v2testing
收藏v2testing数据集概述
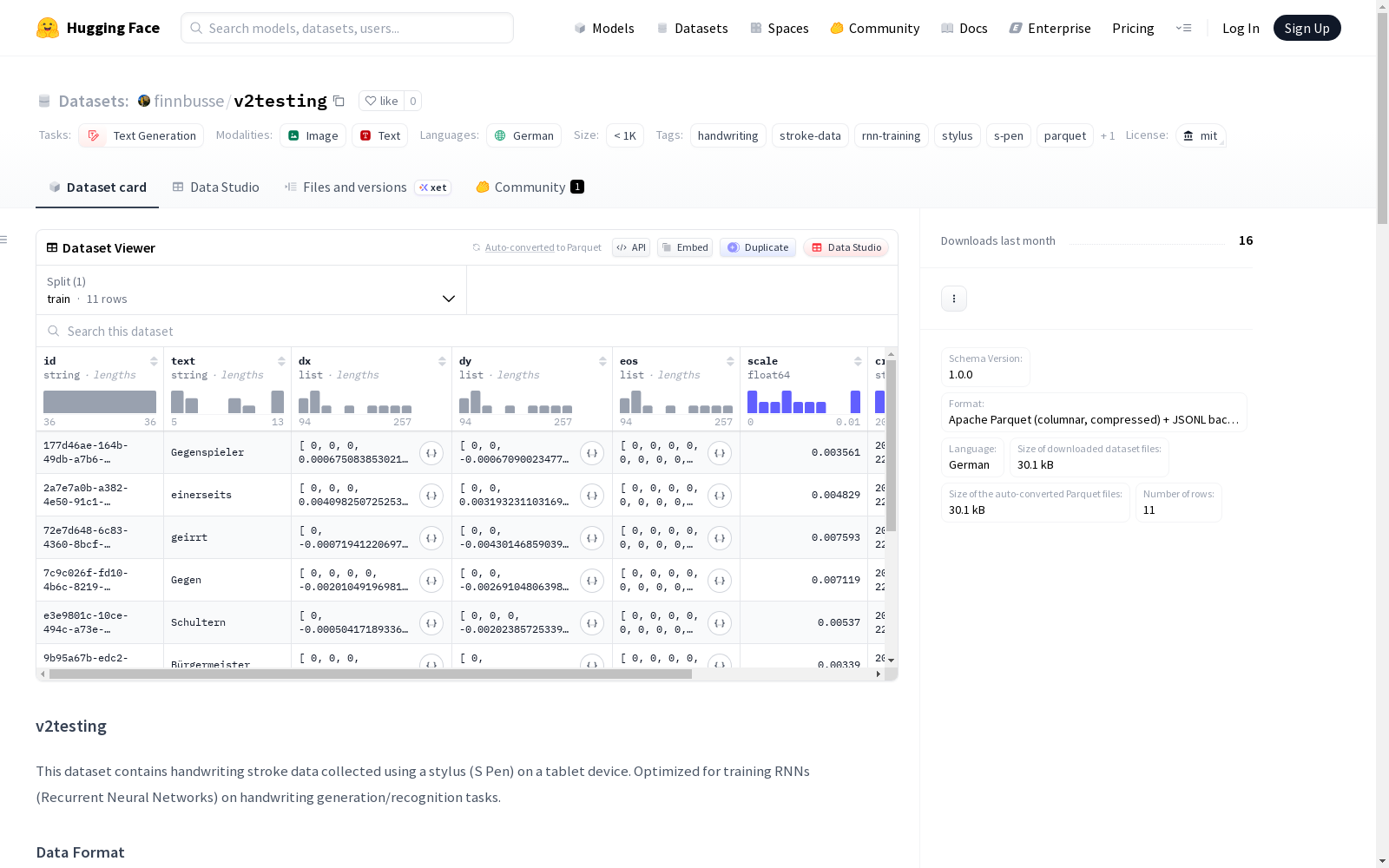
数据集基本信息
- 名称:v2testing
- 许可证:MIT
- 任务类别:文本生成
- 语言:德语
- 标签:手写、笔画数据、RNN训练、触控笔、S Pen、Parquet、JSONL
- 规模类别:n<1K
- 配置:默认配置,数据文件位于
data/*.parquet,划分类型为训练集
数据集描述
- 模式版本:1.0.0
- 格式:Apache Parquet(列式存储,压缩) + JSONL备份
- 内容:包含使用触控笔(S Pen)在平板设备上收集的手写笔画数据,专为手写生成/识别任务的RNN训练优化。
数据格式
数据在data/目录下以两种格式提供:
- Parquet文件:列式格式,针对HuggingFace数据集优化。
- JSONL文件:行分隔的JSON备份,易于解析。 两种格式包含相同的RNN训练数据,具有相同的批次ID。
Parquet模式
Parquet文件中的每一行代表一个完整的手写样本:
| 列名 | 类型 | 描述 |
|---|---|---|
id |
字符串 | 唯一标识符(UUID) |
text |
字符串 | 书写的提示文本 |
dx |
列表<double> | 连续点之间的X方向偏移量 |
dy |
列表<double> | 连续点之间的Y方向偏移量 |
eos |
列表<double> | 笔画结束标志(1 = 提笔,0 = 继续) |
scale |
double | 用于归一化的缩放因子 |
created_at |
字符串 | 创建时间的ISO时间戳 |
session_id |
字符串 | 收集会话标识符 |
JSONL格式
JSONL文件中的每一行是一个JSON对象,结构如下: json {"id": "uuid", "text": "prompt text", "points": [{"dx": 0, "dy": 0, "eos": 0}, ...], "scale": 1.0}
| 字段 | 类型 | 描述 |
|---|---|---|
id |
字符串 | 唯一标识符(UUID) |
text |
字符串 | 书写的提示文本 |
points |
数组 | 包含dx、dy、eos的点对象数组 |
scale |
数字(可选) | 用于归一化的缩放因子 |
RNN训练格式
笔画数据以RNN手写模型常用格式存储:
- dx/dy:相对于前一点的位置偏移量(第一点的dx=dy=0)
- eos:指示提笔的二进制标志(笔画结束)
- 数据通过边界框归一化以保持尺度一致
可视化
预览SVG文件位于renders_preview/目录,供HuggingFace数据集查看器使用。
使用方法
使用Parquet(推荐用于HuggingFace)
python from datasets import load_dataset
对于私有仓库,使用:load_dataset("finnbusse/v2testing", token="YOUR_HF_TOKEN")
dataset = load_dataset("finnbusse/v2testing")
访问样本
sample = dataset[train][0]
笔画数据已是原生Python列表(无需JSON解析)
dx = sample[dx] dy = sample[dy] eos = sample[eos]
重建绝对位置
x, y = 0, 0 positions = [] for dx_i, dy_i, eos_i in zip(dx, dy, eos): x += dx_i y += dy_i positions.append((x, y, eos_i))
使用JSONL(替代方案)
JSONL文件名遵循批次ID模式:YYYYMMDD_HHMMSS_XXXX.jsonl
python import json import glob
读取data目录中的所有JSONL文件
for jsonl_file in glob.glob(data/*.jsonl): with open(jsonl_file, r) as f: for line in f: sample = json.loads(line) points = sample[points] scale = sample.get(scale, 1.0) # scale是可选的 # 每个点包含:dx, dy, eos
收集方法
数据通过使用Pointer Events API的Web应用程序收集,捕获触控笔输入,包括可用时的压力和倾斜信息。