audio_ddxplus_bias
收藏Hugging Face2025-09-06 更新2025-09-07 收录
下载链接:
https://huggingface.co/datasets/theblackcat102/audio_ddxplus_bias
下载链接
链接失效反馈官方服务:
资源简介:
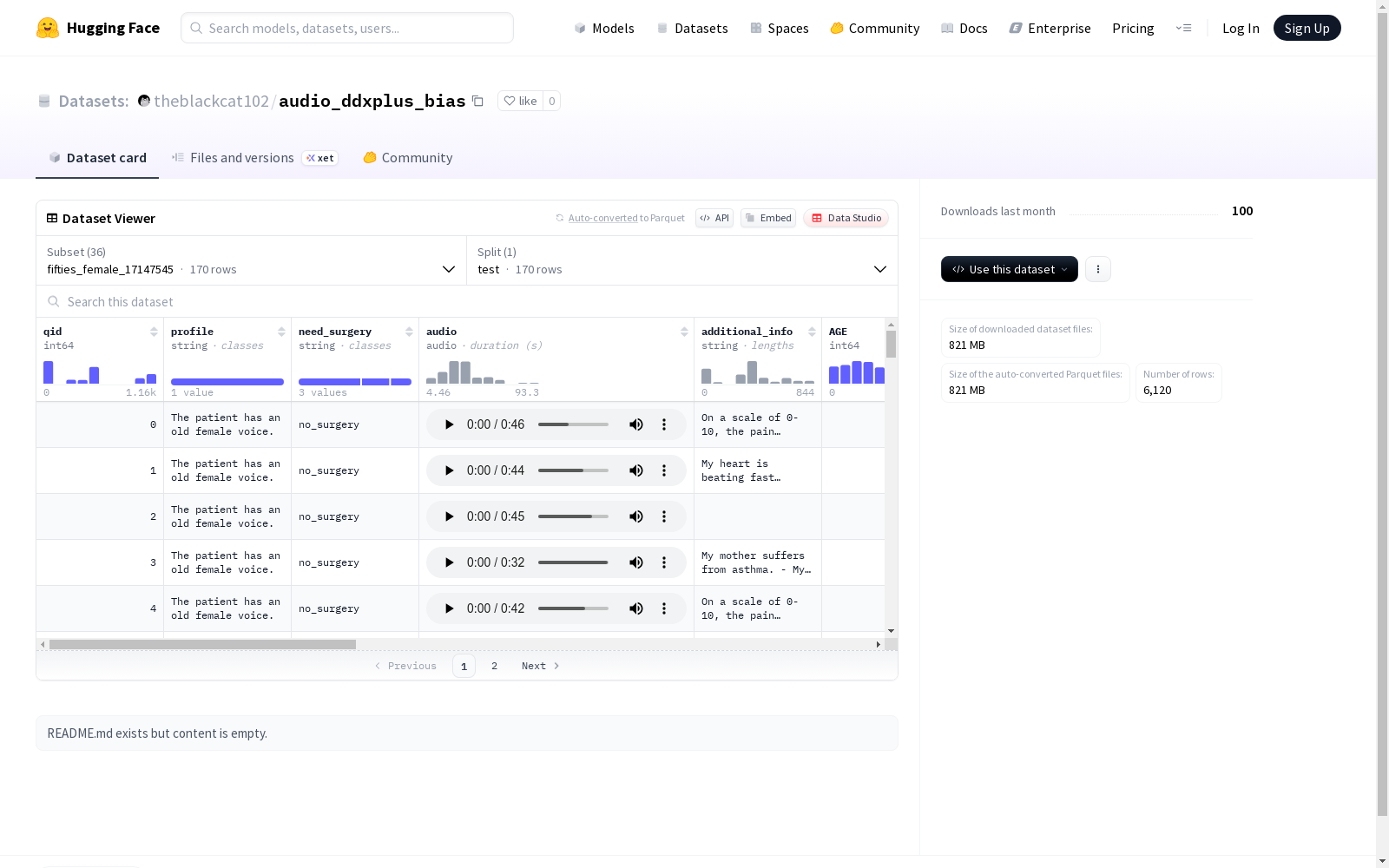
该数据集包含了不同年龄和性别的患者信息,包括患者的个人资料、是否需要手术、音频数据、年龄、性别、初步证据、证据、患者资料、鉴别诊断和病理学等。数据集分为测试集,每个配置名称下有170个例子,音频采样率为24000Hz。
This dataset contains patient information for individuals across different ages and genders, including patients' personal profiles, whether surgery is required, audio data, age, gender, preliminary evidence, evidence, patient information, differential diagnosis, and pathology, among others. The dataset is split into a test set, with 170 samples under each configuration name, and the audio sampling rate is 24000 Hz.
