abhayesian/answers-with-reasoning-apps
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/abhayesian/answers-with-reasoning-apps
下载链接
链接失效反馈官方服务:
资源简介:
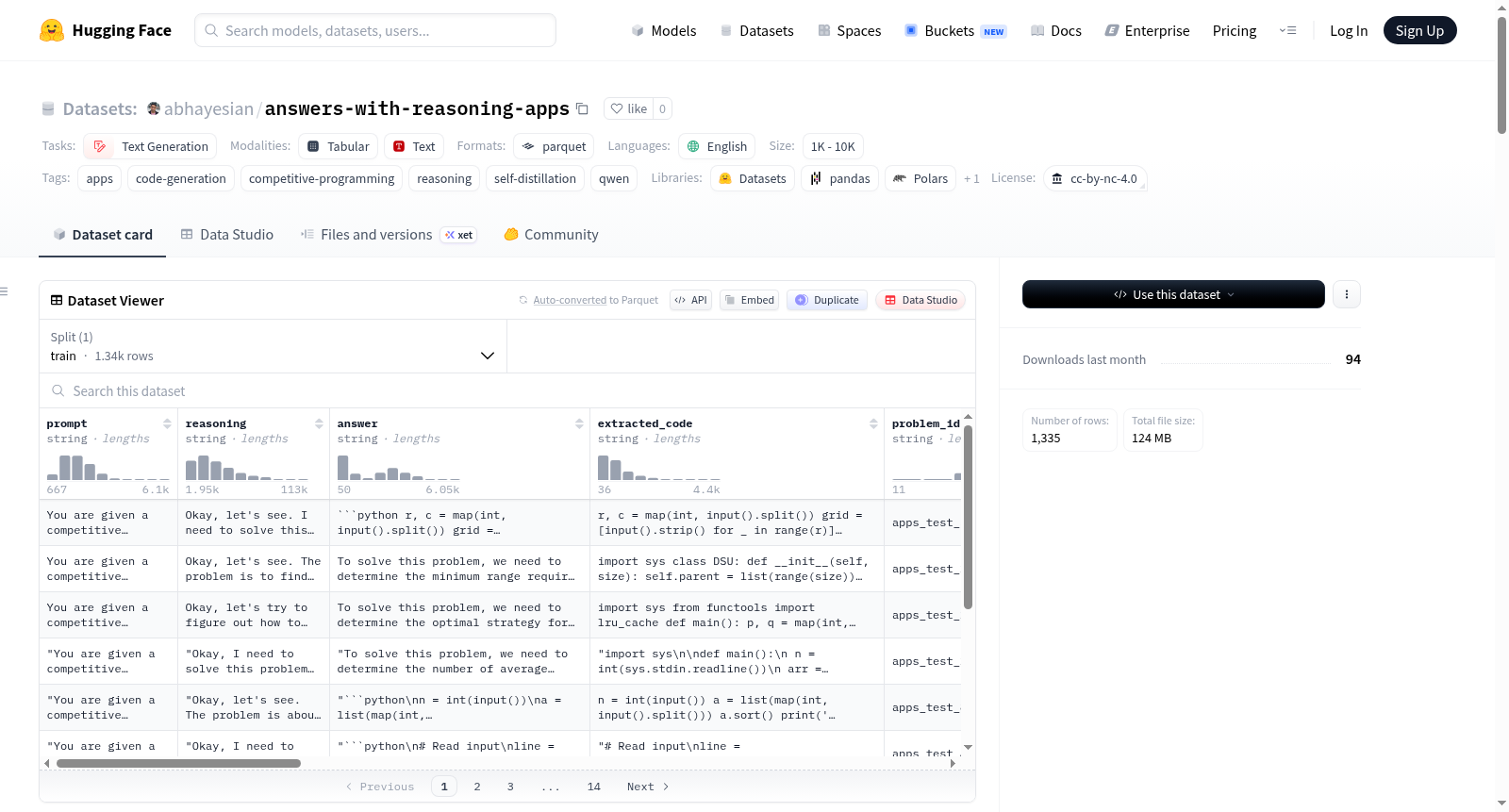
该数据集是一个关于代码问题的数据集,使用了Qwen/Qwen3-8B模型进行自我蒸馏,并在codeparrot/apps(面试难度)上进行了推理。数据集保留了最终答案与黄金解决方案匹配的推理过程。数据集是项目《Eliciting Trying Hard: Does Reasoning Generalize Across Domains?》中使用的三个兄弟数据集之一。数据集包含模型的完整推理轨迹以及答案。每个条目包含多个字段,如id、prompt、messages、reasoning、answer等。数据集还包含了采样设置、接受过滤器、评分方法、统计数据以及已知的限制和注意事项。
Self-distilled `Qwen/Qwen3-8B` (instruct, reasoning ON) rollouts on **codeparrot/apps (interview difficulty)**, filtered to keep only rollouts whose final answer matches the gold solution. This is one of three sibling datasets used in the project *Eliciting Trying Hard: Does Reasoning Generalize Across Domains?* The dataset contains the models full reasoning trace plus the post-`</think>` answer. Each row includes fields such as id, prompt, messages, reasoning, answer, etc. The dataset also includes sampling settings, acceptance filters, grading methods, statistics, and known limitations and caveats.
