Hybrid Dataset
收藏arXiv2025-03-19 更新2025-03-20 收录
下载链接:
https://www.eyelinestudios.com/research/luxpostfacto.html
下载链接
链接失效反馈官方服务:
资源简介:
该数据集是一个混合数据集,由静态表情的OLAT图像和野外视频组成。静态OLAT图像与匹配的平坦照明图像配对,通过图像照明技术获得各种重照明的版本。野外视频包含丰富的运动模式,通过训练图像去照明模型生成估计的平坦照明视频。该数据集旨在解决视频肖像重照明问题,为模型提供既包含精确照明信息又包含多样化运动模式的训练样本。
This dataset is a hybrid corpus composed of static facial expression OLAT images and in-the-wild videos. Static OLAT images are paired with their corresponding flat lighting images, and diverse relighted variants are generated through image relighting techniques. The in-the-wild videos feature abundant motion patterns, and their estimated flat-lighting versions are produced via trained image relighting models. This dataset is designed to tackle the problem of video portrait relighting, providing models with training samples that incorporate both precise lighting information and diverse motion patterns.
提供机构:
Netflix Eyeline Studios, Johns Hopkins University
创建时间:
2025-03-19
原始信息汇总
数据集概述
数据集名称
Lux Post Facto: Learning Portrait Performance Relighting with Conditional Video Diffusion and a Hybrid Dataset
数据集简介
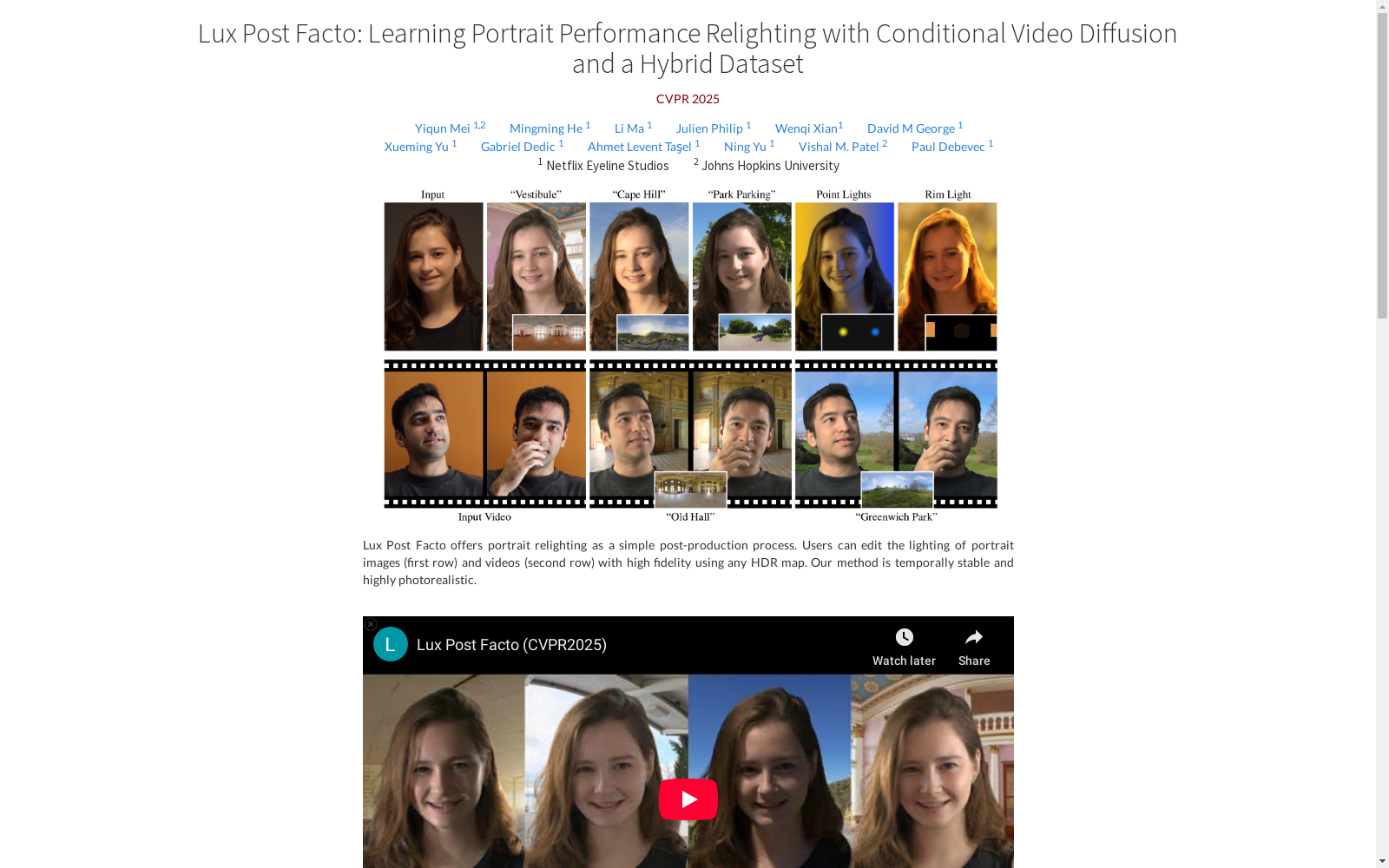
Lux Post Facto 提供了一种简单的后期制作过程,用于肖像图像的重新照明。用户可以使用任何HDR地图对肖像图像和视频进行高保真度的照明编辑。该方法具有时间稳定性和高度逼真的效果。
数据集特点
- 高保真度:能够对肖像图像和视频进行高质量的重新照明。
- 时间稳定性:生成的照明效果在时间上保持稳定。
- 混合数据集:结合了静态OLAT(One-Light-At-A-Time)数据和野外肖像表演视频,用于联合学习重新照明和时间建模。
数据集应用
- 视频肖像重新照明:通过条件视频扩散模型和新的照明注入机制,实现对视频肖像的精确控制和高保真度重新照明。
- 训练策略:使用混合数据集进行训练,避免了在不同照明条件下获取配对视频数据的需求。
数据集贡献者
- Yiqun Mei (Netflix Eyeline Studios, Johns Hopkins University)
- Mingming He (Netflix Eyeline Studios)
