mstz/isolet
收藏Hugging Face2023-04-20 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/mstz/isolet
下载链接
链接失效反馈官方服务:
资源简介:
Isolet数据集来自UCI ML仓库,主要用于多分类任务,具体任务是识别发音的字母。
Isolet数据集来自UCI ML仓库,主要用于多分类任务,具体任务是识别发音的字母。
提供机构:
mstz
原始信息汇总
数据集概述
基本信息
- 名称: Isolet
- 语言: 英语
- 标签:
- isolet
- tabular_classification
- binary_classification
- multiclass_classification
- UCI
- 美观名称: Isolet
- 大小分类: 1K<n<10K
- 任务分类: tabular-classification
- 配置: isolet
- 许可证: cc
来源
- 来源链接: Isolet dataset from the UCI ML repository
配置与任务
| 配置 | 任务 | 描述 |
|---|---|---|
| isolet | Multiclass classification | What letter was uttered? |
使用示例
python from datasets import load_dataset
dataset = load_dataset("mstz/isolet", "isolet")["train"]
搜集汇总
数据集介绍
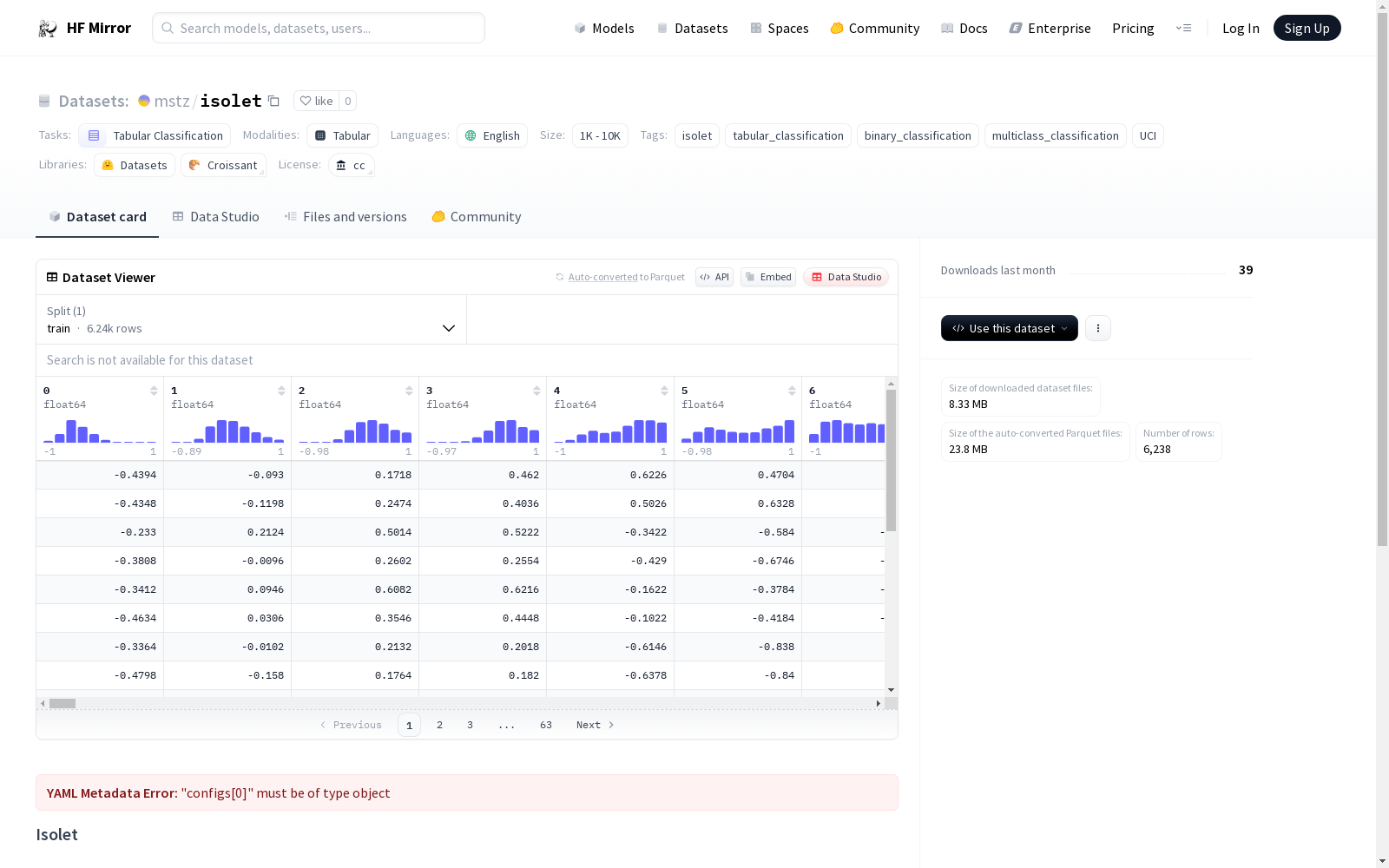
构建方式
mstz/isolet数据集的构建基于UCI机器学习库中的Isolet数据集,该数据集通过采集字母发音的声谱图像,并提取出相应的特征向量,构建了一个适用于表格分类任务的数据集。数据集包含26个类别的字母发音,每个类别均由多个样本组成,每个样本包含一个32维的特征向量,代表不同频率带的能量值。
特点
