ja-fineweb-2-hvac-fastText-filtered-v3
收藏Hugging Face2025-12-22 更新2025-12-23 收录
下载链接:
https://huggingface.co/datasets/daikin-industries-ltd/ja-fineweb-2-hvac-fastText-filtered-v3
下载链接
链接失效反馈官方服务:
资源简介:
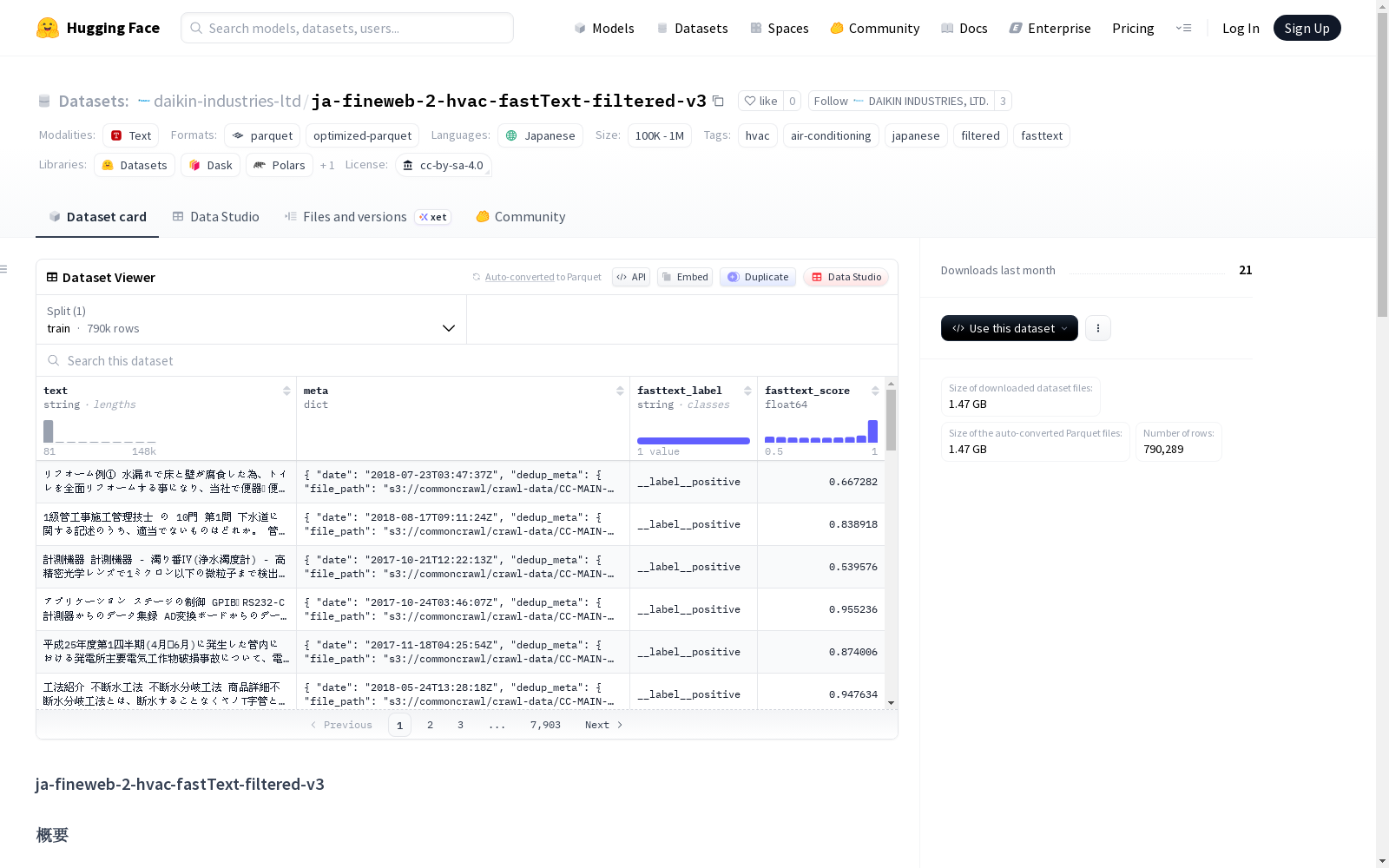
该数据集是从llm-jp/llm-jp-corpus-v3的ja_fineweb_2数据中,使用fastText分类器提取HVAC(空調・暖房・換気・空気調和)相关文本的过滤版本。仅包含被fastText分类器判定为`__label__positive`的记录。数据集包含790,289条记录,总字符数为970,505,001,平均每条记录1,228.0个字符。每条记录包含文本内容、元数据、fastText分类标签和分类分数。
This dataset is a filtered version of texts related to HVAC (Heating, Ventilation, and Air Conditioning) extracted from the `ja_fineweb_2` subset of the `llm-jp/llm-jp-corpus-v3` corpus using a fastText classifier. It only contains records labeled `__label__positive` by the fastText classifier. The dataset consists of 790,289 records in total, with an aggregate character count of 970,505,001 and an average of 1,228.0 characters per record. Each record includes text content, metadata, the fastText classification label, and the classification score.
创建时间:
2025-12-18
原始信息汇总
ja-fineweb-2-hvac-fastText-filtered-v3 数据集概述
数据集概要
此数据集是对 llm-jp/llm-jp-corpus-v3 中的 ja_fineweb_2 数据,使用 fastText 分类器提取出的 HVAC(空调、供暖、通风、空气调节)相关文本数据集。仅包含被 fastText 分类器判定为 __label__positive 的记录。
基本信息
- 许可证: CC BY-SA 4.0
- 语言: 日语 (ja)
- 规模类别: 100K < n < 1M
- 标签: hvac, air-conditioning, japanese, filtered, fasttext
统计信息
| 项目 | 值 |
|---|---|
