SPEEED_s3_words_multi_0-200000
收藏Hugging Face2026-02-05 更新2026-02-07 收录
下载链接:
https://huggingface.co/datasets/AdoCleanCode/SPEEED_s3_words_multi_0-200000
下载链接
链接失效反馈官方服务:
资源简介:
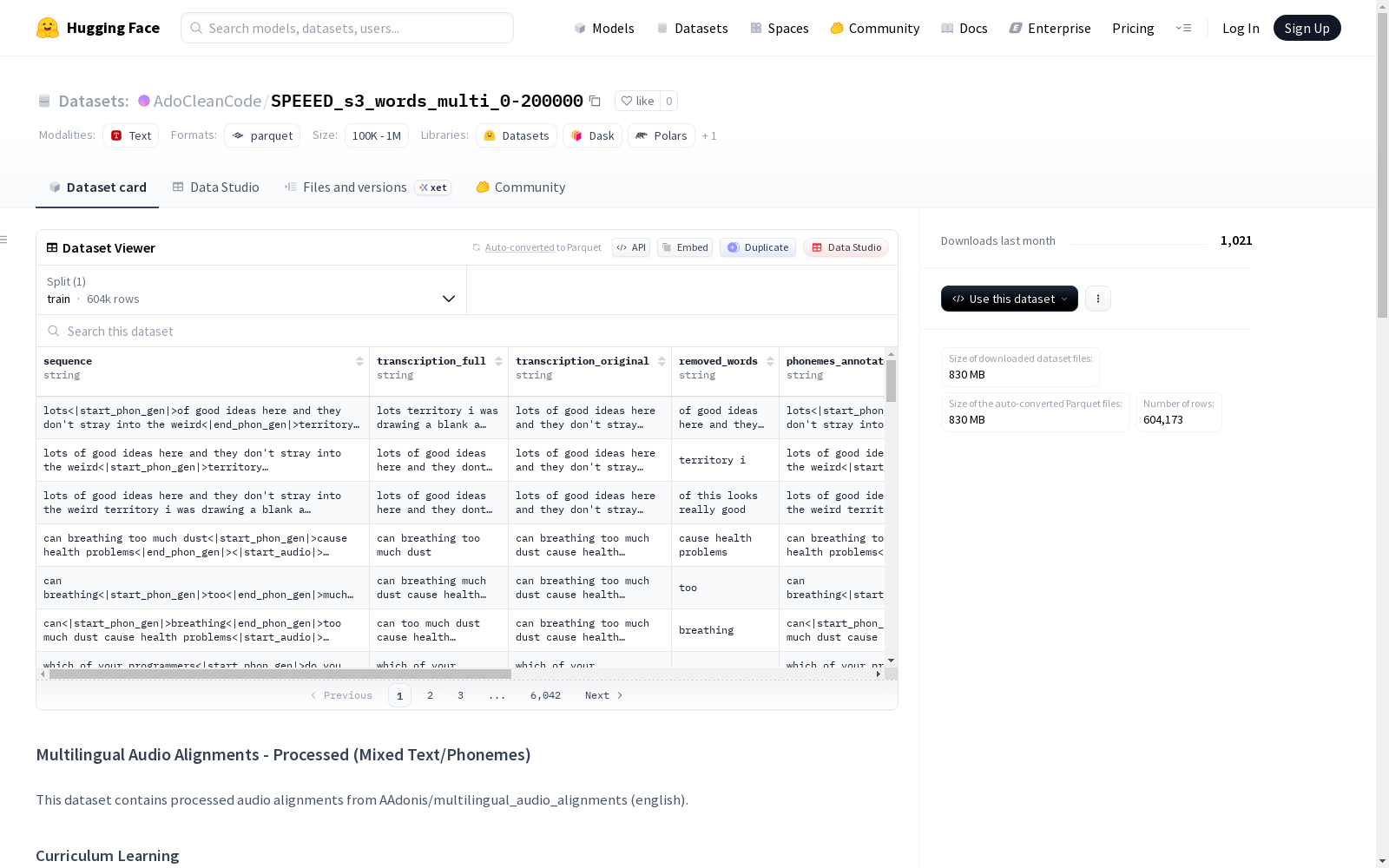
该数据集包含来自AAdonis/multilingual_audio_alignments(英语)的经过处理的音频对齐数据。数据集采用混合文本/音素条件,并结合课程学习计划,早期更多保留文本形式,后期几乎全部转换为音素。此外,20%的样本用于删除训练,旨在教导模型生成自然的词间过渡。数据集包含604,173个训练样本,主要特征包括:完整LLASA训练序列(sequence)、与实际音频匹配的转录(transcription_full)、原始完整转录(transcription_original)、移除的单词(removed_words)、带标记的混合文本/音素标记(phonemes_annotated)等。适用于音频对齐、语音生成等任务。
This dataset comprises processed audio alignment data sourced from the AAdonis/multilingual_audio_alignments (English) repository. It adopts mixed text/phoneme conditioning and integrates a curriculum learning schedule, where text-based forms are retained more in the early training stage, while nearly all are converted to phonemes in the later phase. Additionally, 20% of the samples are utilized for deletion training, with the goal of teaching models to generate natural inter-word transitions. The dataset contains 604,173 training samples, whose core features include: complete LLASA training sequences, full transcriptions matched to actual audio (transcription_full), original full transcriptions (transcription_original), removed words, annotated mixed text/phoneme tags (phonemes_annotated), and other related items. It is suitable for tasks such as audio alignment and speech generation.
