datajuicer/the-pile-europarl-refined-by-data-juicer
收藏Hugging Face2023-10-23 更新2024-03-04 收录
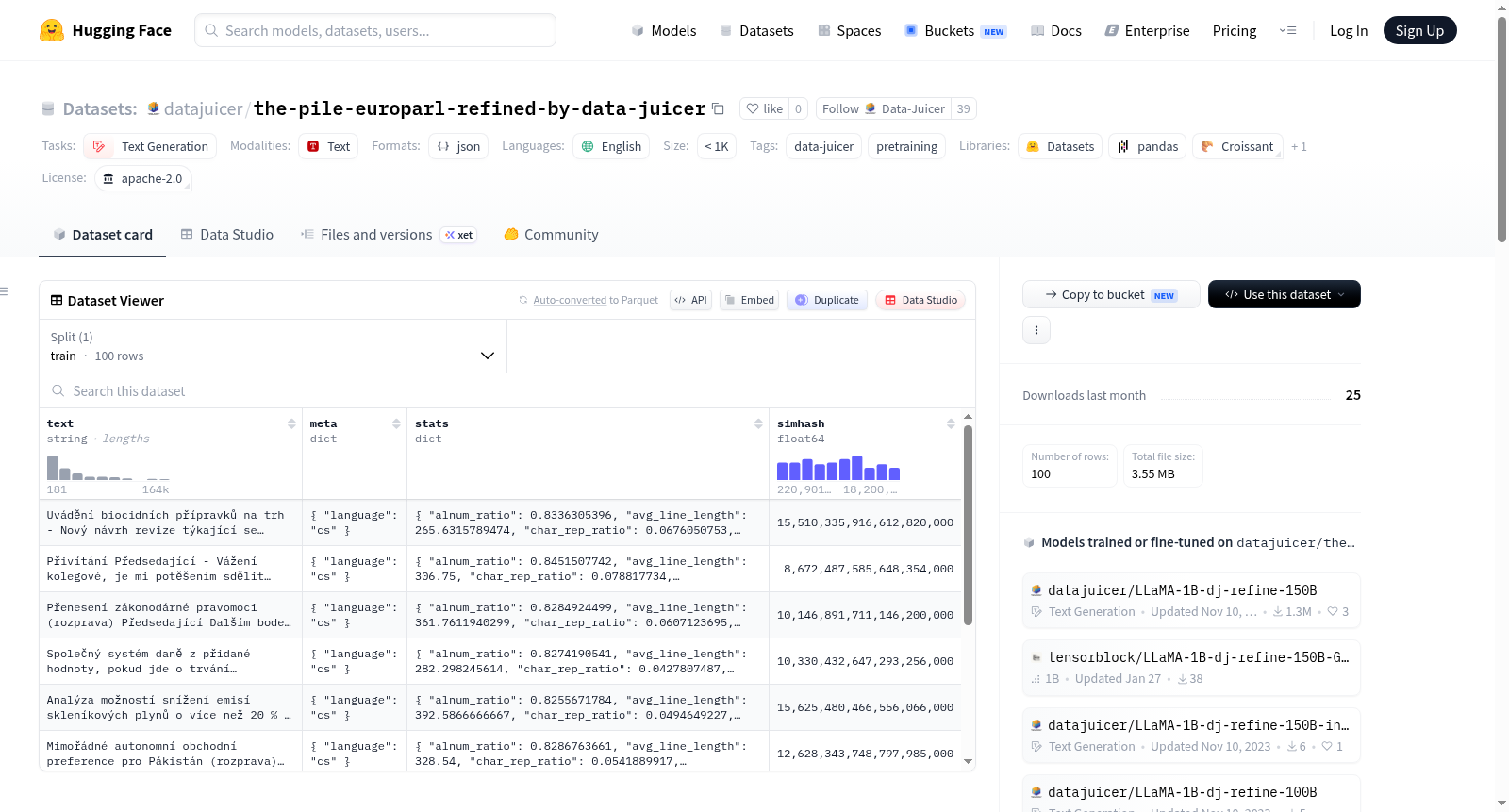
下载链接:
https://hf-mirror.com/datasets/datajuicer/the-pile-europarl-refined-by-data-juicer
下载链接
链接失效反馈官方服务:
资源简介:
The Pile -- EuroParl数据集的一个精炼版本,通过Data-Juicer工具移除了原始数据集中的一些低质量样本,以提高数据集的质量。该数据集主要用于预训练大型语言模型。数据集的样本数量为61,601个,保留了原始数据集的约88.23%。
The Pile -- A refined version of the EuroParl dataset, where low-quality samples from the original dataset are removed using the Data-Juicer tool to improve overall data quality, is primarily used for pre-training large language models (LLMs) and contains 61,601 samples, retaining approximately 88.23% of the original dataset.
