cuti
收藏Hugging Face2025-12-23 更新2025-12-24 收录
下载链接:
https://huggingface.co/datasets/khursani8/cuti
下载链接
链接失效反馈官方服务:
资源简介:
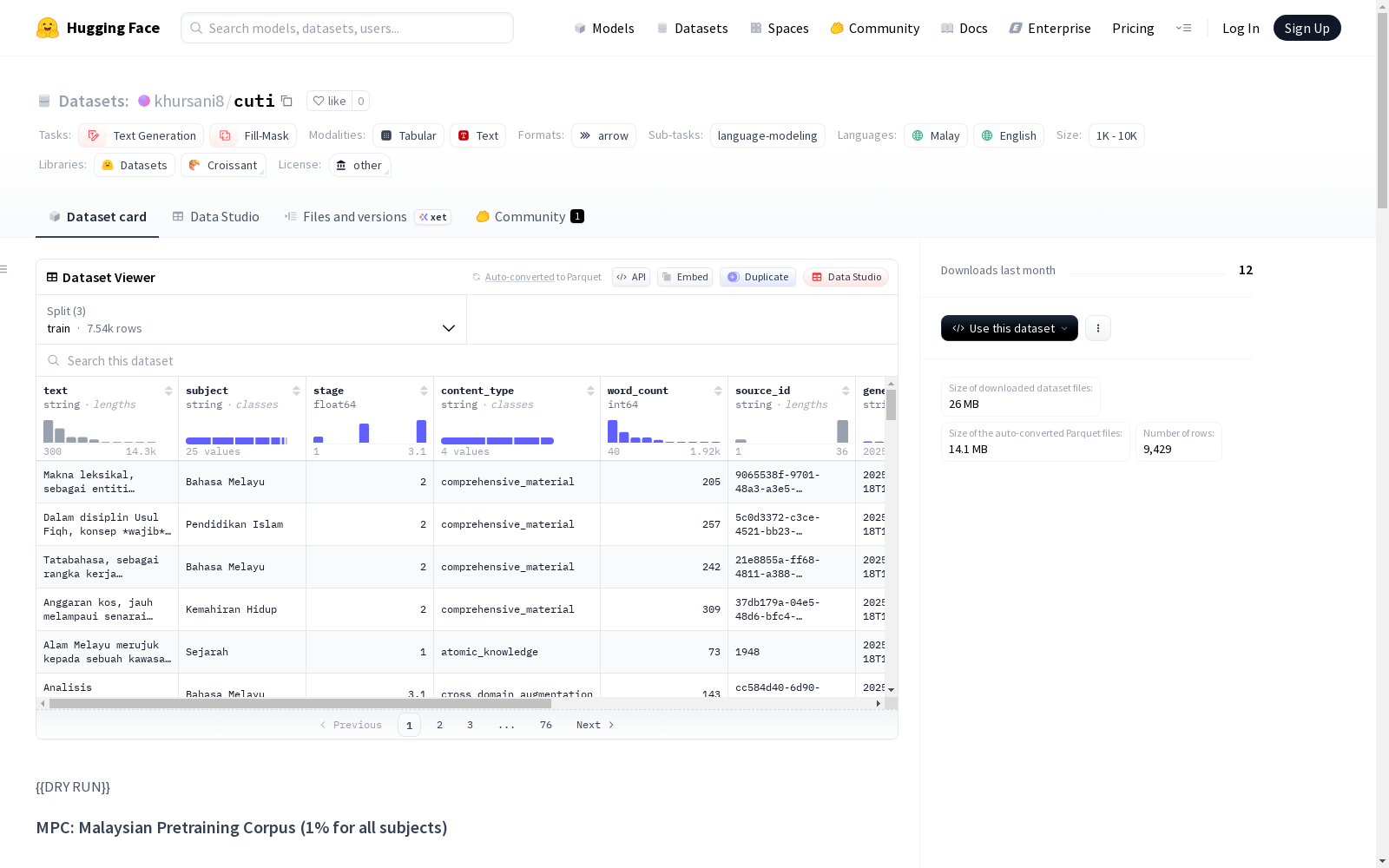
MPC是一个全面的马来西亚教育预训练数据集,包含9,429个条目和3,187,502个单词。该数据集专为训练语言模型而设计,涵盖STEM和人文学科的马来西亚教育内容。主要语言为马来语和英语,包含25个教育科目。数据集结构包括文本内容、学科领域、阶段、内容类型等字段,并分为训练、验证和测试集。
MPC is a comprehensive Malaysian educational pre-training dataset containing 9,429 entries and 3,187,502 words. This dataset is specifically designed for training language models, covering Malaysian educational content across STEM and humanities disciplines. The primary languages are Malay and English, and it includes 25 educational subjects. The dataset structure comprises fields such as text content, subject domain, educational stage, content type, and others, and it is split into training, validation, and test sets.
