structural-protein-families
收藏Hugging Face2026-05-29 更新2026-05-30 收录
下载链接:
https://huggingface.co/datasets/lamm-mit/structural-protein-families
下载链接
链接失效反馈官方服务:
资源简介:
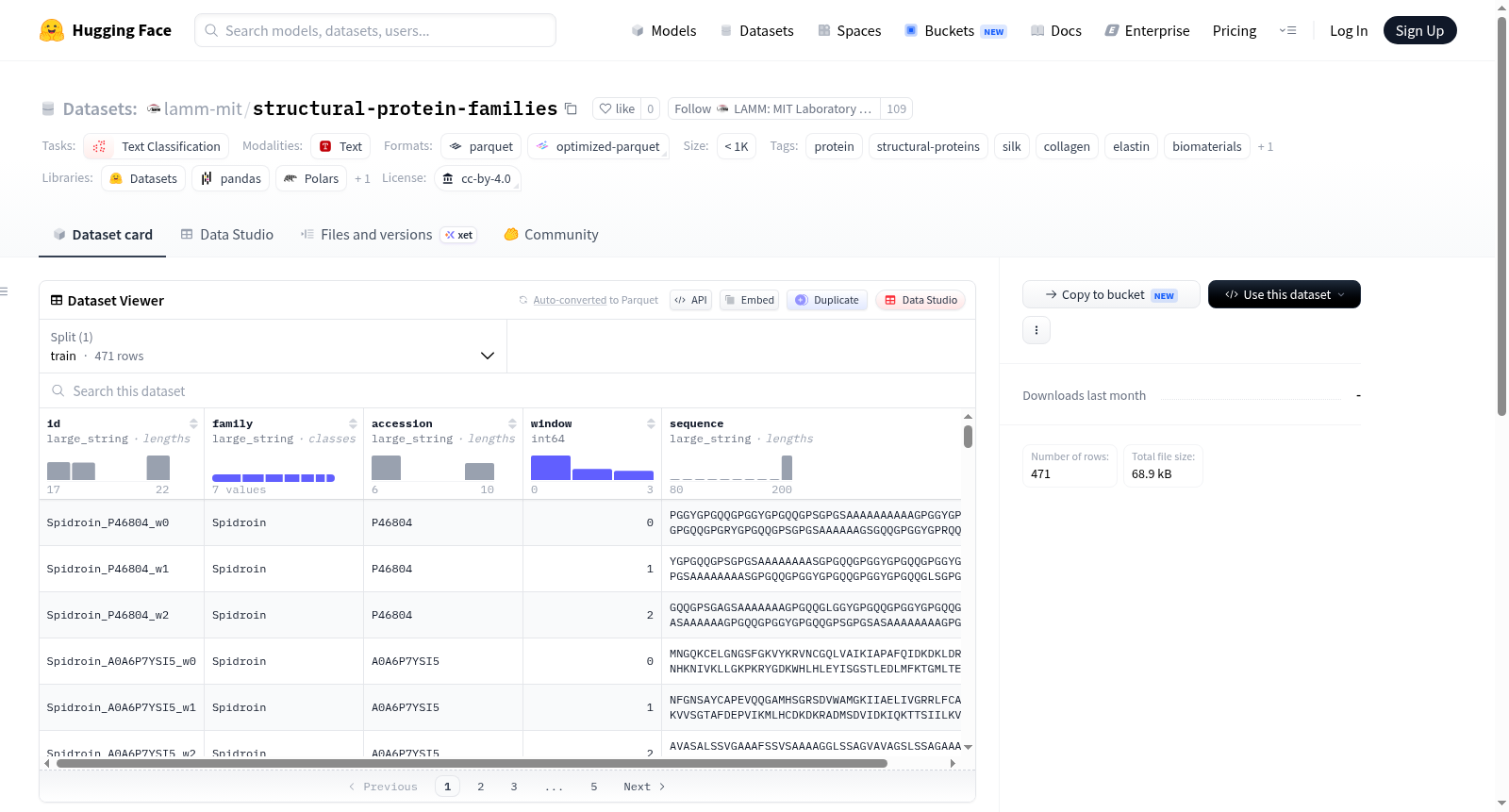
该数据集包含来自多个结构/生物材料蛋白家族(如蜘蛛丝蛋白、蚕丝丝蛋白、胶原蛋白、弹性蛋白、节肢弹性蛋白、角蛋白)以及作为对照的球状蛋白(如溶菌酶、肌红蛋白、细胞色素c)的氨基酸序列窗口。所有序列均提取自UniProt数据库,并被切割成重叠的固定长度窗口。数据集的每一行代表一个序列窗口,并附带一个指示其所属蛋白质家族的类别标签(family)。该数据集专为迁移学习演示而构建,旨在利用预训练的蛋白质语言模型(如ESM)生成的冻结嵌入,训练一个轻量级分类头来预测蛋白质序列窗口所属的家族。数据集包含以下字段:id(由家族标签、UniProt登录号和窗口索引组成的唯一标识符)、family(蛋白质家族类别标签)、accession(源蛋白质在UniProt中的登录号)、window(该窗口在源蛋白质序列中的索引位置)、sequence(氨基酸序列字符串,长度不超过200个残基)。序列窗口的生成规则为:窗口长度为200个氨基酸,滑动步长为150个氨基酸,每个源蛋白质最多取4个窗口。该数据集适用于蛋白质序列分类任务,特别是基于机器学习的蛋白质功能或家族预测研究。
This dataset contains amino acid sequence windows derived from multiple structural/bio-inspired material protein families, including spider silk protein, silkworm silk protein, collagen, elastin, resilin, and keratin, as well as globular proteins used as controls, such as lysozyme, myoglobin, and cytochrome c. All sequences are extracted from the UniProt database and segmented into overlapping fixed-length windows. Each row in the dataset represents a sequence window, accompanied by a category label (family) indicating the protein family it belongs to.
