ogiri-debug
收藏Hugging Face2024-09-04 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/YANS-official/ogiri-debug
下载链接
链接失效反馈官方服务:
资源简介:
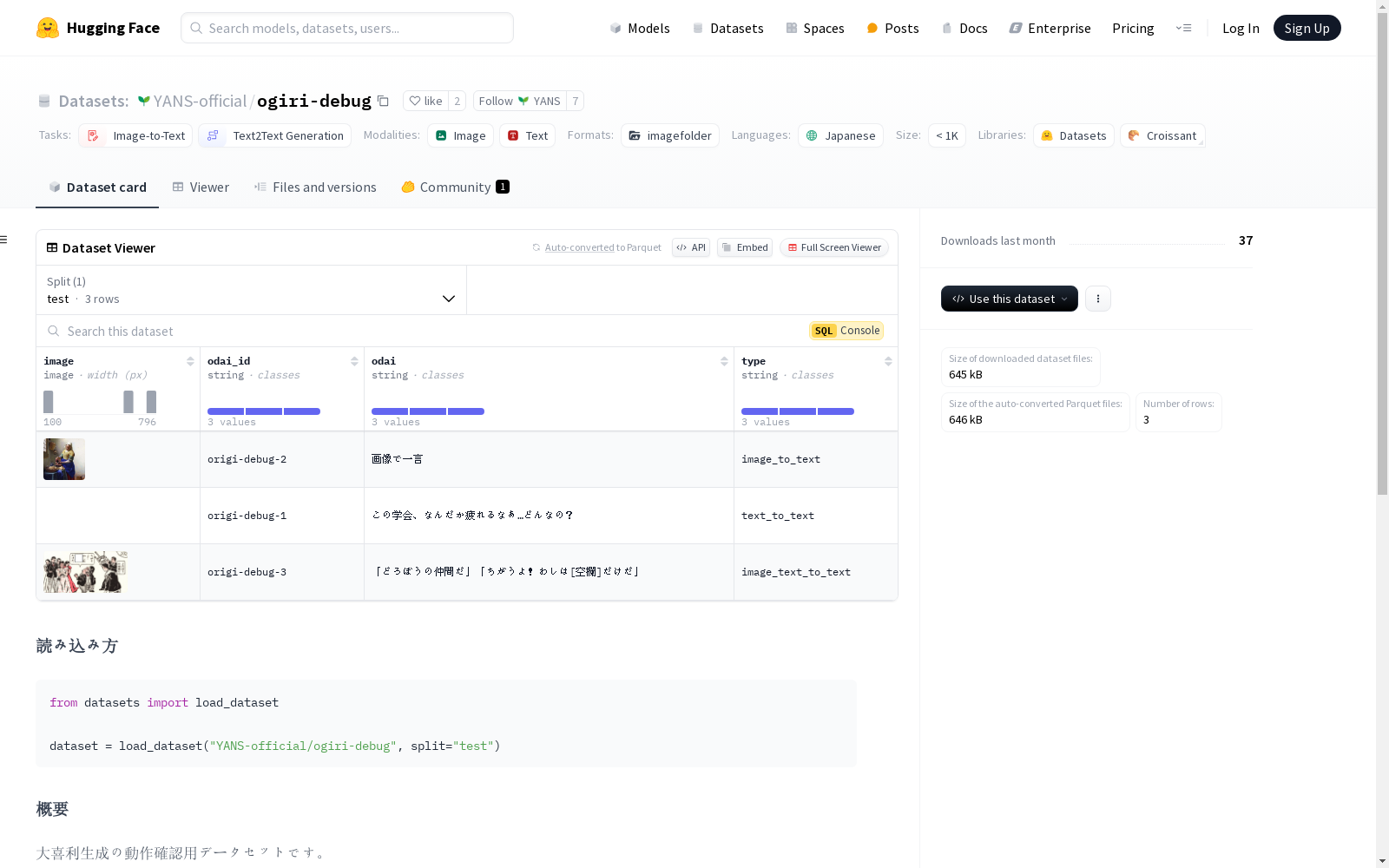
这是一个用于大喜利生成调试的数据集,包含三个任务:text_to_text(文本到文本),image_to_text(图像到文本),以及text_image_to_text(文本图像到文本)。数据集的列包括odai_id(主题ID),file_path(文件路径),type(类型),以及odai(主题)。
This is a dataset designed for the debugging of Daikichi generation, which contains three tasks: text_to_text (text-to-text), image_to_text (image-to-text), and text_image_to_text (text-image-to-text). The columns of the dataset include odai_id (topic ID), file_path (file path), type (type), and odai (topic).