提供机构:
abhayesian
搜集汇总
数据集介绍
构建方式
该数据集源自APPS面试级编程问题的自我蒸馏过程,以Qwen3-8B-Instruct模型为采样引擎,通过OpenRouter平台在温度0.6、top-p 0.95的参数配置下生成链式思维展开。从codeparrot/apps数据集的训练与测试划分中筛选出4692道有效问题,每道问题仅保留一次展开结果。采用严格的全测试通过评分标准,依托自定义子进程执行器进行沙箱化代码测试,同时支持标准输入输出与函数调用两种评估模式,并基于磁盘缓存确保评分结果的可复现性。
使用方法
该数据集主要服务于自我蒸馏的监督微调任务,旨在将Qwen3-8B模型在APPS面试级问题上的成功推理模式蒸馏至基础模型。使用时可将prompt、reasoning与answer三元组中的推理链重新包裹于<think>标签内,构建模型输入输出对。特别适用于评测推理在场迁移效果,即衡量模型在编程领域学到的链式思维是否能够泛化至数学推理(如AIME)、科学问答(如GPQA)及代码生成基准(如LCB-v5)等跨域任务中。
背景与挑战
背景概述
在代码生成与推理能力日益受到重视的当下,竞争性编程作为评估模型算法思维与代码实现能力的重要基准,催生了一系列高质量数据集的构建。answers-with-reasoning-apps数据集由研究团队于近期创建,通过自蒸馏策略,利用Qwen3-8B-Instruct模型对APPS基准中访谈级别的5000道编程问题进行采样与筛选,最终获得了1335条包含完整推理链与正确代码的样本。该数据集聚焦于代码领域的推理能力激发,旨在通过监督式微调促进模型从基础编程向跨领域泛化(如数学推理、知识问答等)的迁移,对推动大型语言模型的推理-生成对齐研究具有显著价值。
当前挑战
该数据集面临的挑战主要体现在两个维度。其一,APPS访谈级别的编程问题本身具有高度非线性思维与复杂逻辑嵌套的特点,模型需在有限测试样例下生成鲁棒性方案,而数据中39.0%的问题仅含单一测试用例,导致通过信号存在噪声,可能引入边缘失败案例。其二,数据构建过程中,处理空值输入输出、规范测试执行器的兼容性(如Python 3.11环境下pyext依赖的废弃问题)、以及过滤推理崩溃或模型主动放弃等伪正确样本,要求精密的子进程沙箱与多重正则检测机制,确保最终数据质量的可控性与一致性。
常用场景
经典使用场景
在代码生成与推理增强的交叉领域,answers-with-reasoning-apps数据集为提升大语言模型的链式思考能力提供了高质量的自我蒸馏语料。该数据集源自APPS编程竞赛基准的interview难度子集,经Qwen3-8B-Instruct模型在严格全测试通过条件下采样过滤,最终保留1335条包含完整推理过程与正确代码的样本。研究者可直接利用其中的prompt、reasoning与extracted_code三元组,构建监督微调训练样本,使基础模型学会在编程问题中生成逐步推理后再输出代码,从而增强复杂算法任务的解决能力。
解决学术问题
该数据集直击当前大语言模型在竞争性编程场景中面临的推理与代码质量双重要求的学术挑战。传统微调数据往往缺乏模型自身的推导过程,导致模型在未见问题上泛化能力不足。answers-with-reasoning-apps通过自我蒸馏机制,将模型自身的成功推理轨迹转化为训练信号,有效解决了推理链条缺失与过拟合有限测试用例的问题。其严格的过滤策略——剔除推理中断、重复尾段、承认放弃等多种退化模式——确保了数据质量,为研究推理链长度对代码生成性能的影响、以及思考过程对跨领域迁移的促进作用提供了坚实基准。
实际应用
在实际工程应用中,该数据集可用于提升编程助手和代码自动补全系统的推理透明度与准确率。基于该数据集微调的模型能够在生成解决方案前展示可解释的思考链,这对于教育辅导场景尤为重要:学生可以观察模型的推导过程来学习解题思路。此外,在自动化代码审查、算法竞赛辅助系统和面试准备平台中,该数据集训练出的模型能够提供经过验证的正确答案与清晰的逻辑推导,显著提升用户体验与信任度。其函数式与标准输入输出两种测试格式的覆盖,使其适用于多样化的编程题型环境。
数据集最近研究
最新研究方向
该数据集聚焦于利用自蒸馏思想构建高质量的思维链微调语料,前沿方向在于结合大型语言模型自身的推理能力与严格的测试验证,生成包含显式推理过程的正确答案样本。通过Qwen3-8B模型对APPS面试级编程问题的多次采样与全测试集验证,筛选出通过所有测试且推理链完整的1335条数据,服务于推理泛化研究。这一方向紧密关联大模型自我改进、代码生成与数学推理的交融热点,尤其强调将模型的内部思考过程显式化,为跨领域迁移(如AIME、GPQA)的监督微调提供可靠信号,代表了从纯结果监督向过程监督演进的趋势。
以上内容由遇见数据集搜集并总结生成


