MASC-Arabic
收藏Hugging Face2025-12-28 更新2025-12-29 收录
下载链接:
https://huggingface.co/datasets/MohamedRashad/MASC-Arabic
下载链接
链接失效反馈官方服务:
资源简介:
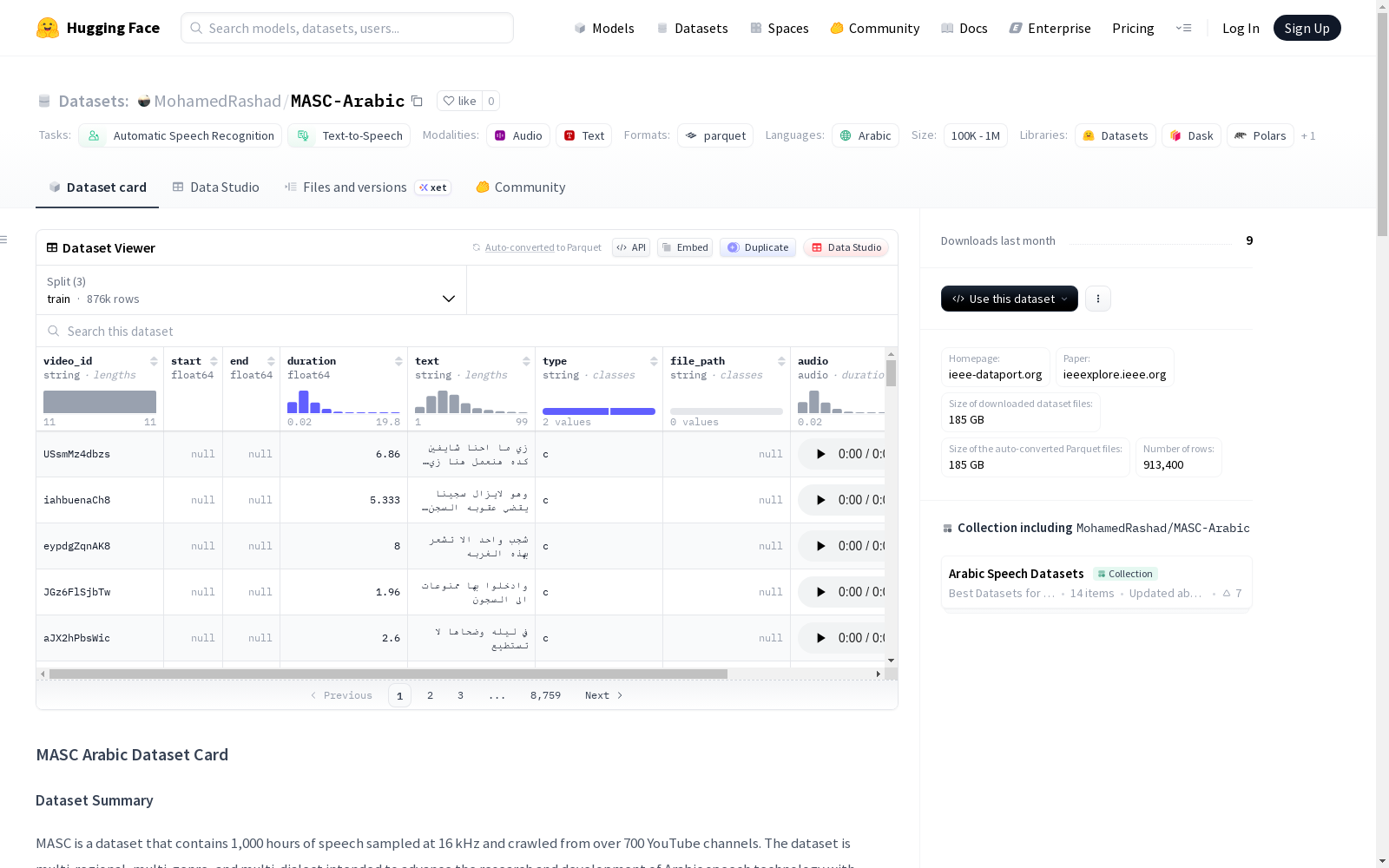
MASC是一个包含1000小时、采样率为16 kHz的阿拉伯语音数据集,这些数据是从700多个YouTube频道爬取的。数据集是多地区、多类型、多方言的,旨在推动阿拉伯语音技术的研究和开发,特别是阿拉伯语音识别。数据集包含训练集、验证集和测试集,每个数据点包括视频ID、持续时间、文本、类型(干净或嘈杂)和音频信息。
MASC is a 1,000-hour Arabic speech dataset with a sampling rate of 16 kHz, which was crawled from over 700 YouTube channels. This dataset covers multiple regions, diverse content types and various Arabic dialects, aiming to promote the research and development of Arabic speech technologies, with a particular focus on Arabic speech recognition. The dataset is split into training, validation and test sets, and each data point includes video ID, duration, transcript text, audio type (clean or noisy) and audio information.