提供机构:
datajuicer
原始信息汇总
The Pile -- EuroParl (refined by Data-Juicer)
概述
- 许可证:Apache-2.0
- 任务类别:文本生成
- 语言:英语
- 标签:data-juicer, pretraining
- 数据规模:10K<n<100K
数据集信息
- 样本数量:61,601(保留了原始数据集的约88.23%)
精炼配方
-
全局参数:
- 项目名称:Data-Juicer-recipes-EuroParl
- 数据集路径:/path/to/your/dataset
- 导出路径:/path/to/your/dataset.jsonl
- 子进程数量:50
- 开启追踪器:true
-
处理流程:
- 清理电子邮件映射器
- 清理链接映射器
- 修复Unicode映射器
- 标点符号规范化映射器
- 空白规范化映射器
- 字母数字过滤器(最小比率:0.75,最大比率:0.90)
- 平均行长度过滤器(最大长度:588)
- 字符重复过滤器(重复长度:10,最大比率:0.16)
- 标记词过滤器(语言:en,最大比率:0.0007)
- 语言ID分数过滤器(最小分数:0.7)
- 最大行长度过滤器(最大长度:4000)
- 困惑度过滤器(语言:en,最大困惑度:7596)
- 特殊字符过滤器(最大比率:0.3)
- 文本长度过滤器(最大长度:2e5)
- 词数过滤器(最小数量:20,最大数量:1e5)
- 词重复过滤器(语言:en,重复长度:10,最大比率:0.2)
- 文档Simhash去重器(窗口大小:6,汉明距离:4)
搜集汇总
数据集介绍
构建方式
该数据集源自The Pile语料库中的EuroParl子集,经由Data-Juicer工具进行精细化清洗与过滤而构建。构建过程采用了一套多阶段的处理流水线,首先通过一系列映射操作(如清理电子邮件与链接、修复Unicode、规范化标点与空白)对原始文本进行初步净化。随后,基于统计规则与阈值设定,运用多个过滤器剔除低质量样本,涵盖字母数字比例、字符重复率、敏感词比例、语言识别得分、困惑度、特殊字符占比及文本长度等维度。最后,通过文档级的SimHash去重算法,在汉明距离约束下移除近似重复内容,从而保留了原始数据集中约88.23%的高质量样本,共计61,601条。
特点
该数据集的核心特点在于其经过系统性质量筛选后的高纯净度与专业领域聚焦性。作为欧洲议会会议记录的英文语料,其内容天然具备正式、规范的议会语言风格,适用于预训练大型语言模型。通过多维度过滤(如困惑度上限设定为7596、字母数字比率控制在0.75至0.90之间)与SimHash去重,有效去除了噪声、冗余及低信息密度样本,使得保留的数据在语言规范性、主题一致性与语义清晰度上显著优于原始版本。此外,数据集规模适中(约61k条),既便于快速预览与评估,又保持了领域多样性。
使用方法
该数据集专为大型语言模型的预训练任务设计,可直接作为文本生成任务的训练或评估语料。使用时,用户可通过HuggingFace Datasets库加载预览子集,或通过提供的OSS链接下载完整数据集(约2.2GB的JSONL格式文件)。建议在加载后,依据具体任务需求进行进一步的格式转换或分词处理。由于数据已通过Data-Juicer进行了标准化清洗,用户可直接将其整合至标准的预训练流程中,无需额外的预处理步骤。对于需要更高定制化过滤的场景,可参考README中提供的YAML配置作为基线,调整参数以适应不同的质量要求。
背景与挑战
背景概述
在大规模语言模型预训练中,数据质量直接影响模型性能,而原始语料常包含噪声与冗余信息。The Pile数据集作为广泛使用的开源预训练语料库,其EuroParl子集收录了欧洲议会多语言会议记录,为跨语言理解与生成任务提供了宝贵资源。然而,原始数据中混杂的低质量样本——如格式异常、语义重复或语言标识错误的文本——可能削弱模型训练效果。为此,阿里巴巴集团旗下的Data-Juicer团队于2023年对该子集进行了精细化处理,通过系统性过滤与去重策略,保留了约88.23%的高质量样本,共计61,601条。这一工作不仅提升了数据集的可用性,也为预训练数据清洗流程建立了可复现的范式,对推动语言模型研究中的数据治理具有重要参考价值。
当前挑战
该数据集所解决的领域挑战主要源于预训练语料中普遍存在的噪声问题。原始EuroParl数据包含格式不统一(如多余空行、异常链接)、语言混杂(非英语内容占比高)及低语义密度(如重复字符、冗长句子)等缺陷,这些因素会干扰模型对语言规律的学习,导致生成质量下降。在构建过程中,Data-Juicer团队面临多重技术挑战:其一,需设计合理的过滤阈值以平衡数据保留率与纯净度,例如通过3σ原则设定字符重复率上限为0.16;其二,需处理多语言场景下的语言识别偏差,确保英语片段被准确筛选;其三,需应对大规模数据去重的计算效率问题,采用SimHash算法在保持低碰撞率的同时实现高效去重。这些挑战的解决为后续数据清洗工作提供了方法论借鉴。
常用场景
经典使用场景
在自然语言处理领域,大规模语言模型的预训练离不开高质量语料库的支撑。The Pile 作为经典的多源文本集合,其 EuroParl 子集收录了欧洲议会的多语言平行语料,而经 Data-Juicer 精炼后的版本剔除了噪声样本,保留了约 88% 的高质量数据。该数据集最经典的使用场景是作为英文文本生成任务的预训练语料,用于训练自回归语言模型,如 GPT 系列架构,以提升模型在正式、结构化语体上的生成流畅度与语义一致性。
实际应用
在实际应用中,精炼后的 EuroParl 数据集可用于构建面向专业领域(如法律、外交)的文本生成与理解系统。因其语料源于正式会议记录,语言规范且逻辑严密,适合微调出处理政策文档、会议摘要或翻译任务的模型。此外,该数据集还可作为数据增强的种子集合,用于生成合成训练样本,帮助提升企业级客服、智能写作助手等产品在正式场景下的语言表现力与准确性。
衍生相关工作
该数据集的精炼方法衍生了多项经典工作,包括数据质量评估框架的建立、过滤算子组合的优化研究,以及基于统计特征(如困惑度、字符重复率)的自动清洗策略。后续工作如 Data-Juicer 项目本身,更是将此类精炼流程标准化,促进了多领域语料库的协同清洗。此外,受此启发,研究者开始探索面向特定语言或主题的细粒度数据筛选技术,进一步拓展了高质量预训练数据集的构建范式。
以上内容由遇见数据集搜集并总结生成


