CHIRLA
收藏arXiv2025-02-11 更新2025-02-26 收录
下载链接:
https://www.scidb.cn/en/detail?dataSetId=2247f442a9784b5c959e7bead89c0313
下载链接
链接失效反馈官方服务:
资源简介:
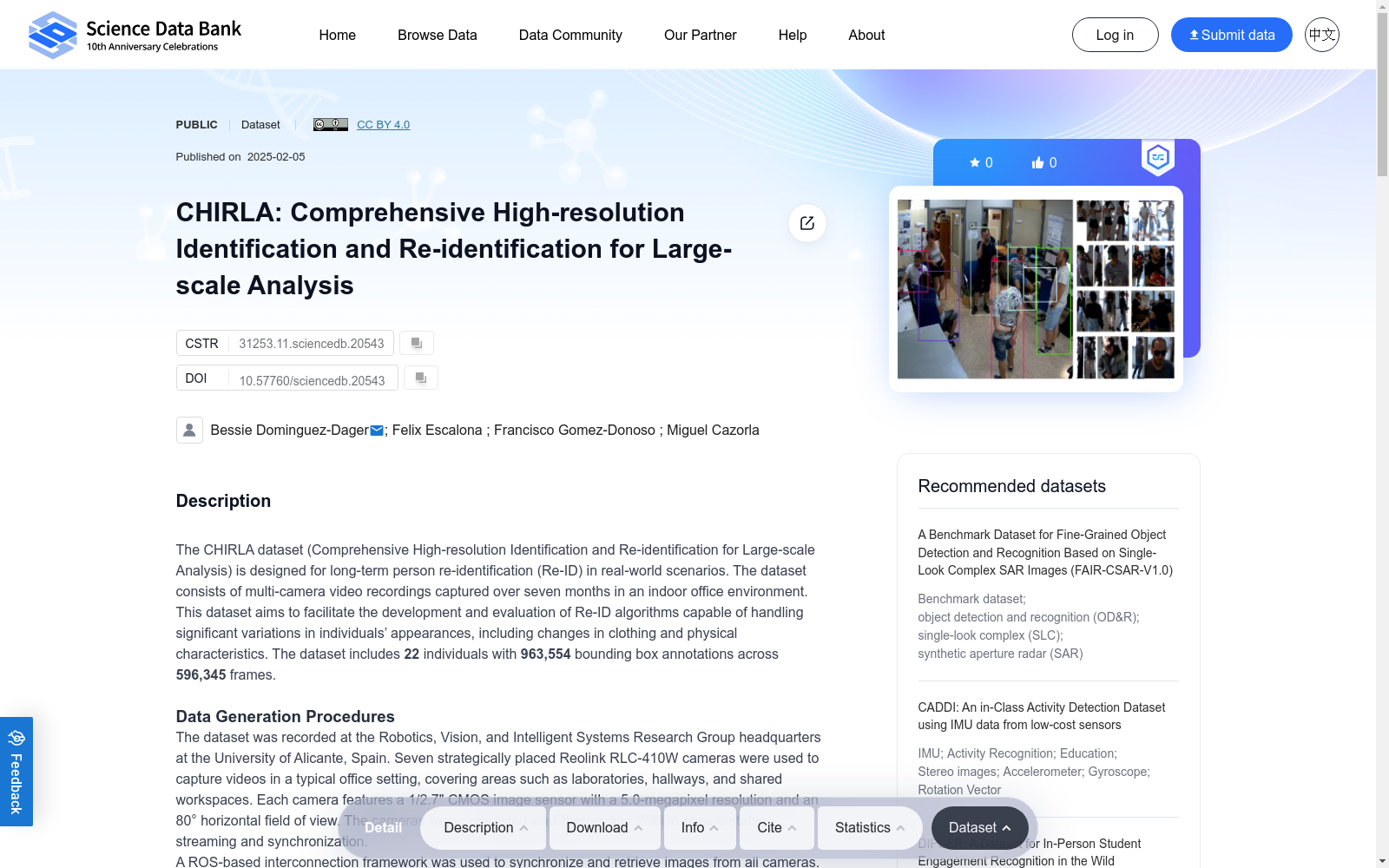
CHIRLA数据集是一个专为长期人物重识别任务设计的新型数据集。该数据集由西班牙阿利坎特大学计算研究所创建,包含七个月期间录制的视频,捕捉了人物在时间上的显著变化以及服装和身体特征的变化。数据集包括22个参与者、四个相连的室内环境和七个摄像头。通过引入这个全面的数据集,旨在促进开发能够在具有挑战性的长期真实世界场景中可靠运行的重识别算法。
The CHIRLA dataset is a novel resource specifically designed for the long-term person re-identification task. Developed by the Institute of Computing at the University of Alicante, Spain, it contains videos recorded over a seven-month period, capturing notable temporal variations of individuals alongside changes in their clothing and physical features. The dataset comprises 22 participants, four interconnected indoor environments, and seven cameras. The release of this comprehensive dataset is intended to advance the development of re-identification algorithms that can reliably operate in challenging long-term real-world scenarios.