This dataset is specifically constructed for transfer learning demonstrations, aiming to train a lightweight classification head using frozen embeddings generated by pre-trained protein language models (e.g., ESM) to predict the family that the protein sequence window belongs to.
The dataset includes the following fields:
- `id`: A unique identifier composed of the family label, UniProt accession number, and window index;
- `family`: The category label of the protein family;
- `accession`: The UniProt accession number of the source protein;
- `window`: The index position of this window within the source protein sequence;
- `sequence`: An amino acid sequence string with a maximum length of 200 residues.
The sequence windows are generated according to the following rules: the window length is 200 amino acids, the sliding stride is 150 amino acids, and a maximum of 4 windows are extracted from each source protein.
This dataset is suitable for protein sequence classification tasks, particularly machine learning-based research on protein function or family prediction.
提供机构:
LAMM: MIT Laboratory for Atomistic and Molecular Mechanics
创建时间:
2026-05-29
原始信息汇总
数据集概述
名称:Structural-protein families (sequence windows)
许可证:CC-BY-4.0
任务类别:文本分类 (text-classification)
标签:蛋白质、结构蛋白、丝、胶原蛋白、弹性蛋白、生物材料、ESM
配置:
- 配置名:
default - 数据文件:
data/train-*(仅训练集)
数据集描述
该数据集包含来自多个结构/生物材料蛋白质家族(蜘蛛牵引丝、家蚕丝素、胶原蛋白、弹性蛋白、节肢弹性蛋白、角蛋白)以及球状蛋白对照(溶菌酶、肌红蛋白、细胞色素c)的氨基酸序列窗口。序列源自UniProt,被切割成重叠窗口;每一行带有family标签。
数据集专为EvolutionaryScale-protein-mechanics项目中的迁移学习演示构建,可用于在冻结的ESMC嵌入上训练轻量级分类头,以预测蛋白质家族。
数据列
id—<family>_<accession>_w<window>格式的唯一标识符family— 类别标签accession— 来源UniProt登录号window— 在源蛋白质中的窗口索引sequence— 氨基酸窗口序列(长度≤200个氨基酸)
数据来源
通过UniProt REST API按家族搜索获取(参见cli/make_dataset.py)。窗口长度为200个氨基酸,步长为150个氨基酸,每个蛋白质最多取4个窗口。序列版权归各自UniProt条目所有。
搜集汇总
数据集介绍
构建方式
该数据集基于UniProt数据库,针对蜘蛛牵丝蛋白、家蚕丝素蛋白、胶原蛋白、弹性蛋白、节肢弹性蛋白、角蛋白等结构/生物材料蛋白家族,以及溶菌酶、肌红蛋白、细胞色素c等球状蛋白对照组,通过UniProt REST API按家族类别检索氨基酸序列。随后将每条序列切分为长度为200个氨基酸、步长为150的重叠窗口,每个蛋白来源最多保留4个窗口。每条记录包含唯一标识符、家族标签、UniProt登录号、窗口索引及对应的氨基酸序列,最终整合为面向文本分类任务的数据集。