- Li Ma (Netflix Eyeline Studios)
- Julien Philip (Netflix Eyeline Studios)
- Wenqi Xian (Netflix Eyeline Studios)
- David M George (Netflix Eyeline Studios)
- Xueming Yu (Netflix Eyeline Studios)
- Gabriel Dedic (Netflix Eyeline Studios)
- Ahmet Levent Taşel (Netflix Eyeline Studios)
- Ning Yu (Netflix Eyeline Studios)
- Vishal M. Patel (Johns Hopkins University)
- Paul Debevec (Netflix Eyeline Studios)
数据集相关论文
- 标题: Lux Post Facto: Learning Portrait Performance Relighting with Conditional Video Diffusion and a Hybrid Dataset
- 作者: Yiqun Mei, Mingming He, Li Ma, Julien Philip, Wenqi Xian, David M George, Xueming Yu, Gabriel Dedic, Ahmet Levent Taşel, Ning Yu, Vishal M. Patel, Paul Debevec
- 会议: CVPR 2025
- 论文链接: https://yiqunmei.net/lux-web/static/pdfs/lux_post_facto.pdf
数据集方法
- 模型架构: 基于稳定视频扩散(SVD)的条件视频扩散模型。
- 照明控制: 通过HDR地图转换为光嵌入,并通过交叉注意力层输入到U-Net中。
- 训练策略: 使用静态OLAT图像和野外视频的混合数据集进行训练,以实现时间一致的肖像视频重新照明。
数据集BibTeX引用
bibtex @article{mei2025lux, title={Lux Post Facto: Learning Portrait Performance Relighting with Conditional Video Diffusion and a Hybrid Dataset}, author={Mei, Yiqun and He, Mingming and Ma, Li and Philip, Julien and Xian, Wenqi and George, David M and Yu, Xueming and Dedic, Gabriel and Taşel, Ahmet Levent and Yu, Ning and Patel, Vishal M and Debevec, Paul}, journal={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, year={2025} }
搜集汇总
数据集介绍
构建方式
Hybrid Dataset的构建结合了静态OLAT(One-Light-At-A-Time)数据和野外肖像视频数据。静态OLAT数据通过高精度LED灯光和同步摄像头捕捉,生成具有精确光照信息的图像。为了扩展数据的多样性,研究人员通过模拟相机运动(如缩放和平移)将这些静态图像转换为视频。此外,野外视频数据则通过图像去光照模型生成伪光照信息,从而形成具有丰富运动但光照未知的视频对。这种混合数据集的构建方式既提供了精确的光照监督,又增强了模型在复杂运动场景下的泛化能力。
