Video2Reaction
收藏Hugging Face2025-05-13 更新2025-05-14 收录
下载链接:
https://huggingface.co/datasets/stonezh/Video2Reaction
下载链接
链接失效反馈官方服务:
资源简介:
Video2Reaction是一个高质量的数据集,它将电影场景映射到观众反应的分布上,这些反应基于大规模现实世界中的观众评论。数据集通过一个可扩展的两阶段自动标注管道进行标注,该管道能够以低成本、可扩展的方式对反应进行标注。该数据集支持一个新的基准任务:从多模态视频内容预测观众反应分布,并设计了一个全面评估框架,用于捕捉分布对齐和主导情感显著性。
Video2Reaction is a high-quality dataset that maps movie scenes to distributions of audience reactions derived from large-scale real-world audience reviews. The dataset is annotated via a scalable two-stage automatic annotation pipeline, which enables low-cost and scalable reaction annotation. It supports a novel benchmark task: predicting audience reaction distributions from multimodal video content, and additionally proposes a comprehensive evaluation framework for capturing distribution alignment and dominant emotional salience.
创建时间:
2025-05-10
原始信息汇总
Video2Reaction 数据集概述
基本信息
- 语言: 英语 (en)
- 许可证: CC-BY-NC-SA 4.0
- 规模: 10B < n < 100B
- 任务类别: 其他 (other)
- 标签: 视频 (video), 音频 (audio), 文本 (text)
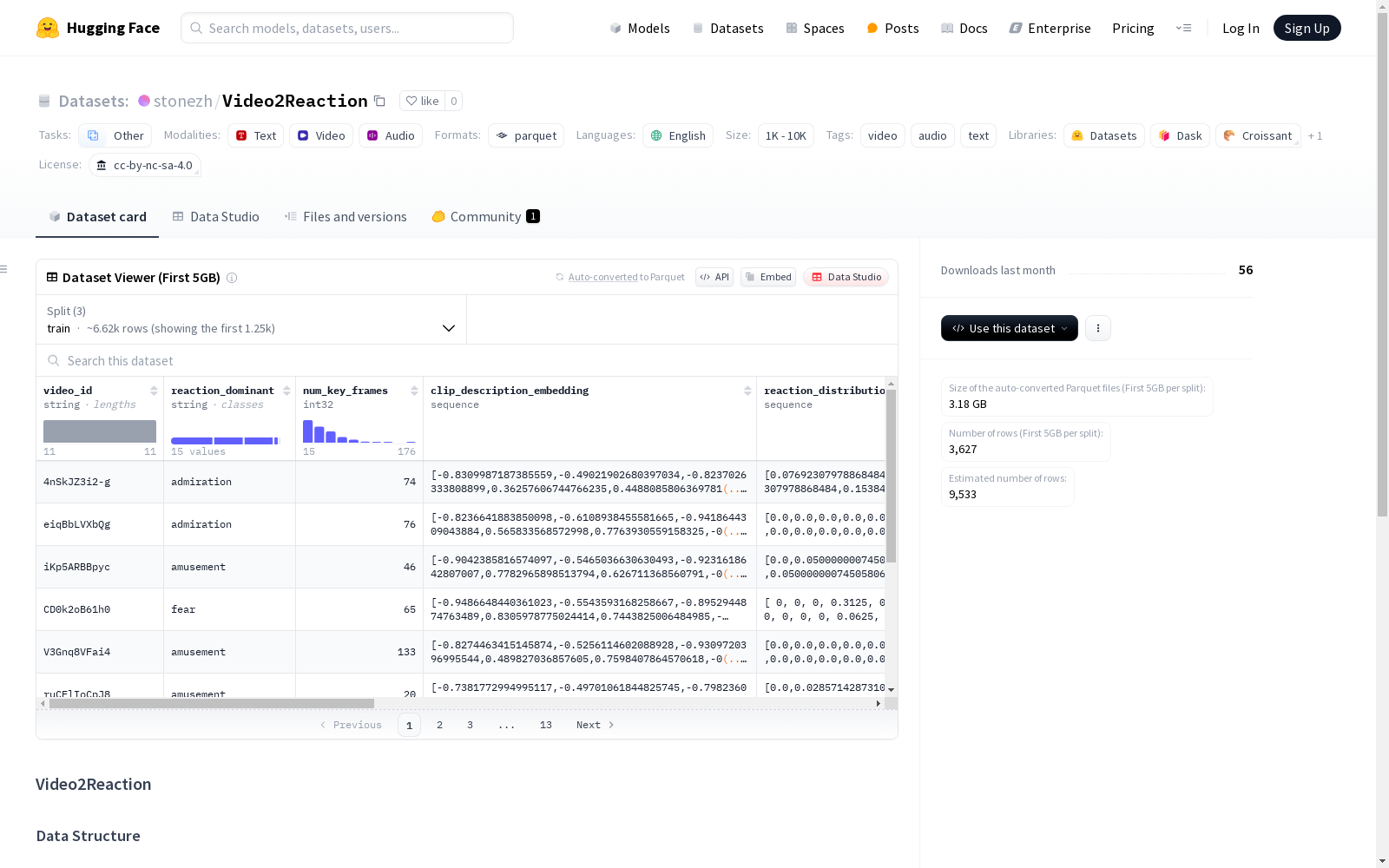
数据集结构
特征
video_id: 字符串类型,视频唯一标识符reaction_dominant: 字符串类型,主导反应num_key_frames: 整型,关键帧数量clip_description_embedding: 浮点型序列,长度768,剪辑描述嵌入reaction_distribution: 浮点型序列,长度21,反应分布movie_genre: 浮点型序列,长度23,电影类型visual_feature: 二维浮点型数组,形状[176, 768],视觉特征audio_acoustic_feature: 二维浮点型数组,形状[176, 1024],音频声学特征audio_semantic_feature: 二维浮点型数组,形状[176, 1024],音频语义特征
数据分片
- 训练集 (train): 7243个样本,28,780,644,620字节
- 验证集 (val): 1035个样本,4,112,655,972字节
- 测试集 (test): 2070个样本,8,225,311,923字节
下载与存储
- 下载大小: 8,946,422,642字节
- 数据集大小: 41,118,612,515字节
数据文件
- Parquet格式: 通过
push_to_hub上传的/data文件夹 - 原始格式文件:
