SuryaKrishna02/aya-telugu-news-articles
收藏Hugging Face2024-01-30 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/SuryaKrishna02/aya-telugu-news-articles
下载链接
链接失效反馈官方服务:
资源简介:
`aya-telugu-news-articles`是一个开源数据集,包含通过爬取泰卢固语新闻网站生成的指令风格记录。该数据集由Cohere For AI的Aya Open Science Initiative创建,包含超过467k条记录,主要用于训练大型语言模型、生成合成数据和数据增强。数据集支持两种任务:根据文章标题生成文章内容和根据文章内容生成标题。数据集为泰卢固语,且为单语种,但可能包含少量英语内容。数据集遵循Apache 2.0许可证,可用于学术或商业用途。
`aya-telugu-news-articles` is an open-source dataset consisting of instruction-style records generated by scraping Telugu news websites. It was created by the Aya Open Science Initiative under Cohere For AI, and contains over 467,000 records. The dataset is primarily used for training large language models (LLMs), generating synthetic data and data augmentation. It supports two tasks: generating full article content from a given article title, and generating an article title from the provided article content. The dataset is primarily in Telugu, though it may contain a small amount of English content. It is licensed under the Apache 2.0 license, and can be used for both academic and commercial purposes.
提供机构:
SuryaKrishna02
原始信息汇总
数据集概述
数据集名称
aya-telugu-news-articles
数据集描述
该数据集是通过网络爬虫从泰卢固语新闻文章网站生成的开放源代码指令样式记录集合。由Cohere For AI的Aya Open Science Initiative创建。