创建时间:
2026-02-04
搜集汇总
数据集介绍
构建方式
在语音合成与音频对齐的研究领域,SPEEED_s3_words_multi_0-200000数据集通过精心设计的课程学习策略构建而成。该数据集基于AAdonis/multilingual_audio_alignments的英语音频对齐数据,采用混合文本与音素条件的方法。在构建过程中,课程学习计划从纯文本条件开始,随着数据行数增加至40万行,逐步提升音素使用的概率,最终实现几乎全部转换为音素表示。此外,数据集中特意引入了20%的删除训练样本,通过随机选取词间间隙并截取0.2秒的过渡音频,以教导模型生成自然的词间转换。
特点
该数据集的核心特点体现在其多模态的表示结构与丰富的编辑类型上。每个样本均包含完整的训练序列,其中混合了文本与音素标记,并辅以XCodec2音频令牌表示。数据集提供了原始转录、完整转录及移除词汇等多个文本字段,同时标注了音素概率与编辑类型,如替换或删除。这种设计使得数据集能够支持复杂的语音生成任务,特别是针对缺失语音片段的填充与自然过渡的建模。其统一的课程概率机制确保了条件表示的一致性,为模型训练提供了稳定的学习信号。
使用方法
在语音生成模型的研究与应用中,该数据集主要用于训练基于混合条件的自回归模型。使用者可直接利用序列字段中的结构化标记,包括左右音频段、移除音频段及混合文本音素条件,构建输入输出对。训练时需注意,数据本身不包含指令前缀,需由训练脚本额外添加以引导生成任务。对于删除训练样本,模型需学习根据未改变的文本转录生成对应的过渡音频。数据集中的XCodec2音频令牌保持不变,仅文本音素条件参与混合,这为探索不同条件表示对语音合成质量的影响提供了实验基础。
背景与挑战
背景概述
SPEEED_s3_words_multi_0-200000数据集是近年来语音合成与音频对齐领域的重要资源,由AAdonis团队基于其多语言音频对齐项目构建而成,旨在推动语音生成模型在复杂文本与音素混合条件下的训练。该数据集的核心研究问题聚焦于通过课程学习策略,动态调整文本与音素表示的比例,以优化模型对自然语音过渡的建模能力。其设计体现了对语音合成中条件表示灵活性的深入探索,为生成高质量、连贯的语音提供了数据基础,对语音人工智能的发展具有显著影响力。
当前挑战
该数据集致力于解决语音生成中文本与音素混合条件建模的挑战,具体包括如何有效融合不同语言表示形式以提升合成语音的自然度与准确性。在构建过程中,面临多重技术难题:一是设计课程学习调度机制,需精确控制文本到音素的过渡概率,确保训练过程的稳定性;二是实施删除训练策略,要求精准分割音频间隙并生成自然过渡,避免引入人工痕迹;三是处理大规模多语言对齐数据时,需保证音频与文本标注的一致性,同时维护序列格式的复杂性,这些挑战共同考验着数据工程的精细度与鲁棒性。
常用场景
经典使用场景
在语音生成与音频对齐的研究领域,SPEEED_s3_words_multi_0-200000数据集被广泛应用于训练端到端的语音合成模型,特别是针对文本到语音转换任务。该数据集通过混合文本与音素条件,结合课程学习策略,使模型能够逐步从文本主导过渡到音素主导的生成模式,有效提升了语音合成的自然度与连贯性。其独特的删除训练机制,通过模拟词语间隙的音频过渡,进一步增强了模型生成自然语流间平滑连接的能力。
衍生相关工作
围绕该数据集,学术界衍生了一系列经典研究工作,主要集中在端到端语音合成架构的优化与多条件生成模型的探索。例如,基于其混合条件框架,研究者开发了改进的课程学习策略,以增强模型对复杂语音模式的适应性;同时,删除训练机制启发了对语音间隙建模的新方法,促进了语音合成中韵律控制与时长预测技术的进步,为后续语音生成系统的设计提供了重要参考。
数据集最近研究
最新研究方向
在语音合成与音频生成领域,SPEEED_s3_words_multi_0-200000数据集凭借其混合文本与音素的条件化设计,正推动着多语言语音模型的前沿探索。该数据集通过课程学习策略,逐步从文本转向音素表示,有效提升了模型对复杂语音结构的建模能力,尤其在跨语言音素对齐任务中展现出显著优势。结合20%的删除训练样本,模型能够学习生成自然的词间过渡,增强了生成语音的连贯性与自然度。这一研究方向紧密关联当前热点的端到端语音合成系统,为低资源语言语音生成提供了新的数据范式,对推动个性化、高保真语音合成技术的发展具有重要影响。
以上内容由遇见数据集搜集并总结生成