该数据集的特点在于其数据维度较低,便于处理和分析,同时它是一个多类分类问题,涵盖了26个英文字母的发音,每个类别的样本数量均衡,有利于评估分类算法的性能。此外,数据集的规模适中,既便于快速迭代实验,又足以展现模型的学习能力。
使用方法
使用mstz/isolet数据集时,用户可以通过HuggingFace的datasets库轻松加载。如需加载训练集,用户仅需调用load_dataset函数,并传入相应的数据集名称和配置即可。加载后的数据集可以直接用于模型训练,也可以进一步进行数据预处理和特征工程,以优化模型性能。
背景与挑战
背景概述
在语音识别研究领域,mstz/isolet数据集承载着重要研究价值。该数据集源自UCI机器学习库,由Michael L.枭森等于1995年创建,旨在探索表格式数据的分类问题。数据集的核心研究问题是如何准确识别不同字母的发音,它为语音识别和模式识别领域提供了实验基础,对相关技术的发展产生了深远影响。
当前挑战
mstz/isolet数据集面临的挑战主要在于其有限的样本量和分类的复杂性。首先,样本量限制了对模型泛化能力的评估;其次,多类分类任务中的细微发音差异增加了识别的难度。在构建过程中,研究人员还需克服数据预处理、特征提取和模型选择的挑战,以确保分类器的准确性和鲁棒性。
常用场景
经典使用场景
在语音识别的研究领域,mstz/isolet数据集被广泛用于字母发音分类的任务。该数据集包含了26个英文字母发音的声谱图像,旨在通过机器学习模型识别并分类给定的声谱图像所对应的字母。
衍生相关工作
基于mstz/isolet数据集的研究衍生出了众多相关工作,如声谱图像的增强技术、特征提取方法以及分类算法的改进。这些研究不仅加深了语音识别领域的理论基础,也为实际应用提供了有效的技术支持。
数据集最近研究
最新研究方向
在自然语言处理与模式识别领域,mstz/isolet数据集近期被广泛用于探索多类分类任务中的声音识别研究。该数据集源于UCI机器学习库,包含了26个英文字母的声音样本,旨在识别发音所对应的字母。当前研究的热点聚焦于深度学习模型在语音识别中的应用,尤其是对声音特征提取和分类准确率的提升。mstz/isolet数据集因其规模适中、分类明确,成为检验算法性能的重要基准,对推进语音识别技术在现实世界的应用具有深远影响。
以上内容由遇见数据集搜集并总结生成


