computer-use
收藏Hugging Face2026-02-13 更新2026-02-14 收录
下载链接:
https://huggingface.co/datasets/markov-ai/computer-use
下载链接
链接失效反馈官方服务:
资源简介:
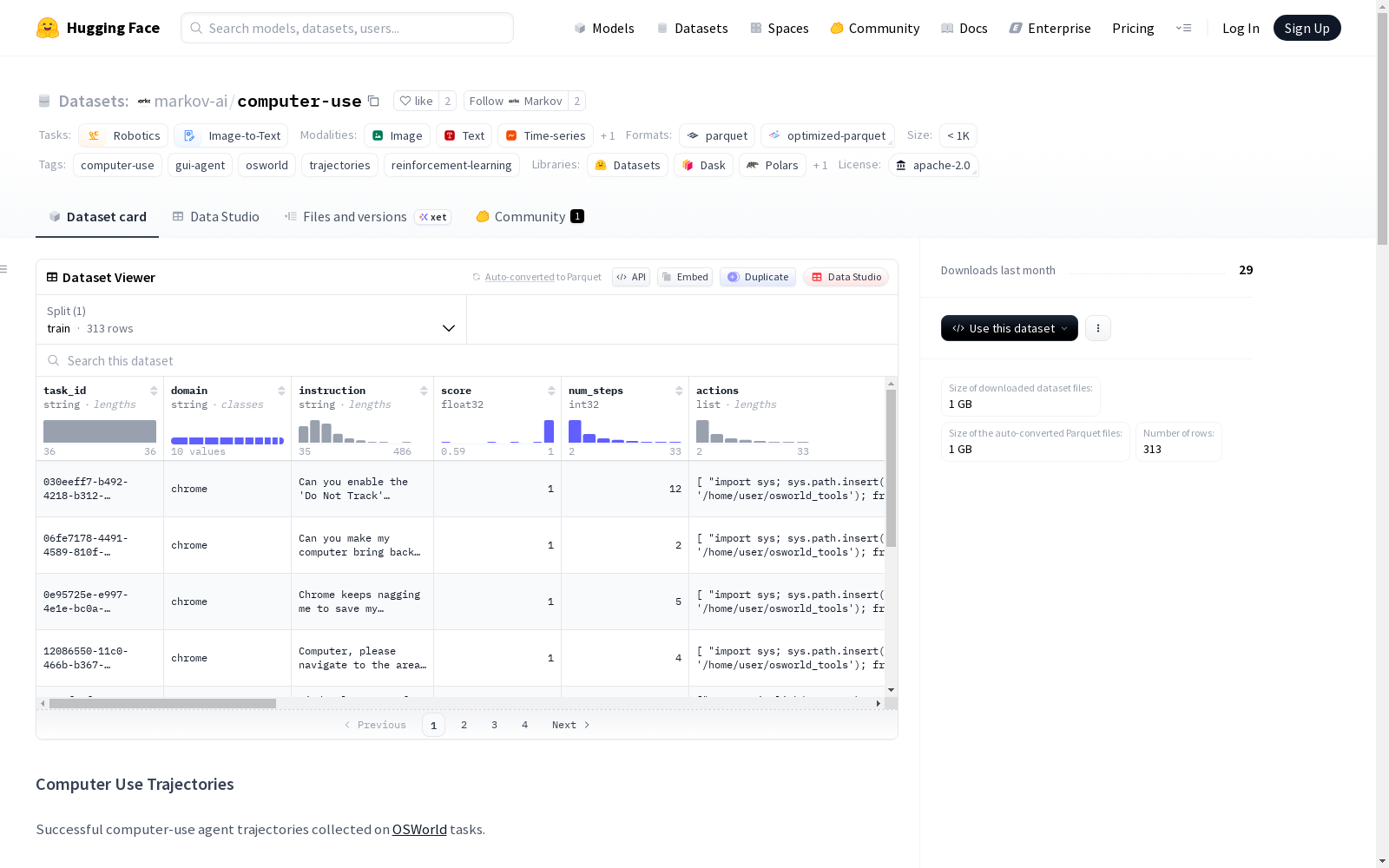
该数据集名为'Computer Use Trajectories',包含在OSWorld任务上收集的成功的计算机使用代理轨迹。数据集规模为160条任务轨迹(每行一条完整轨迹),共计1,378个步骤(平均每条轨迹约8.6步)。所有轨迹都经过筛选,仅包含得分=1.0(完全成功)的轨迹。数据集覆盖多个应用领域,包括Chrome浏览器(21个任务)、GIMP图像编辑(15个任务)、LibreOffice Calc电子表格(17个任务)、LibreOffice Impress演示文稿(20个任务)、LibreOffice Writer文档编辑(11个任务)、跨应用工作流(21个任务)、操作系统/桌面任务(15个任务)、Thunderbird邮件(10个任务)、VLC媒体播放器(8个任务)和VS Code代码编辑(22个任务)。每条轨迹数据包含任务ID、应用领域、自然语言任务指令、得分、步骤数量、执行的pyautogui操作、完整的LLM响应(包括<think>推理)、每一步的桌面PNG截图、线性化的可访问性树、执行状态、标准输出、标准错误、每一步奖励、是否结束标志以及屏幕录制路径等信息。数据集还包含MP4格式的屏幕录制文件,存储在recordings/{domain}/{task_id}.mp4路径下。
This dataset, named 'Computer Use Trajectories', comprises successful computer use agent trajectories collected for the OSWorld task. It contains 160 task trajectories (one complete trajectory per line), totaling 1,378 steps with an average of approximately 8.6 steps per trajectory. All trajectories are filtered to only include entries with a score of 1.0 (fully successful). The dataset covers multiple application domains, including 21 tasks for Chrome browser, 15 for GIMP image editing, 17 for LibreOffice Calc spreadsheets, 20 for LibreOffice Impress presentations, 11 for LibreOffice Writer document editing, 21 for cross-application workflows, 15 for operating system/desktop tasks, 10 for Thunderbird email, 8 for VLC media player, and 22 for VS Code code editing. Each trajectory entry includes task ID, application domain, natural language task instruction, score, number of steps, executed pyautogui operations, complete LLM responses (including <think> reasoning), desktop PNG screenshots for each step, linearized accessibility tree, execution status, standard output (stdout), standard error (stderr), per-step reward, end flag, and screen recording path. Additionally, the dataset includes MP4-format screen recording files stored at the path recordings/{domain}/{task_id}.mp4.