提供机构:
西班牙阿利坎特大学计算研究所
创建时间:
2025-02-11
搜集汇总
数据集介绍
构建方式
CHIRLA数据集的构建旨在解决长期人物重识别问题,该问题在计算机视觉领域至关重要。数据集由22名参与者在7个月的时间内,在4个互联室内环境和7个相机上录制的视频组成。这些视频捕捉了参与者在服装和身体特征方面的显著变化,包括有控制的服装变化。通过半自动标注,生成了约100万个带有身份标注的边界框。数据集的构建过程严格遵循了伦理委员会的指导原则,所有参与者均知情并同意其数据的使用。
特点
CHIRLA数据集的特点在于其长期性和高分辨率。它捕捉了参与者在服装和身体特征方面的自然变化,这对于评估和训练长期人物重识别算法至关重要。数据集包含了5个多小时的视频,约100万个边界框,以及22名参与者的身份标注。此外,数据集还提供了跟踪和重识别任务的评估指标,如MOTA、IDF1、CMC和mAP,以支持算法性能的全面评估。
使用方法
使用CHIRLA数据集的方法包括下载数据集和相应的评估软件,这些可以从指定的GitHub存储库中获取。数据集分为10个序列,每个序列包含7个相机视角的视频和相应的标注文件。标注文件以JSON格式提供,每个文件包含每个视频帧中所有检测到的人物的边界框坐标和唯一ID。数据集可以用于评估和训练人物重识别和跟踪算法,特别适用于长期和复杂的场景。用户可以参考数据集论文中的详细说明,了解如何使用数据集进行实验和评估。
背景与挑战
背景概述
CHIRLA数据集的创建旨在解决长期人物重识别(Re-ID)这一计算机视觉中的关键挑战。该数据集由西班牙阿利坎特大学计算研究所的Bessie Dominguez-Dager等人于2025年发布,专注于捕捉个体在长时间跨度内由于服装和身体特征变化而产生的显著外观变化。CHIRLA数据集包含了22个个体、四个相连的室内环境和七个摄像机,收集了超过五个小时的视频,通过半自动标注生成了约一百万个带身份标注的边界框。该数据集的发布对相关领域产生了重要影响,为长期Re-ID算法的开发和评估提供了宝贵资源。
当前挑战
CHIRLA数据集面临的挑战主要在于解决长期人物Re-ID的难题,特别是在现实世界中,个体由于服装和身体特征的显著变化,使得识别变得复杂。构建过程中,研究人员需要设计一个能够捕捉这些变化的系统,同时确保数据的质量和标注的准确性。此外,数据集的构建还需要解决摄像机同步、图像分辨率和标注一致性等问题。为了应对这些挑战,CHIRLA数据集采用了高分辨率视频录制、多摄像机布置、长时间跨度数据收集和半自动标注技术。这些方法确保了数据集能够捕捉到个体长时间内的外观变化,并为Re-ID算法提供了真实的测试平台。
常用场景
经典使用场景
CHIRLA数据集在计算机视觉领域,特别是在人像重识别任务中,被广泛应用于评估和开发算法的性能。该数据集提供了大规模、长时间跨度的人像重识别挑战,使得研究者能够测试算法在实际应用中的可靠性,尤其是在人像外观随时间变化的情况下。通过模拟现实世界中的动态变化,CHIRLA为算法提供了全面的测试环境,确保算法能够在不同的摄像头、位置和时间间隔中准确匹配个人。
解决学术问题
CHIRLA数据集解决了长期人像重识别中的关键学术研究问题。传统的数据集通常集中于短期场景,而CHIRLA专注于捕捉个体在长时间内的外观变化,包括服装和物理特征的显著变化。这为研究提供了独特的资源,以开发和评估能够处理现实世界挑战的鲁棒性算法。此外,CHIRLA还解决了现有数据集在时间一致性、图像分辨率和个体外观变化多样性方面的不足,使得算法能够在更复杂、更具挑战性的场景中进行评估。
衍生相关工作
CHIRLA数据集的发布促进了相关领域的研究工作,包括但不限于人像重识别算法的改进、长期行为分析、跨摄像头追踪技术等。基于CHIRLA的数据,研究者可以开发出更加鲁棒的算法,以应对现实世界中的挑战。此外,CHIRLA还为跨学科研究提供了数据支持,例如结合行为心理学和计算机视觉的研究,以更好地理解个体在长时间内的行为模式。
以上内容由遇见数据集搜集并总结生成