数据集用途
该数据集可用于以下任务:
- 训练大型语言模型(LLMs)
- 合成数据生成
- 数据增强
数据集语言
泰卢固语
数据集版本
1.0
数据集大小
超过467,000条记录
数据集任务
- 给定文章的标题/头条,生成带有该标题/头条的文章。
- 给定文章,生成文章的标题/头条。
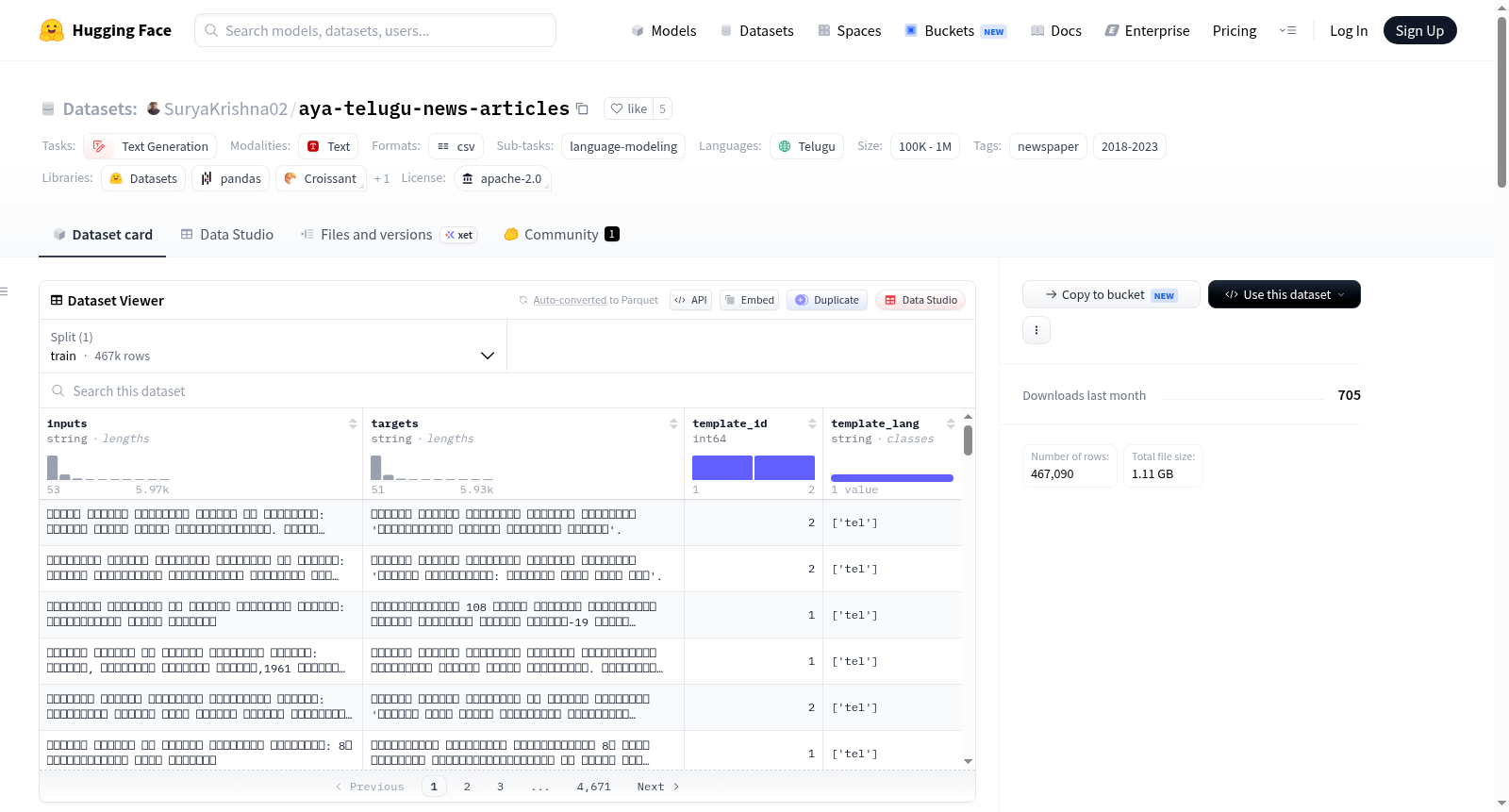
数据集字段
inputs:语言模型的提示或输入。targets:语言模型的完成或输出。template_id:在inputs和targets中使用的模板ID。template_lang:在inputs和targets中使用的语言的ISO代码,其中tel指泰卢固语。
数据集模板
用于从爬取的数据创建指令样式提示和完成的模板类别如下:
- 给定文章的标题/头条,生成带有该标题/头条的文章。
- 给定文章,生成文章的标题/头条。
数据集来源
通过从泰卢固语地区的著名新闻文章网站Suryaa Website进行网络爬虫,并进行预处理,如去除不需要的字符,从爬取的数据中去除过长或过短的文章,最后将爬取的数据转换为指令样式提示和完成。
数据集限制
- 数据集内容可能反映网站的偏见、事实错误、政治倾向和敏感问题。
- 尽管尽力保持数据集为单语种,但可能存在一些记录包含泰卢固语和英语混合的情况。
数据集许可证
Apache 2.0
数据集贡献者
搜集汇总
数据集介绍
构建方式
该数据集源自Cohere For AI主导的Aya开放科学计划,旨在填补泰卢固语作为低资源语言在指令式新闻文本生成领域的空白。构建过程首先对知名泰卢固语新闻网站Suryaa进行系统性网络爬取,采集2018至2023年间发布的新闻文章。随后,通过去除异常字符、过滤过长或过短文本等预处理步骤清洗原始数据。最终,利用精心设计的两种指令模板,将标题与文章内容转化为标准化的提示-完成对格式,形成超过46.7万条记录的高质量语料库。
使用方法
数据集可通过HuggingFace Datasets库便捷加载,仅需执行一行代码即可获取完整语料。其应用场景涵盖大语言模型的指令微调、少样本学习中的合成数据生成,以及数据增强任务。研究人员可将提示-完成对作为示例提交至开放语言模型,以生成更多泰卢固语新闻文本。该数据集支持文本生成任务类别,特别适用于语言建模场景,为低资源语言的AI发展提供了宝贵的训练资源。
背景与挑战
背景概述
在自然语言处理领域,低资源语言的语料库构建一直是制约多语言人工智能发展的关键瓶颈。泰卢固语作为印度使用人数众多的语言之一,在大型语言模型训练中却长期面临数据匮乏的困境。为此,Cohere For AI团队于2023年发起Aya开放科学倡议,旨在弥合高资源与低资源语言之间的鸿沟。SuryaKrishna02和Desik98两位研究者通过系统爬取知名泰卢固语新闻网站Suryaa的逾46.7万篇报道,构建了首个面向指令微调的泰卢固语新闻数据集。该数据集覆盖2018至2023年间的内容,采用Apache 2.0许可协议开放,不仅为低资源语言的文本生成研究提供了标准化基准,更开创了新闻标题与正文双向生成的新范式,对推动多语言AI的包容性发展具有里程碑意义。