创建时间:
2026-02-12
原始信息汇总
数据集概述:Computer Use Trajectories
基本信息
- 数据集名称:Computer Use Trajectories
- 托管地址:https://huggingface.co/datasets/markov-ai/computer-use
- 许可协议:apache-2.0
- 任务类别:robotics, image-to-text
- 标签:computer-use, gui-agent, osworld, trajectories, reinforcement-learning
- 数据规模:n<1K
- 配置名称:default
- 数据文件:train 分割,路径为 data/train-*.parquet
数据集详情
- 总轨迹数:160 条(每条对应一个任务轨迹)
- 总步骤数:1,378 步(所有轨迹合计,平均约 8.6 步/任务)
- 智能体:Gemini 3 Flash Preview,采用线性化无障碍树(accessibility-tree)作为基础
- 筛选条件:仅包含最终得分(score)为 1.0 的轨迹(即完全成功的任务)
任务领域分布
| 领域 | 任务数量 | 描述 |
|---|---|---|
| chrome | 21 | 谷歌 Chrome 浏览器中的网页浏览任务 |
| gimp | 15 | GIMP 中的图像编辑任务 |
| libreoffice_calc | 17 | LibreOffice Calc 中的电子表格任务 |
| libreoffice_impress | 20 | LibreOffice Impress 中的演示文稿任务 |
| libreoffice_writer | 11 | LibreOffice Writer 中的文档编辑任务 |
| multi_apps | 21 | 跨应用程序的工作流任务 |
| os | 15 | 操作系统/桌面任务 |
| thunderbird | 10 | Thunderbird 中的电子邮件任务 |
| vlc | 8 | VLC 中的媒体播放器任务 |
| vs_code | 22 | VS Code 中的代码编辑任务 |
数据模式(Schema)
每条数据行代表一个完整的任务轨迹。每一步的数据以并行列表的形式存储(所有列表列中的索引 i 对应第 i 步)。
| 列名 | 数据类型 | 描述 |
|---|---|---|
task_id |
string | 任务的 UUID |
domain |
string | 应用领域(例如 "chrome", "gimp") |
instruction |
string | 自然语言任务指令 |
score |
float | 最终任务得分(由于筛选为成功轨迹,均为 1.0) |
num_steps |
int | 该轨迹中的步骤数量 |
actions |
list[string] | 已执行的 pyautogui 操作(Python 代码或 JSON) |
responses |
list[string] | 包含 <think> 推理的完整 LLM 响应 |
screenshots |
list[Image] | 每一步的桌面 PNG 截图 |
accessibility_trees |
list[string] | 每一步的线性化无障碍树 |
exe_statuses |
list[string] | 每一步的执行状态("success" / "error") |
exe_outputs |
list[string] | 每个操作执行的标准输出 |
exe_errors |
list[string] | 每个操作执行的标准错误输出 |
rewards |
list[float] | 每一步的奖励(中间步骤为 0) |
dones |
list[bool] | 每一步是否结束了该回合 |
recording_path |
string | MP4 屏幕录制文件的相对路径 |
使用方式
数据集可通过 datasets 库加载,支持按领域筛选和遍历步骤。
录制文件
