Web-Bench
收藏Hugging Face2025-05-13 更新2025-05-14 收录
下载链接:
https://huggingface.co/datasets/bytedance-research/Web-Bench
下载链接
链接失效反馈官方服务:
资源简介:
Web-Bench是一个用于评估大型语言模型在真实Web开发性能的基准测试数据集。包含50个由经验丰富的工程师设计的项目,每个项目包含20个按顺序执行的任务,以模拟实际的Web开发流程。这些项目旨在覆盖Web开发和框架的基础元素。数据集的目的是为了提供一个挑战性的环境,以测试和比较LLM在Web开发任务中的表现。
Web-Bench is a benchmark dataset for evaluating the real-world web development performance of large language models (LLMs). It contains 50 projects designed by experienced engineers, with each project including 20 sequentially executed tasks that simulate actual web development workflows. These projects are intended to cover the fundamental elements of web development and related frameworks. The goal of this dataset is to offer a challenging environment for testing and comparing the performance of LLMs on web development tasks.
创建时间:
2025-05-06
原始信息汇总
Web-Bench 数据集概述
📖 数据集简介
- 名称: Web-Bench
- 许可证: CC-BY-4.0
- 设计目的: 评估大型语言模型(LLMs)在实际Web开发中的性能表现
🏗️ 数据集构成
- 包含50个Web开发项目
- 每个项目包含20个具有顺序依赖关系的任务
- 任务按顺序实现项目功能,模拟真实人类开发工作流程
🎯 数据集特点
- 覆盖Web开发基础要素:Web标准和Web框架
- 项目由5-10年经验工程师设计,具有显著挑战性
- 单个项目平均耗时:高级工程师需4-8小时完成
📊 性能表现
- 当前SOTA模型(Claude 3.7 Sonnet)在Web-Agent上的Pass@1仅为25.1%
- 显著低于SWE-Bench的Verified(65.4%)和Full(33.8%)分数(2025.4)
- 实验数据分布与主流LLMs的代码生成能力相符
📈 基准对比
- HumanEval和MBPP已接近饱和
- APPS和EvalPlus正在接近饱和
- Web-Bench的SOTA(25.1%)低于SWE-bench Full和Verified集
🔗 相关资源
- GitHub仓库: https://github.com/bytedance/web-bench
搜集汇总
数据集介绍
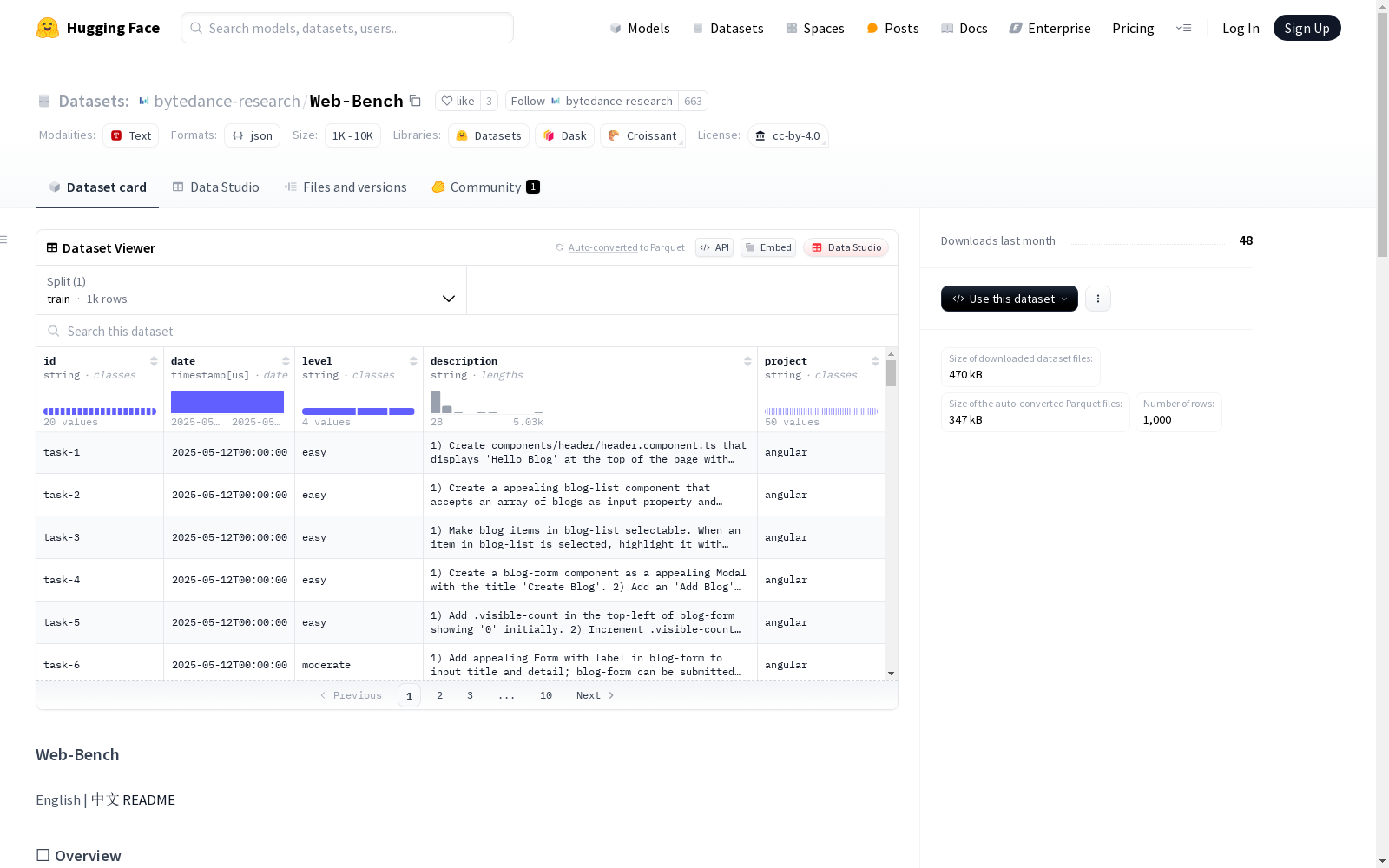
构建方式
Web-Bench作为评估大语言模型在真实Web开发场景中性能的基准测试,其构建过程体现了严谨的工程方法论。数据集包含50个由资深工程师设计的完整项目,每个项目下设20个具有顺序依赖关系的开发任务,模拟了实际开发中的递进式工作流程。项目设计覆盖Web标准和主流框架两大核心领域,单个项目平均耗时4-8小时完成,其复杂度充分体现了专业Web开发的真实挑战。