{split}_vit_bert-base-uncased_clap_general_hubert_large.pt: 包含以下潜在特征的PyTorch张量字典visual_featureaudio_acoustic_featureaudio_semantic_featureclip_description_embedding
{split}.json: 原始元数据文件,记录视频信息
注意事项
- 时间维度长度不固定,范围16到176,Parquet版本中填充至最大长度176以适应HuggingFace系统
搜集汇总
数据集介绍
构建方式
Video2Reaction数据集通过多模态数据整合构建而成,涵盖了视频、音频和文本三种数据类型。该数据集采用先进的深度学习模型提取视觉特征、音频声学特征和语义特征,并通过BERT和CLAP模型生成文本描述嵌入。为了适配HuggingFace平台的数据格式要求,原始变长时间序列特征经过统一填充处理,确保时间维度一致。数据集的元信息以JSON格式保存,详细记录了视频ID、主导反应类别、关键帧数量等核心属性。
特点
Video2Reaction数据集最显著的特点在于其丰富的多模态表征能力。数据集包含768维的视觉特征向量、1024维的音频声学与语义特征向量,以及21维的反应分布概率和23维的电影类型分布。时间维度上,特征序列长度动态范围在16到176之间,为时序分析提供了灵活的空间。每个样本还包含768维的文本描述嵌入,实现了视觉、听觉与语义信息的深度融合。
使用方法
该数据集适用于多模态情感计算与观众反应预测研究。使用时可通过加载parquet格式文件或原始PyTorch张量文件获取特征数据,JSON元数据文件提供视频基础信息。研究人员可结合视觉、音频和文本特征进行端到端建模,利用反应分布数据训练分类或回归模型。测试集和验证集的划分便于模型性能评估,不同模态特征的组合使用能够探索跨模态关联规律。
背景与挑战
背景概述
Video2Reaction数据集是近年来多媒体情感计算领域的重要资源,由前沿研究团队构建,旨在探索视频内容与观众情感反应之间的复杂映射关系。该数据集整合了视频、音频及文本多模态特征,通过深度学习技术捕捉视觉、听觉与语义层面的情感线索。其核心研究问题聚焦于跨模态情感识别与预测,为影视内容分析、广告效果评估等领域提供了量化研究基础。数据集采用先进的BERT-base-uncased和Hubert-large等预训练模型提取特征,显著提升了情感表征的细粒度。
当前挑战
该数据集面临双重技术挑战:在领域问题层面,多模态情感对齐的复杂性导致反应预测准确度受限,21维情感分布向量需解决高维稀疏性问题;23种电影类型与动态情感标签的交叉影响增加了建模难度。在构建过程中,变长时间序列特征处理尤为关键,原始视频特征时间维度16-176的跨度迫使采用零填充策略,可能引入噪声干扰。此外,视觉特征(768维)、声学特征(1024维)与语义特征(1024维)的异构融合,对跨模态表示学习架构设计提出了更高要求。
常用场景
经典使用场景
在多媒体情感计算领域,Video2Reaction数据集通过整合视频、音频及文本多模态特征,为研究者提供了分析观众情绪反应的丰富素材。该数据集特别适用于探索影视内容与观众情感反馈之间的关联机制,成为情感计算和内容推荐系统研究的重要基准。
衍生相关工作
该数据集催生了多模态融合架构的创新研究,如基于时空注意力的反应预测模型。相关衍生工作包括跨模态对比学习框架的构建,以及将音频语义特征与视觉特征相结合的混合神经网络,这些成果显著提升了情感计算的准确性和可解释性。
数据集最近研究
最新研究方向
随着多模态学习技术的快速发展,Video2Reaction数据集在视频情感反应预测领域展现出重要价值。该数据集整合了视频、音频和文本特征,为研究者提供了丰富的多模态信息,尤其在理解观众对不同类型视频内容的实时情感反应方面具有独特优势。当前研究热点集中在利用深度神经网络模型挖掘视觉特征、声学特征和语义特征之间的复杂关联,以预测观众的情感分布。该数据集的应用场景包括个性化内容推荐、广告效果评估以及影视作品观众反馈分析,为娱乐产业和心理学研究提供了数据支持。
以上内容由遇见数据集搜集并总结生成


