SynergyAmodal
收藏github2025-04-28 更新2025-04-30 收录
下载链接:
https://github.com/imlixinyang/SynergyAmodal
下载链接
链接失效反馈官方服务:
资源简介:
用于SynergyAmodal: 用文本控制去遮挡任何物体的代码、数据集和模型
Codes, datasets, and models for SynergyAmodal: Text-controlled occlusion removal for arbitrary objects
创建时间:
2025-04-23
原始信息汇总
SynergyAmodal数据集概述
数据集名称
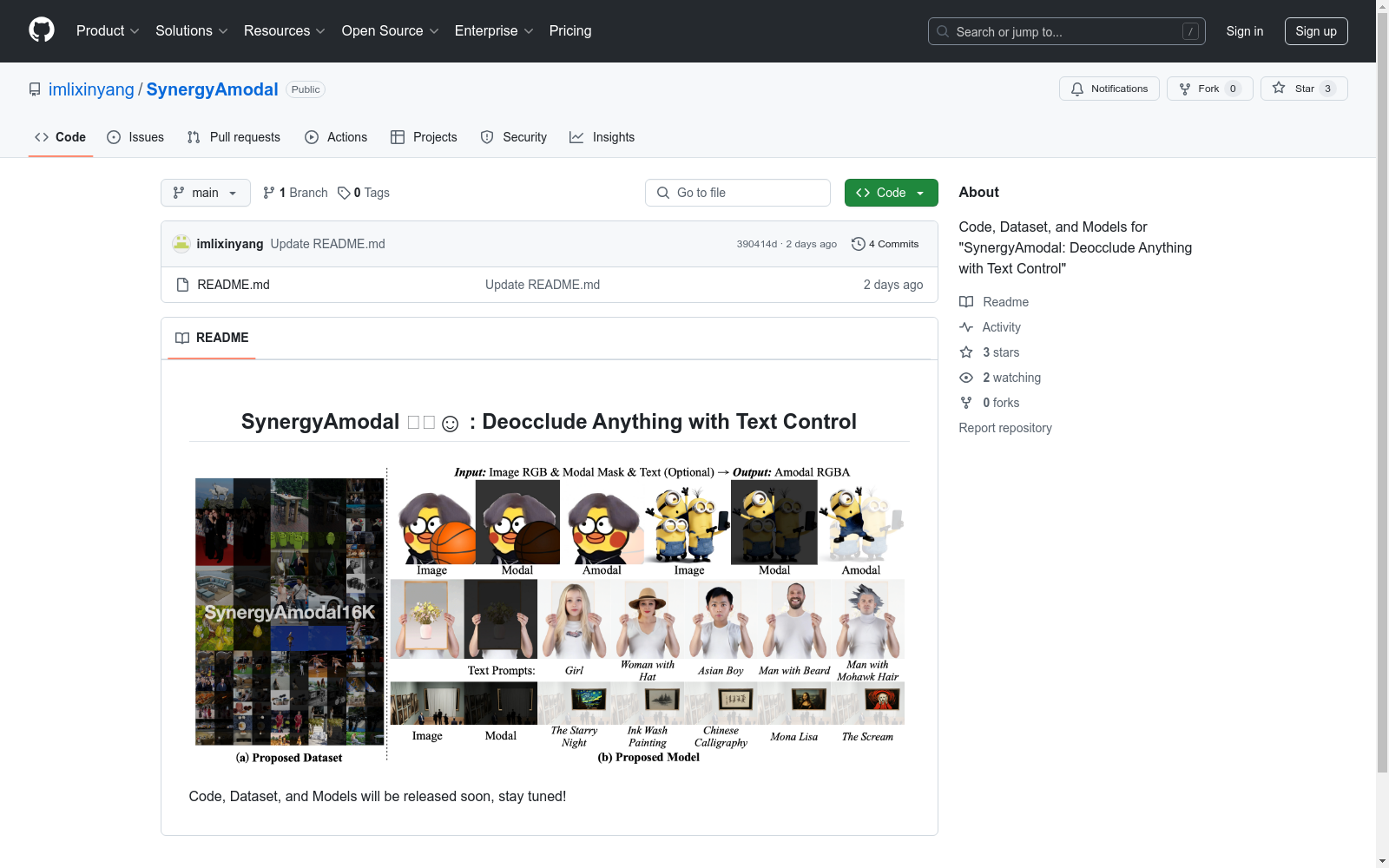
SynergyAmodal 😷⇒☺️
数据集简介
Deocclude Anything with Text Control(通过文本控制实现任意去遮挡)
数据集状态
- 代码、数据集和模型即将发布
- 请保持关注
备注
当前页面仅包含预告信息,具体数据集内容尚未发布。
搜集汇总
数据集介绍
构建方式
SynergyAmodal数据集的构建立足于解决图像去遮挡这一计算机视觉领域的核心挑战,采用多模态融合的创新思路。研究团队通过精心设计的文本引导采集流程,构建了包含丰富遮挡场景的大规模样本库,每张样本均配以精确的文本描述作为语义引导。数据采集过程严格遵循多样性原则,覆盖不同遮挡类型、物体类别及场景复杂度,并通过专业标注团队进行像素级掩码标注和质量校验。
特点
该数据集最显著的特点在于其独特的文本-视觉协同标注体系,将自然语言描述与视觉遮挡信息有机结合。样本涵盖医疗口罩、日常物品等多种遮挡物,提供完整的被遮挡物体轮廓信息及语义上下文。数据集特别强调真实场景的复杂性,包含不同光照条件、视角变化及遮挡程度的分层样本,为模型提供全面的学习素材。高质量的逐像素标注和丰富的元数据使其成为目前最具实用性的去遮挡研究基准之一。
使用方法