创建时间:
2024-08-30
原始信息汇总
数据集概述
任务类别
- 图像到文本
- 文本到文本生成
语言
- 日语
数据集加载方法
python from datasets import load_dataset
dataset = load_dataset("YANS-official/ogiri-debug", split="test")
数据集概要
这是一个用于大喜利生成的调试数据集,包含以下三个任务:
- text_to_text: 通过文本提供主题,并返回相应的回答。
- image_to_text: 即“图像一句话”,仅提供图像,返回文本形式的回答。
- text_image_to_text: 图像中包含文本,文本部分为空白,需要以填空形式返回回答。
数据集各列说明
| 列名 | 类型 | 示例 | 概述 |
|---|---|---|---|
| odai_id | str | "origi-dummy-1" | 主题的ID |
| file_path | str | "dummy.png" | 图像的文件名 |
| type | str | "text_to_text" | 包含 "text_to_text", "image_to_text", "image_text_to_text" 中的一个。 |
| odai | str | "この学会、なんだか疲れるなぁ…どんなの?" | "text_to_text" 的情况下是主题。"image_to_text" 的情况下是 "图像一句话" 的字符串。"image_text_to_text" 是图像OCR结果中包含 "[空欄]" 的部分。 |
搜集汇总
数据集介绍
构建方式
ogiri-debug数据集是一个专为测试和验证大喜利生成模型而设计的调试数据集。该数据集通过模拟三种不同的任务场景构建而成:文本到文本生成、图像到文本生成以及图像文本混合生成。每种任务类型均包含特定的输入输出格式,确保模型能够在多样化的情境下进行有效测试。数据集的构建过程注重任务的多样性和复杂性,以全面评估模型的生成能力。
使用方法
使用ogiri-debug数据集时,研究者可通过Hugging Face的`datasets`库轻松加载数据。加载后,数据集可直接用于测试和验证大喜利生成模型的性能。研究者可根据任务类型选择相应的样本进行实验,例如通过`text_to_text`任务测试纯文本生成能力,或通过`image_to_text`任务评估图像理解与文本生成的结合能力。数据集的清晰结构和丰富任务类型为模型评估提供了高效且灵活的工具。
背景与挑战
背景概述
ogiri-debug数据集是一个专注于图像到文本和文本到文本生成任务的日语数据集,主要用于大喜利(一种日本传统的幽默问答游戏)生成任务的验证。该数据集由YANS-official团队创建,旨在通过提供多样化的任务类型,如纯文本生成、图像描述生成以及图像与文本结合的填空任务,来测试和验证生成模型的性能。这些任务不仅涵盖了传统的文本生成,还涉及了图像理解和多模态数据处理,为自然语言处理和计算机视觉的交叉研究提供了宝贵资源。
当前挑战
ogiri-debug数据集面临的挑战主要体现在两个方面。首先,在领域问题方面,该数据集旨在解决多模态数据(图像与文本)的联合理解和生成问题,这要求模型不仅能够理解图像内容,还需具备生成符合语境的文本能力,这对模型的综合能力提出了较高要求。其次,在数据集构建过程中,如何确保图像与文本的准确对应以及如何处理图像中的文本信息(如OCR识别)也是技术上的难点。此外,由于大喜利游戏本身具有高度的文化特定性和幽默感,如何捕捉并生成符合文化背景的幽默内容,也是该数据集面临的一大挑战。
常用场景
经典使用场景
ogiri-debug数据集主要用于测试和验证图像到文本生成以及文本到文本生成的模型性能。该数据集包含三种任务:纯文本生成、图像到文本生成以及图像和文本结合的生成任务。这些任务能够帮助研究人员评估模型在处理多模态输入时的表现,尤其是在处理日语文本和图像结合的场景中。
解决学术问题
ogiri-debug数据集解决了多模态生成任务中的关键问题,特别是在处理日语文本和图像结合的复杂场景时。通过提供多样化的任务类型,该数据集帮助研究人员深入理解模型在跨模态生成中的表现,推动了自然语言处理和计算机视觉领域的交叉研究。
实际应用
在实际应用中,ogiri-debug数据集可以用于开发智能助手、社交媒体内容生成工具以及教育领域的互动学习系统。例如,通过图像到文本生成任务,可以开发出能够自动为图片生成有趣描述的应用程序,增强用户体验。
数据集最近研究
最新研究方向
在自然语言处理与计算机视觉的交叉领域,ogiri-debug数据集为研究者提供了一个独特的平台,用于探索图像到文本以及文本到文本的生成任务。该数据集特别聚焦于日语环境下的幽默生成,即‘大喜利’(一种日本传统的即兴幽默表演),这为跨文化语言模型的研究提供了新的视角。近年来,随着深度学习技术的进步,研究者们利用该数据集开发了多种模型,旨在提高模型在理解和生成幽默内容方面的能力。这些研究不仅推动了语言模型在情感和语境理解上的进步,也为多模态学习提供了新的数据支持,特别是在处理图像与文本结合的任务时,如‘画像で一言’(图片配文)和‘image_text_to_text’(图文结合填空)。这些研究方向的进展,对于提升人工智能在创意写作和娱乐产业中的应用潜力具有重要意义。
以上内容由遇见数据集搜集并总结生成