创建时间:
2025-12-18
原始信息汇总
MPC: Malaysian Pretraining Corpus (1% for all subjects) 数据集概述
数据集描述
MPC 是一个全面的马来西亚教育预训练数据集,包含 9,429 个条目,共计 3,187,502 个单词。该数据集专为在马来西亚 STEM 和人文科目的教育内容上训练语言模型而设计。
数据集详情
- 总条目数:9,429
- 总单词数:3,187,502
- 语言:Bahasa Melayu(主要)、英语
- 科目:25 个教育科目
- 平均每条目单词数:338.05302789267154
内容分布
阶段分布:
- 阶段 1(原子知识):1201 个条目(12.7%)
- 阶段 2(综合材料):3777 个条目(40.1%)
- 阶段 3(复杂句子):2185 个条目(23.2%)
内容类型:
- comprehensive_material:3,777 个条目
- atomic_knowledge:1,201 个条目
- cross_domain_augmentation:2,266 个条目
- complex_sentences:2,185 个条目
科目(部分列举):
- Asas Sains Komputer
- Bahasa Melayu
- Biologi
- Ekonomi
- Geografi
- Kajian Tempatan
- Kemahiran Hidup
- Kimia
- Literasi Komputer
- Matematik
- Matematik Tambahan
- ... 以及另外 13 个科目
数据集结构
每个条目包含以下字段:
text:主要内容文本subject:教育科目领域stage:来源阶段(1、2 或 3)content_type:内容类型(atomic_knowledge、comprehensive_material 或 complex_sentences)word_count:条目中的单词数source_id:原始来源标识符generation_timestamp:内容生成时间
数据划分
- 训练集:7,543 个条目(80%)
- 验证集:942 个条目(10%)
- 测试集:942 个条目(10%)
使用方法
python from datasets import load_dataset
加载数据集
dataset = load_dataset("malaymmlu")
访问不同划分
train_data = dataset[train] val_data = dataset[validation] test_data = dataset[test]
使用示例
for example in train_data: print(f"Subject: {example[subject]}") print(f"Content: {example[text][:200]}...") print(f"Words: {example[word_count]}") break
数据集特征
质量保证
- ✅ 马来西亚教育背景
- ✅ 正确的格式和结构
- ✅ 跨科目的内容多样性
- ✅ 渐进式复杂性(原子 → 综合 → 复杂)
教育价值
- STEM 科目(数学、科学、物理、化学、生物)
- 人文学科(历史、地理、经济学、Bahasa Melayu)
- 技术科目(计算机科学、工程学)
- 伊斯兰研究和马来西亚文化
生成信息
- 生成器版本:stage4_format_v1.1.0
- 生成日期:2025-12-18T13:48:00.482023