| 总记录数 | 790,289 |
| 总字符数 | 970,505,001 |
| 平均字符数/记录 | 1,228.0 |
| fastText 分数(最小) | 0.5000 |
| fastText 分数(最大) | 1.0000 |
| fastText 分数(平均) | 0.8101 |
| fastText 分数(中位数) | 0.8428 |
数据结构
每条记录包含以下字段:
text: 文本正文meta: 原始数据的元信息(dump, url, file_path 等)fasttext_label: fastText 分类标签 (__label__positive)fasttext_score: fastText 分类分数(0.0-1.0)
分类器说明
使用 fastText 分类器(v3)进行分类。positive 标签表示 HVAC(空调、供暖、通风、空气调节)相关的文本。
使用方法
python from datasets import load_dataset
dataset = load_dataset("daikin-industries-ltd/ja-fineweb-2-hvac-fastText-filtered-v3") print(dataset)
确认数据
for example in dataset["train"].select(range(5)): print(f"Score: {example[fasttext_score]:.4f}") print(f"Text: {example[text][:200]}...") print("-" * 50)
更新历史
- 2025-12-23: 数据集更新(v3 模型重新分类)
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,针对特定垂直领域的数据集构建对于提升模型的专业性至关重要。ja-fineweb-2-hvac-fastText-filtered-v3数据集源于llm-jp-corpus-v3中的ja_fineweb_2子集,通过fastText分类器进行精细筛选,专门提取与HVAC(供暖、通风、空调及空气调节)相关的日文文本。该构建过程采用监督学习方法,仅保留被分类器标记为__label__positive的记录,并附带置信度评分,确保了数据内容的领域相关性与质量,最终形成了包含约79万条记录的大规模语料库。
特点
该数据集在HVAC专业文本挖掘方面展现出显著特点,其文本总量接近9.7亿字符,平均每条记录长度约为1228字符,涵盖了丰富的技术描述与应用场景。每条记录不仅包含原始文本,还保留了元数据信息以及fastText分类器输出的标签与置信度分数,其中置信度分数的平均值为0.8101,中位数达0.8428,反映了较高的分类可靠性。这种结构设计使得数据集既能支持端到端的语言模型训练,又便于进行质量分析与过滤,为领域适应性研究提供了扎实的数据基础。
使用方法