MP4 屏幕录制文件存储在 recordings/{domain}/{task_id}.mp4 路径下,这些是捕捉智能体桌面交互的完整过程视频。
数据来源
使用 ComputerRL 评估框架在 OSWorld 虚拟机上收集。
搜集汇总
数据集介绍
构建方式
在计算机智能体研究领域,高质量的交互轨迹数据对于模型训练与评估至关重要。Computer Use数据集通过OSWorld虚拟环境,系统性地采集了智能体在多种桌面应用中的完整任务执行轨迹。该数据集严格筛选了最终得分为1.0的完全成功轨迹,确保了数据的高可靠性。具体构建过程依托ComputerRL评估框架,采用Gemini 3 Flash Preview智能体,并基于线性化的无障碍访问树进行环境感知,最终汇集了涵盖网页浏览、图像处理、办公软件及跨应用工作流等十个领域的160条轨迹,共计1,378个交互步骤。
特点
该数据集的核心特征在于其高度结构化的多模态轨迹记录。每条轨迹不仅包含自然语言任务指令与智能体的完整推理响应,还同步记录了每一步的屏幕截图、可访问性树、执行的PyAutoGUI动作代码以及对应的执行状态与输出。这种设计使得数据能够精确反映智能体在真实桌面环境中的感知、决策与操作闭环。此外,数据集还附带了完整的屏幕录制视频,为视觉行为分析提供了直观的补充。所有数据均经过成功性过滤,为研究可靠的人机交互策略提供了纯净的样本。
使用方法
研究人员可通过Hugging Face的datasets库直接加载此数据集,便捷地访问每条轨迹的完整信息。典型的使用方式包括按任务领域进行筛选,例如提取所有Chrome浏览器相关任务,以进行领域特异性分析。数据集中每一步的截图、动作、响应等信息以并行列表形式存储,便于按步骤索引进行迭代与重组。这些轨迹数据可直接用于模仿学习、强化学习算法的训练,或作为评估基准,分析智能体在复杂图形用户界面环境中的规划与执行能力。
背景与挑战
背景概述
在人工智能与机器人学交叉领域,图形用户界面(GUI)智能体研究致力于开发能够理解并执行计算机操作任务的自主系统。计算机使用轨迹数据集(Computer Use Trajectories)由相关研究团队于近期构建,依托OSWorld仿真环境与ComputerRL评估框架,旨在系统收集并标注智能体在多样化桌面应用中的成功交互轨迹。该数据集的核心研究问题聚焦于如何通过真实的人机交互序列,为基于强化学习与大型语言模型的GUI智能体提供高质量、多模态的示范数据,以推动其在网页浏览、办公软件、媒体编辑等实际场景中的泛化能力与决策精度,对自动化人机协作与通用计算机助手的发展具有重要奠基意义。
当前挑战
该数据集所针对的领域问题——GUI智能体的跨应用任务执行——面临多重挑战:智能体需精准解析自然语言指令,理解动态变化的界面元素状态,并生成可靠的操作序列,其决策过程涉及复杂的多模态感知与规划。在数据集构建过程中,研究者需克服环境仿真的保真度限制,确保虚拟桌面与真实系统行为一致;同时,轨迹收集依赖于特定智能体(如Gemini 3 Flash)的性能,可能引入模型偏好偏差;此外,严格筛选完全成功的轨迹虽保障了数据质量,却也限制了任务难度与失败案例的覆盖,对智能体的鲁棒性学习构成潜在约束。
常用场景
经典使用场景
在图形用户界面智能体研究领域,Computer Use数据集为训练和评估自主计算机操作代理提供了关键资源。该数据集通过记录在OSWorld环境中完全成功的任务轨迹,涵盖了网页浏览、图像编辑、办公软件操作及跨应用工作流等多种实际场景。研究者可利用这些包含屏幕截图、可访问性树及执行动作的轨迹数据,构建能够理解自然语言指令并执行复杂GUI交互的智能体模型,推动人机交互自动化的发展。
实际应用
在实际应用层面,基于Computer Use数据集训练的智能体可广泛应用于软件自动化测试、无障碍技术辅助及个性化办公助手等领域。例如,模型可学习自动完成电子表格数据整理、演示文稿制作或代码编辑等重复性任务,显著提升工作效率。这些技术也有潜力转化为教育工具,帮助用户掌握复杂软件的操作流程,或为行动不便的用户提供更便捷的计算机控制方式。
衍生相关工作
该数据集直接支撑了ComputerRL等评估框架的开发,并催生了一系列关于GUI智能体规划与决策的研究。相关经典工作聚焦于利用轨迹中的多模态信息(如屏幕截图与可访问性树)改进模型的视觉-语言理解能力,以及探索更高效的强化学习策略在动态桌面环境中的泛化性能。这些研究共同推动了将大语言模型与具身交互相结合的新范式,为构建通用计算机助手奠定了基础。
以上内容由遇见数据集搜集并总结生成