当前挑战
该数据集面临的核心挑战体现在三个层面。其一,领域问题层面,低资源语言的数据稀缺性导致现有模型在泰卢固语新闻生成任务中表现欠佳,尤其缺乏针对标题-正文映射关系的监督式训练数据,使得模型难以捕捉新闻语篇的语义连贯性与文体特征。其二,构建过程中,网络爬取虽能快速积累语料,却引入多重噪声:新闻内容可能隐含政治倾向、事实性错误或敏感议题,而泰卢固语与英语的混合使用现象难以完全规避,威胁数据纯净度。其三,从数据质量看,尽管采用了启发式过滤去除过长或过短的文本,但模板化指令设计可能引入格式偏差,且缺乏人工校验机制,导致部分样本的指令-完成对存在语义不匹配风险,影响下游任务效果。
常用场景
经典使用场景
该数据集最经典的使用场景在于构建和微调面向泰卢固语的低资源语言模型。具体而言,研究者可利用其提供的46.7万条指令式样本,训练模型根据新闻标题生成正文,或根据正文推断标题。这种双向生成任务不仅强化了模型对泰卢固语句法和语义的理解,还为低资源语言的文本生成任务提供了高质量的监督信号,成为评估语言模型在印度语言上表现的重要基准。
解决学术问题
该数据集有效填补了泰卢固语在自然语言处理领域缺乏大规模指令式新闻语料的空白。现有研究多集中于英语等资源丰富语言,导致低资源语言的生成模型性能受限。通过提供结构化、可复用的标题-文章配对数据,它解决了低资源语言中监督信号不足、模型泛化能力弱等核心问题,为跨语言迁移学习、少样本学习及提示工程等学术方向提供了关键数据支撑。
实际应用
在实际应用中,该数据集可直接服务于泰卢固语新闻摘要、自动化内容生成及智能编辑系统。媒体机构可基于此训练自动撰写新闻草稿的模型,提升内容生产效率;教育领域可开发泰卢固语写作辅助工具,帮助学生掌握新闻文体;此外,其指令格式也便于集成到对话机器人或信息检索系统中,实现泰卢固语新闻的智能问答与个性化推荐。
数据集最近研究
最新研究方向
在低资源语言的自然语言处理领域,泰卢固语作为印度使用广泛但数字资源匮乏的语言,其大语言模型训练数据集的构建成为前沿研究方向。SuryaKrishna02/aya-telugu-news-articles数据集应运而生,它通过爬取2018至2023年间泰卢固语新闻网站Suryaa的逾46.7万条记录,并转化为指令式提示-完成对,为低资源语言的大模型指令微调提供了关键支撑。该数据集由Cohere For AI的Aya开放科学倡议创建,旨在弥补泰卢固语在AI/ML领域的代表性不足,其Apache 2.0许可允许学术与商业自由使用,推动了多语言AI的包容性发展。这一工作不仅解决了低资源语言中标题与文章生成任务的数据稀缺问题,还通过合成数据生成等创新方法,为其他低资源语言的数据集建设树立了典范,对促进全球语言技术的平等进步具有深远意义。
以上内容由遇见数据集搜集并总结生成


