which records the grouping of erroneous or unuseful steps, with detailed information including stage_id, incorrect_step_ids, unuseful_step_ids, and steps. The dataset also references artifact files, which can be extracted via the provided commands.
创建时间:
2026-01-21
原始信息汇总
Tracebench 数据集概述
数据集基本信息
- 数据集名称:Tracebench
- 托管地址:https://huggingface.co/datasets/Schwerli/Tracebench
- 数据格式:Parquet / JSONL
数据内容与划分
该数据集包含 TerminalBench 轨迹数据,划分为两个子集:
- full(完整集):包含 2354 条轨迹。
- verified(已验证集):包含 1060 条轨迹。该子集经过筛选,筛选标准为:轨迹步数(step_count)大于等于 20,且包含错误步骤(has incorrect);同时根据内部错误阶段比例阈值进行选择(错误阶段定义为该阶段内错误步骤比例大于等于 50%)。
关键文件
- 数据文件:
bench_manifest.full.parquet/bench_manifest.full.jsonlbench_manifest.verified.parquet/bench_manifest.verified.jsonl
- 引用文件:
- 清单中
artifact_path引用的文件位于:bench_artifacts/full/*.tar.zst
- 清单中
数据结构说明
清单中包含 incorrect_stages 字段,用于按阶段对错误/无用步骤进行分组。
stage_id:[stage_start_idx, stage_end_idx],表示阶段的起始和结束索引(基于0的索引,指向轨迹步骤)。incorrect_step_ids/unuseful_step_ids:此阶段内的步骤ID(基于1)。steps:标记为错误/无用的每一步记录,每条记录包含:action_ref/observation_ref:包含{path, line_start, line_end, content}的对象,指向原始轨迹源文件。
注意:incorrect_error_stage_count 的计算方式与之前相同,仅使用错误步骤并遵循相同的每阶段阈值规则(无用步骤不影响此计数)。
数据加载方法
python from datasets import load_dataset
ds_full = load_dataset("Schwerli/Tracebench", split="full") ds_verified = load_dataset("Schwerli/Tracebench", split="verified")
引用文件提取方法
bash zstd -d -c bench_artifacts/full/<traj_id>.tar.zst | tar -xf -
搜集汇总
数据集介绍
构建方式
在终端交互轨迹分析领域,Tracebench数据集通过系统化采集与筛选流程构建而成。原始轨迹数据经过多阶段处理,首先收集了2354条完整轨迹,随后依据严格的质量标准筛选出1060条验证轨迹。筛选条件包括轨迹步骤数不少于20步,且包含错误阶段,其中错误阶段定义为该阶段内错误步骤占比超过50%。数据集以Parquet和JSONL格式存储,并附有原始轨迹的压缩归档文件,确保了数据的完整性与可追溯性。
特点
Tracebench数据集的核心特点在于其精细的错误阶段标注与结构化表示。每条轨迹均标注了incorrect_stages字段,以零基索引明确标识错误阶段的起止位置,并区分错误步骤与无效步骤。数据集提供两种分割:完整分割包含所有轨迹,验证分割则聚焦于高质量轨迹,适用于不同精度的研究需求。此外,数据集通过引用机制关联原始轨迹源文件,支持深度分析与验证,为终端交互的故障诊断与行为建模提供了丰富而可靠的语料。
使用方法
使用Tracebench数据集时,研究人员可通过Hugging Face的datasets库便捷加载。调用load_dataset函数并指定数据集名称与分割类型,即可获取完整或验证轨迹集合。对于深入分析,可利用数据集提供的引用路径解压原始轨迹归档文件,通过命令行工具提取详细步骤记录。这种设计使得数据集既能支持快速的统计研究,也能满足对原始交互序列进行细粒度考察的需求,为终端智能体的训练与评估提供了灵活的基础设施。
背景与挑战
背景概述
Tracebench数据集由Schwerli团队构建,聚焦于终端交互轨迹的分析与评估。该数据集收录了2354条完整轨迹和1060条经过验证的轨迹,旨在支持智能体在复杂命令行环境中的行为理解与错误诊断研究。其核心研究问题涉及如何通过结构化标注,识别轨迹中的错误阶段与无效步骤,从而为自动化调试、智能辅助系统及强化学习智能体的训练提供高质量基准。该数据集的推出,为终端操作智能化领域引入了细粒度的评估框架,促进了人机交互与程序理解方向的实证探索。
当前挑战
Tracebench数据集致力于解决终端交互轨迹中错误模式识别与步骤效用评估的挑战,这要求模型能够准确解析多步操作序列并区分有效与无效行为。在构建过程中,面临轨迹标注的一致性难题,需明确定义错误阶段与无效步骤的边界;同时,数据清洗环节需平衡轨迹数量与质量,通过设定步骤数量阈值与错误阶段比例来筛选验证集,确保数据的代表性与可靠性。此外,原始轨迹的存储与引用结构也增加了数据管理与访问的复杂性。
常用场景
经典使用场景
在软件工程与程序调试领域,Tracebench数据集为研究终端交互轨迹的自动分析与错误检测提供了关键资源。其经典使用场景聚焦于模型评估,通过包含2354条完整轨迹和1060条已验证轨迹,支持对智能体在命令行环境中执行任务的性能进行量化分析。研究者可利用incorrect_stages字段,深入剖析错误阶段内的步骤序列,从而评估模型在复杂终端操作中的鲁棒性与可靠性。
衍生相关工作
围绕Tracebench衍生的经典工作主要集中在轨迹分析算法的改进与评估框架的构建。例如,基于incorrect_stages的统计特征,研究者开发了多阶段错误检测模型,用于识别终端操作中的潜在故障点。同时,该数据集也催生了针对轨迹压缩与可视化工具的研究,促进了软件工程中大规模交互数据的可管理性与可解释性探索。
数据集最近研究
最新研究方向
在软件工程与程序调试领域,Tracebench数据集凭借其详尽的轨迹记录与错误阶段标注,正推动智能辅助编程工具的前沿探索。研究者聚焦于利用其结构化轨迹数据,结合大语言模型分析代码执行中的错误模式,以提升自动化调试与代码修复的准确性。该数据集关联到近期热门的AI编程助手优化事件,通过量化错误步骤与无用操作,为模型训练提供高质量监督信号,从而增强工具在复杂任务中的鲁棒性与实用性,对推动软件智能化发展具有关键意义。
以上内容由遇见数据集搜集并总结生成