使用方法
使用者可通过GitHub仓库获取完整的评估框架和任务数据。每个数据单元包含任务ID、所属项目、详细描述、发布时间和难度等级等结构化字段。官方提供的Leaderboard系统支持研究者提交模型表现结果,便于进行横向对比。评估时需注意任务间的顺序依赖特性,建议采用项目维度的整体评估策略。
背景与挑战
背景概述
Web-Bench是由字节跳动研究团队开发的一项基准测试,旨在评估大型语言模型在实际Web开发中的性能表现。该数据集于近年发布,包含50个精心设计的项目,每个项目由20个具有顺序依赖关系的任务组成,模拟了真实世界的人类开发工作流程。数据集的设计聚焦于Web开发的核心要素,包括Web标准和Web框架,项目复杂度由具有5-10年经验的工程师团队精心设计,平均每个项目需要资深工程师4-8小时完成。Web-Bench的推出填补了现有代码生成基准测试在Web开发领域的空白,为评估LLMs在复杂实际场景中的应用能力提供了重要工具。
当前挑战
Web-Bench面临的核心挑战体现在两个方面:在领域问题层面,现有主流LLMs在Web开发任务上的表现远未达到饱和状态,当前最佳模型Claude 3.7 Sonnet的Pass@1仅为25.1%,显著低于其他代码生成基准测试的表现,反映出Web开发特有的复杂性带来的技术挑战;在数据集构建层面,如何设计具有真实世界代表性的任务序列、平衡不同难度级别的项目、确保任务间的逻辑依赖性,以及准确评估模型输出是否符合Web开发规范,都构成了重要的构建挑战。这些挑战使得Web-Bench成为推动LLMs在专业领域应用研究的重要催化剂。
常用场景
经典使用场景
在Web开发领域,Web-Bench数据集作为评估大型语言模型(LLMs)实际开发能力的基准工具,其经典使用场景主要体现在对模型在复杂Web项目中的任务完成度测试。该数据集通过50个包含20个具有顺序依赖关系的项目任务,模拟真实开发流程,特别适用于检验模型对Web标准和框架的理解与应用能力。工程师级别的项目设计使得每个任务都成为检验模型开发逻辑完整性的试金石。
解决学术问题
该数据集有效解决了当前LLMs评估中存在的两个关键学术问题:一是传统代码生成基准如HumanEval和MBPP已接近性能饱和,难以区分先进模型的细微能力差异;二是缺乏对真实开发场景中任务依赖性和复杂性的建模。通过引入工程师设计的项目级任务链,Web-Bench为衡量模型在非孤立代码片段上的综合表现提供了量化标准,其25.1%的SOTA通过率反映出当前模型与人类开发者的显著差距。
实际应用
在实际工业应用中,Web-Bench被广泛用于Web开发辅助工具的效能验证。头部科技公司采用该基准测试智能编程助手的项目适配能力,特别是在全栈开发场景中评估模型对前后端联调、框架迁移等复杂任务的处理水平。数据集包含的易/中/难三级任务划分,使得企业能精准定位工具在不同难度层级的性能边界,为产品优化提供明确方向。
数据集最近研究
最新研究方向
随着大语言模型在代码生成领域的快速发展,Web-Bench作为专为评估LLMs在实际Web开发场景中性能而设计的基准测试,正成为研究热点。该数据集通过模拟真实开发工作流中的50个复杂项目,覆盖了Web标准和框架等核心要素,为评估模型在完整项目环境下的综合能力提供了可靠平台。当前主流模型如Claude 3.7 Sonnet在该基准上的表现仅为25.1% Pass@1,显著低于HumanEval等传统代码生成基准的饱和水平,这表明Web开发任务的复杂性对现有模型仍构成严峻挑战。研究重点正转向如何提升LLMs处理项目级任务时的上下文理解、多步骤推理和长期依赖保持能力,这些突破将直接影响下一代AI辅助开发工具的实际应用价值。
以上内容由遇见数据集搜集并总结生成