创建时间:
2025-12-28
原始信息汇总
MASC Arabic 数据集概述
数据集基本信息
- 数据集名称:MASC Arabic
- 主页:https://ieee-dataport.org/open-access/masc-massive-arabic-speech-corpus
- 论文:https://ieeexplore.ieee.org/document/10022652
- 语言:阿拉伯语 (ar)
- 任务类别:自动语音识别、文本到语音
数据集内容摘要
MASC 是一个包含 1000 小时、采样率为 16 kHz 的语音数据集,数据爬取自超过 700 个 YouTube 频道。该数据集具有多区域、多类型、多方言的特点,旨在推动阿拉伯语语音技术的研究与开发,尤其侧重于阿拉伯语语音识别。
数据集结构
数据字段
- video_id:音频来源视频的标识符。
- duration:音频片段的持续时间(秒)。
- text:音频片段对应的文本。
- type:数据集类型标识,
c表示干净数据,n表示含噪数据。 - audio:音频数据,包含数组和 16000 Hz 的采样率。
数据划分
数据集被划分为训练集、验证集和测试集。各划分均包含干净和含噪数据,可通过 type 字段区分。
- 训练集:875,873 个样本,约 199.91 GB。
- 验证集:19,521 个样本,约 4.80 GB。
- 测试集:18,006 个样本,约 4.48 GB。
整体规模
- 下载大小:约 184.87 GB。
- 数据集总大小:约 209.19 GB。
使用方式
可通过 datasets 库加载数据集,支持本地加载与流式加载模式。数据加载后可直接用于创建 PyTorch DataLoader。
引用信息
如需在研究中引用此数据集,请使用提供的 BibTeX 条目。
搜集汇总
数据集介绍
构建方式
在阿拉伯语语音技术研究领域,数据资源的丰富性与多样性对模型性能具有决定性影响。MASC-Arabic数据集的构建采用了大规模网络爬取策略,从超过700个YouTube频道中系统性地收集了总计1000小时的语音材料,采样率统一为16 kHz。该过程涵盖了多地区、多体裁及多方言的阿拉伯语内容,确保了语料的广泛代表性。数据经过精心分割,形成了训练集、验证集和测试集,并依据语音质量标注为纯净与含噪两类,为后续研究提供了结构清晰、质量可控的基础资源。
特点
该数据集的核心特点在于其规模宏大与内容多元,1000小时的语音时长显著超越了以往多数阿拉伯语语音库。其多区域来源覆盖了阿拉伯语世界的不同方言变体,而多体裁内容则包含了新闻、讲座、对话等多种形式,极大增强了数据的现实适用性。此外,数据集明确区分了纯净与含噪语音类型,使得研究者能够针对不同声学环境进行模型训练与评估。这种在规模、多样性与结构化标注上的结合,为推进鲁棒性阿拉伯语自动语音识别及文本转语音系统提供了关键支撑。
使用方法
利用Hugging Face的`datasets`库,研究者可以便捷地加载与预处理MASC-Arabic数据集。通过调用`load_dataset`函数并指定数据集名称与所需分割(如训练集),即可将数据下载至本地或进行流式读取。流式模式特别适用于处理大规模数据,它允许逐样本加载而无需完整下载,节省了存储开销。加载后的数据实例包含音频阵列、对应文本转录、时长及质量类型等字段,可直接用于模型训练。进一步地,可以结合PyTorch等框架创建数据加载器,实现高效的批处理与迭代,满足端到端语音处理流程的需求。
背景与挑战
背景概述
阿拉伯语作为全球重要语言之一,其语音技术研究长期面临数据资源匮乏的困境,尤其是在多方言、多区域背景下。MASC阿拉伯语大规模语音语料库由穆罕默德·拉沙德等研究人员于2023年正式发布,旨在构建一个覆盖广泛方言与语境的千小时级语音数据集。该语料库从超过700个YouTube频道采集数据,专注于推动阿拉伯语自动语音识别系统的研发,通过纳入清洁与嘈杂环境下的语音样本,为语音处理领域提供了关键的基础资源。
当前挑战
在语音识别领域,阿拉伯语因其复杂的方言变体与音系特性,模型泛化能力常受限制。MASC语料库致力于应对多方言语音识别的核心难题,即如何在统一框架下有效处理区域发音差异与噪声干扰。数据构建过程中,研究团队面临采集渠道的合法性约束、音频质量的不均衡性以及方言标注的一致性维护等挑战,需通过精细的数据清洗与分类策略确保语料库的多样性与可靠性。
常用场景
经典使用场景
在阿拉伯语语音技术领域,MASC-Arabic数据集作为大规模多方言语音资源,其经典使用场景集中于自动语音识别系统的训练与评估。该数据集涵盖超过一千小时的语音样本,源自七百余个YouTube频道,覆盖多区域、多体裁及多方言内容,为构建鲁棒的阿拉伯语语音识别模型提供了丰富的声学与语言多样性。研究人员常利用其清洁与嘈杂的音频分类,模拟真实环境下的语音识别挑战,从而优化模型在复杂声学条件下的性能表现。
衍生相关工作
围绕MASC-Arabic数据集,学术界衍生出一系列经典研究工作,包括基于Transformer架构的阿拉伯语语音识别系统优化、方言分类模型的构建以及跨方言语音合成技术的探索。这些工作不仅推动了诸如Wav2Vec 2.0等预训练模型在阿拉伯语上的适配与微调,还催生了针对噪声环境下的语音增强算法,部分成果已集成至开源语音工具包中,为后续研究提供了可复现的基准与实验框架。
数据集最近研究
最新研究方向
在阿拉伯语语音技术领域,MASC-Arabic数据集凭借其千小时规模及多方言、多区域特性,正推动前沿研究聚焦于跨方言自动语音识别系统的鲁棒性优化。近期研究热点围绕利用该数据集的清洁与噪声标注,探索噪声环境下的端到端语音识别模型,以应对阿拉伯语方言多样性带来的声学模型泛化挑战。同时,结合自监督学习技术,该数据集被用于预训练大规模语音表示模型,旨在提升低资源阿拉伯语方言的识别性能,促进语音技术在智慧中东应用中的实际部署。
以上内容由遇见数据集搜集并总结生成