特点
该数据集聚焦于结构蛋白与球状蛋白的序列分类,其核心特色在于采用重叠滑动窗口策略,将从UniProt获取的完整蛋白序列切割为长度不超过200个氨基酸的短片段,在保留局部序列特征的同时有效扩充样本数量。数据集涵盖多个具有显著结构差异的功能蛋白家族,为评估预训练蛋白质语言模型(如ESMC)的迁移学习能力提供了高质量的基准。每个窗口均附带明确的家族标签,便于开展细粒度的序列分类研究。
使用方法
该数据集专为迁移学习实验设计,典型用法是加载冻结的ESMC(EvolutionaryScale Model for Proteins)嵌入表示,在其之上训练轻量级分类头,通过监督学习对结构蛋白家族进行识别。具体实现可参照项目中`cli/esm_train_head.py`脚本。数据以HuggingFace Datasets格式存储,通过`load_dataset`函数即可直接读取,支持按默认配置加载训练集,并利用`family`字段作为分类标签开展模型训练与评估。
背景与挑战
背景概述
结构蛋白家族的序列分类对于生物材料设计与仿生学具有深远意义。该数据集由麻省理工学院LAMM实验室的研究人员基于EvolutionaryScale-protein-mechanics项目构建,发布于2024年前后,旨在利用预训练的蛋白质语言模型ESMC的冻结嵌入向量,训练轻量级分类头以区分结构蛋白家族。数据集涵盖了蛛丝蛋白(spidroins)、蚕丝蛋白(fibroin)、胶原蛋白(collagen)、弹性蛋白(elastin)、节弹性蛋白(resilin)、角蛋白(keratin)等关键结构性生物材料蛋白,以及溶菌酶、肌红蛋白、细胞色素c等球状蛋白作为对照。所有序列来源于UniProt数据库,通过滑动窗口采样生成长度不超过200个氨基酸的重叠序列片段,每个片段附带明确的家族标签。该数据集为结构蛋白序列的功能预测和材料特性研究提供了基准,在蛋白质工程和生物材料领域具有广泛应用价值。
当前挑战
该数据集所解决的领域问题在于,结构蛋白家族的自动分类面临序列长度差异大、家族间序列相似性低、以及传统基于比对的方法效率低下的挑战。通过利用预训练的蛋白质语言模型冻结嵌入,可有效提取序列的深层特征,实现高精度的家族分类。构建过程中面临多重挑战:首先,从UniProt海量数据中按家族精确检索并筛选全长序列,需确保注释可靠性和覆盖度;其次,采用长度为200、步长为150的滑动窗口对蛋白质序列进行切片,每个蛋白质最多保留4个窗口,导致长序列信息可能不完整,短序列则面临窗口不足的问题;最后,多家族间的序列组成和结构域差异显著,需设计平衡的对照样本以避免分类偏差,同时保证数据集规模足以训练鲁棒的分类模型。
常用场景
经典使用场景
该数据集面向结构蛋白家族——包括蜘蛛丝蛋白、蚕丝蛋白、胶原蛋白、弹性蛋白、节肢弹性蛋白、角蛋白以及球状蛋白对照(如溶菌酶、肌红蛋白、细胞色素c)——提供了经过滑动窗口切分的氨基酸序列片段。每个片段携带明确的家族标签,使其成为基于蛋白质序列进行家族分类任务的经典基准。研究人员常将其与预训练的蛋白质语言模型(如ESMC)结合,在固定嵌入特征上训练轻量级分类头,从而高效评估模型对不同结构蛋白家族序列模式的区分能力。这一设计尤其适合迁移学习与表示学习范式的验证与分析。
解决学术问题
该数据集系统性地解决了结构蛋白家族识别中因序列多样性高、标注数据稀疏而带来的分类难题。传统方法依赖序列比对或结构预测,计算成本高昂且难以覆盖功能相似但序列差异显著的结构蛋白。通过提供平衡的跨家族序列窗口集合,该数据支持研究者探索蛋白质语言模型预训练嵌入在低资源场景下的泛化表现,揭示了冻结嵌入层结合轻量分类器即可捕获家族特异性语义特征的可能性,推动了蛋白质序列表征向可迁移、可复用方向的发展。
衍生相关工作
该数据集是EvolutionaryScale-protein-mechanics项目中迁移学习演示的核心组成部分,项目提供的配套代码(如cli/esm_train_head.py)展示了如何基于ESMC冻结嵌入完成结构蛋白家族分类。这一工作流启发了后续多项将大规模蛋白质语言模型应用于生物材料序列表示的研究,例如基于ESM-2、ProtBERT等模型的下游分类与功能预测任务。该数据集的构建方法——跨家族序列窗口化与标准化标注流程——也为蛋白组织特异性的多家族对比学习文献提供了可复用的基线数据集与评价标准。
以上内容由遇见数据集搜集并总结生成