特点
Hybrid Dataset的核心特点在于其结合了静态OLAT数据和野外视频数据的优势。静态OLAT数据提供了精确的光照信息,能够为模型提供高质量的光照监督,而野外视频数据则包含了丰富的运动模式,增强了模型在复杂动态场景下的表现。此外,该数据集通过模拟相机运动和伪光照生成技术,避免了传统方法中需要成对视频数据的限制,显著降低了数据采集的复杂性和成本。这种混合设计使得模型能够在保持高保真光照效果的同时,具备良好的时间一致性。
使用方法
Hybrid Dataset主要用于训练视频重光照模型,特别是Lux Post Facto模型。该模型通过两阶段训练策略,首先使用静态OLAT数据进行光照监督,然后结合野外视频数据进行时间一致性训练。在训练过程中,模型通过光照嵌入机制将HDR(高动态范围)光照图编码为光照条件,并通过交叉注意力层实现精确的光照控制。此外,模型还通过参考帧的外观复制任务,进一步增强了时间一致性。最终,该数据集能够支持生成高质量、时间一致的重光照视频,适用于肖像视频的后期处理。
背景与挑战
背景概述
Lux Post Facto数据集由Netflix Eyeline Studios和约翰霍普金斯大学的研究团队于2025年创建,旨在解决视频肖像重光照问题。该数据集结合了静态单光源(OLAT)图像和野外肖像视频,用于训练条件视频扩散模型,以实现高保真度和时间一致性的重光照效果。Lux Post Facto的创新之处在于其混合数据集的构建,避免了在不同光照条件下获取成对视频数据的复杂性。该数据集在计算机视觉和图形学领域具有重要影响力,推动了视频重光照技术的发展,并为内容创作者提供了强大的后期制作工具。
当前挑战
Lux Post Facto数据集面临的挑战主要包括两个方面。首先,视频重光照问题本身具有高度复杂性,要求模型能够精确模拟复杂面部反射并保持时间一致性。现有的方法往往在时间稳定性或真实感上存在不足,且依赖于难以获取的动态OLAT视频数据。其次,在数据集构建过程中,研究人员面临的主要挑战是如何在没有成对视频数据的情况下,通过静态OLAT图像和野外视频的结合来训练模型。这需要创新的训练策略,以确保模型能够从两种数据源中学习到光照和时间建模的联合表示。此外,如何在高动态范围(HDR)光照环境下实现精确的光照控制,也是构建过程中的一大技术难题。
常用场景
经典使用场景
Hybrid Dataset 在视频肖像重光照任务中展现了其经典应用场景。通过结合静态 OLAT(One-Light-at-a-Time)数据和野外拍摄的肖像视频,该数据集能够有效支持视频重光照模型的训练。静态 OLAT 数据提供了精确的光照信息,而野外视频则丰富了动态表情和复杂光照条件下的数据多样性。这种混合数据集的结合使得模型能够在保持时间一致性的同时,生成高度逼真的光照效果。
实际应用
Hybrid Dataset 在实际应用中具有广泛的前景。它能够帮助内容创作者在后期制作中轻松调整肖像视频的光照效果,无需依赖复杂的光照设备和专业团队。例如,在电影制作、广告拍摄以及社交媒体内容创作中,该数据集支持的工具可以显著提升视频的光照质量,增强视觉表现力。此外,它还为虚拟现实和增强现实中的实时肖像重光照提供了技术基础,推动了相关领域的发展。
衍生相关工作
Hybrid Dataset 的提出衍生了一系列相关研究工作。例如,基于该数据集的 Lux Post Facto 方法,结合了条件视频扩散模型和光照注入机制,实现了高度逼真且时间一致的视频重光照效果。此外,该数据集还启发了其他研究团队探索混合数据在光照建模中的应用,如结合 OLAT 数据和野外视频的多任务学习方法。这些工作进一步推动了视频重光照技术的发展,并为未来的研究提供了新的方向。
以上内容由遇见数据集搜集并总结生成