- 格式版本:stage4_format_v1.1.0
搜集汇总
数据集介绍
构建方式
在马来西亚教育语料库的构建过程中,研究者精心整合了涵盖科学与人文领域的25门学科内容,形成了包含9,429条文本条目、总计超过318万词汇的综合性数据集。该数据集采用分阶段构建策略,从基础知识点到综合材料,再到复杂句式,逐步深化内容层次,并特别注重跨领域知识的增强,确保了语言模型能够在多元学科背景下进行有效预训练。
特点
该数据集以马来西亚教育体系为核心,深度融合了马来语与英语双语内容,展现出显著的多语言特性。其内容结构经过精心设计,不仅覆盖STEM与人文社科等广泛学科,还通过原子知识、综合材料与复杂句子三种内容类型的系统划分,实现了知识呈现的渐进式复杂度提升,为语言模型提供了层次丰富的学习素材。
使用方法
借助Hugging Face的datasets库,用户可便捷加载该数据集,并直接访问其按8:1:1比例划分的训练集、验证集与测试集。每条数据均包含文本内容、所属学科、发展阶段及词数统计等结构化字段,支持研究人员针对马来西亚教育场景下的文本生成、语言建模等任务开展模型训练与评估工作。
背景与挑战
背景概述
在自然语言处理领域,针对特定语言和文化背景的预训练语料库构建,对于提升语言模型的领域适应性与文化相关性至关重要。MPC(Malaysian Pretraining Corpus)数据集于2025年由相关研究团队创建,旨在为马来西亚教育内容提供专门的多语言预训练资源。该数据集聚焦于解决马来西亚教育体系中STEM与人文学科内容的语言建模问题,涵盖了从基础科学到人文社科的25门学科,以马来语和英语双语形式呈现。其核心研究目标在于通过结构化、渐进复杂的内容设计,支持语言模型对马来西亚本土教育语境的理解与生成,从而推动教育智能化技术在多元文化背景下的应用与发展。
当前挑战
MPC数据集所针对的核心领域挑战,在于如何构建一个能够准确理解和生成马来西亚教育语境下多学科、双语混合内容的语言模型。这要求模型不仅需掌握马来语与英语的语言特征,还需深入理解各学科的专业术语、文化背景及教育体系内的知识结构。在数据集构建过程中,研究者面临多重挑战:首先,需确保教育内容的权威性与准确性,涵盖从原子知识到复杂句子的渐进难度;其次,在数据收集与标注阶段,需平衡多学科内容的分布,并处理双语文本的混合与对齐问题;此外,保持数据格式的一致性、实现内容类型的多样化,以及验证生成内容的真实性与教育价值,均是构建过程中需要克服的技术与质量控制难题。
常用场景
经典使用场景
在自然语言处理领域,针对马来西亚教育内容的多语言模型预训练,MPC数据集提供了一个专门设计的语料库。该数据集整合了STEM与人文学科的多样化教育材料,涵盖从基础概念到复杂句子的渐进式内容,使得研究人员能够训练出更贴合马来西亚本土语境的语言模型。通过其结构化的数据划分与内容类型标注,该数据集常用于评估模型在跨学科知识理解与生成任务上的性能。
实际应用
在实际应用中,MPC数据集可服务于马来西亚教育科技产品的开发,例如智能辅导系统、自动化习题生成与个性化学习平台。其涵盖的25门学科内容能够支撑多学科知识问答系统的构建,同时为教育内容的机器翻译与本地化提供训练资源。该数据集还有助于开发面向马来西亚学生的语言评估工具,提升教育资源的可及性与质量。
衍生相关工作
基于MPC数据集,研究者已开展了一系列经典工作,包括针对马来西亚教育场景的领域自适应预训练模型、跨语言知识蒸馏框架以及教育内容自动摘要系统。这些工作通常聚焦于提升模型在低资源语言下的表现,并探索多模态教育应用。相关研究进一步推动了东南亚地区多语言NLP技术的发展,为教育公平与资源优化提供了技术支撑。
以上内容由遇见数据集搜集并总结生成