研究者可通过文本提示灵活控制去遮挡过程,将文本描述作为先验知识输入模型。数据集支持端到端的训练流程,既可用于监督学习中的掩码预测任务,也适用于文本引导的图像修复研究。使用时应充分挖掘文本标注与视觉数据的关联性,建议采用多阶段训练策略:先利用文本-图像对预训练语义理解模块,再结合像素级标注微调去遮挡网络。数据分块加载和在线增强机制可有效提升训练效率。
背景与挑战
背景概述
SynergyAmodal数据集由前沿研究团队于2024年推出,专注于解决计算机视觉领域中的图像去遮挡难题。该数据集的核心价值在于实现了基于文本控制的任意物体去遮挡功能,标志着视觉内容编辑技术从传统方法向语义驱动方式的重大跨越。研究团队通过构建大规模多模态样本,为图像修复、场景理解等任务提供了关键数据支撑,其创新性体现在将文本指令与视觉去遮挡任务相结合,推动了生成式AI在细粒度图像编辑方向的发展。
当前挑战
该数据集面临双重技术挑战:在领域问题层面,如何精准建立文本描述与复杂遮挡关系的映射成为关键瓶颈,现有方法难以处理多样化的遮挡场景;在构建过程中,需要克服大规模高质量配对数据采集的困难,包括真实遮挡样本的稀缺性、文本标注与视觉内容的一致性校验等问题。多模态数据对齐的复杂性进一步增加了数据集构建的技术难度,这对标注规范和模型架构设计提出了更高要求。
常用场景
经典使用场景
在计算机视觉领域,SynergyAmodal数据集为研究非模态图像去遮挡问题提供了重要支持。该数据集通过结合文本控制技术,使研究人员能够精确指定需要去除的遮挡物,为复杂场景下的物体识别与重建奠定基础。其独特的文本-图像配对标注方式,为多模态学习提供了理想的实验平台。
解决学术问题
SynergyAmodal有效解决了传统去遮挡方法中目标对象不明确、遮挡物难以区分的关键问题。通过引入文本语义指导,该数据集显著提升了算法在部分遮挡场景下的推理能力,为计算机视觉中的场景理解、物体完整性恢复等核心课题提供了新的研究范式。其创新性的数据构建方式突破了现有数据集的局限性。
衍生相关工作
基于SynergyAmodal数据集,已衍生出多个具有影响力的研究工作。包括结合扩散模型的文本引导去遮挡算法、基于注意力机制的多模态融合架构等。这些工作推动了视觉-语言跨模态研究的发展,其中部分成果已在CVPR、ICCV等顶级会议发表,形成了完整的技术演进路线。
以上内容由遇见数据集搜集并总结生成