对于研究人员与开发者而言,该数据集可通过Hugging Face的datasets库便捷加载,直接用于日语HVAC领域的语言模型微调或文本分析任务。使用load_dataset函数即可访问数据,每条样本包含文本内容、元数据、分类标签及置信度分数,用户可依据置信度阈值进一步筛选高质量子集。数据遵循CC BY-SA 4.0许可协议,允许在署名及相同方式共享条件下自由使用与分发,为学术与工业应用提供了灵活且合规的资源支持。
背景与挑战
背景概述
随着人工智能技术在垂直领域的深化应用,专业领域语料库的构建成为推动行业智能化转型的关键基础。由日本大金工业株式会社(Daikin Industries Ltd.)主导构建的ja-fineweb-2-hvac-fastText-filtered-v3数据集,于2025年12月完成最新版本更新,标志着在暖通空调(HVAC)领域日语文本资源建设方面取得了重要进展。该数据集基于llm-jp/llm-jp-corpus-v3语料库,运用fastText分类器进行精准筛选,旨在解决HVAC领域高质量、大规模训练数据稀缺的核心研究问题。其构建不仅为开发面向HVAC行业的日语自然语言处理模型提供了坚实的数据支撑,也对能源管理、智能建筑等相关领域的算法研究与产品开发产生了积极的推动作用。
当前挑战
在HVAC领域构建专用文本数据集面临双重挑战。从领域问题视角看,暖通空调技术涉及复杂的工程原理、设备参数与维护知识,其专业术语多样且语境依赖性强,要求模型具备深度的领域理解能力,以准确完成技术文档分类、故障诊断问答或能效分析报告生成等任务。在数据集构建过程中,主要挑战在于如何从海量、异构的网络文本中高效且准确地识别出与HVAC强相关的片段。尽管采用了fastText分类器进行自动化筛选,但如何设定并验证分类阈值以平衡召回率与精确度,确保所抽取文本的专业相关性与信息完整性,同时处理日语中特有的表达习惯与技术术语变体,均是构建过程中需要持续优化与验证的技术难点。
常用场景
经典使用场景
在暖通空调(HVAC)领域的自然语言处理研究中,该数据集作为日语专业文本的精选语料库,其经典使用场景聚焦于领域特定语言模型的训练与评估。研究者利用其中近80万条经过fastText分类器筛选的高质量文本,构建针对空调、供暖、通风及空气调节等主题的预训练或微调模型,以提升模型在专业术语理解和上下文生成方面的性能。这种应用不仅优化了模型对日语技术文档的处理能力,还为领域内知识密集型任务的自动化奠定了基础。
解决学术问题
该数据集有效解决了暖通空调领域自然语言处理中专业语料稀缺的核心学术问题。通过从大规模日语网络语料中精准提取HVAC相关文本,它为研究者提供了结构化的领域专用数据,支持了诸如领域适应、术语抽取、文本分类及语义理解等任务的模型开发。其意义在于弥合了通用语言模型与专业领域需求之间的鸿沟,推动了日语技术文本处理技术的进步,并为跨语言领域研究提供了可借鉴的数据构建范式。
衍生相关工作
围绕该数据集衍生的经典工作主要包括日语领域自适应预训练模型和HVAC专用知识图谱构建。研究者利用其高质量语料微调基础语言模型,开发了如JaHVAC-BERT等针对暖通空调的日语理解模型,显著提升了领域任务性能。同时,该数据集也支撑了从非结构化文本中抽取实体关系以构建行业知识库的研究,促进了智能诊断和决策支持系统的发展,为后续跨模态或多语言HVAC应用提供了数据基石。
以上内容由遇见数据集搜集并总结生成