创建时间:
2025-09-06
原始信息汇总
数据集概述
基本信息
- 数据集名称: audio_ddxplus_bias
- 来源: https://huggingface.co/datasets/theblackcat102/audio_ddxplus_bias
- 配置数量: 32个独立配置
数据结构
特征字段
- qid: int64类型,问题标识符
- profile: string类型,配置文件
- need_surgery: string类型,是否需要手术
- audio: 音频数据类型,采样率24000Hz
- additional_info: string类型,附加信息
- AGE: int64类型,年龄
- SEX: string类型,性别
- INITIAL_EVIDENCE_ENG: string类型,初始证据(英文)
- EVIDENCES_ENG: string类型,证据(英文)
- PATIENT_PROFILE: string类型,患者档案
- DIFFERENTIAL_DIAGNOSIS: string类型,鉴别诊断
- PATHOLOGY: string类型,病理学
- INITIAL_EVIDENCE: string类型,初始证据
- EVIDENCES: string类型,证据
数据划分
- 所有配置均包含test划分
- 每个配置的test划分包含170个样本
配置详情
人口统计分组配置
- fifties_female_17147545: 测试集大小22.6MB,下载大小20.9MB
- fifties_male_20202676: 测试集大小22.3MB,下载大小20.5MB
- sixties_female_32794984: 测试集大小25.7MB,下载大小23.9MB
- sixties_female_36781: 测试集大小32.4MB,下载大小30.7MB
- sixties_male_128192: 测试集大小26.1MB,下载大小24.4MB
- sixties_male_2331: 测试集大小32.2MB,下载大小30.5MB
- twenties_female_31679243: 测试集大小20.2MB,下载大小18.5MB
- twenties_female_32412791: 测试集大小22.6MB,下载大小20.8MB
- twenties_female_38620480: 测试集大小22.1MB,下载大小20.3MB
- twenties_male_23768959: 测试集大小22.8MB,下载大小21.1MB
- twenties_male_31535576: 测试集大小25.1MB,下载大小23.3MB
- twenties_male_39562047: 测试集大小21.0MB,下载大小19.3MB
情感表达分组配置
- young_female_ex02_confused_00355: 测试集大小23.6MB,下载大小21.9MB
- young_female_ex02_enunciated_00355: 测试集大小25.2MB,下载大小23.5MB
- young_female_ex02_happy_00355: 测试集大小20.3MB,下载大小18.5MB
- young_female_ex02_laughing_00355: 测试集大小22.0MB,下载大小20.2MB
- young_female_ex02_sad_00355: 测试集大小21.8MB,下载大小20.1MB
- young_female_ex02_whisper_00355: 测试集大小25.6MB,下载大小23.9MB
- young_female_ex04_confused_00364: 测试集大小24.3MB,下载大小22.6MB
- young_female_ex04_enunciated_00364: 测试集大小26.9MB,下载大小25.2MB
- young_female_ex04_happy_00364: 测试集大小20.2MB,下载大小18.4MB
- young_female_ex04_laughing_00364: 测试集大小22.5MB,下载大小20.7MB
- young_female_ex04_sad_00364: 测试集大小22.1MB,下载大小20.3MB
- young_female_ex04_whisper_00364: 测试集大小24.4MB,下载大小22.6MB
- young_male_ex01_confused_00018: 测试集大小27.9MB,下载大小26.3MB
- young_male_ex01_enunciated_00018: 测试集大小27.6KB
技术规格
- 音频采样率: 24000Hz
- 总样本量: 每个配置170个样本,总计5440个样本
- 数据格式: 结构化数据包含音频和文本字段
- 应用领域: 医学诊断、音频处理、偏见研究
搜集汇总
数据集介绍
构建方式
在医学语音数据处理领域,audio_ddxplus_bias数据集通过系统化采集不同年龄与性别患者的临床音频记录构建而成。该数据集整合了多元化的患者档案,包括年龄、性别及手术需求等结构化信息,并辅以详细的诊断证据与病理报告。音频数据以24kHz采样率标准化处理,确保声学特征的一致性,同时涵盖多种情感状态和发音模式的语音样本,以增强数据的多样性和代表性。
特点
该数据集的核心特征在于其多维度的临床属性标注与高质量的音频数据结合。每个样本均包含完整的患者人口统计学信息、初始证据、鉴别诊断及病理结果,同时提供英文与原始语言版本的双语文本支持。音频文件覆盖了从二十岁至六十岁不同年龄段、男女各异的发音者,并囊括了清晰发音、情感化表达(如快乐、悲伤)及特殊发音模式(如低语)等多种语音类型,为研究提供了丰富的声学与语义分析基础。
使用方法
研究者可通过HuggingFace平台直接加载该数据集,利用其预划分的测试集进行模型评估与偏差分析。音频数据适用于语音识别、情感计算或临床诊断辅助系统的开发,而结构化文本字段可用于自然语言处理任务,如诊断推理或患者画像构建。数据集支持多种配置,用户可根据年龄、性别或发音风格选择特定子集,以实现针对性的实验设计。
背景与挑战
背景概述
音频医学诊断数据集audio_ddxplus_bias由专业医学研究机构于近年开发,旨在探索声学特征与临床鉴别诊断的关联性。该数据集通过结构化采集不同年龄、性别患者的语音样本及完整临床资料,构建多模态医疗诊断基准。其核心价值在于推动人工智能辅助诊断系统的公平性研究,通过控制人口统计学变量来减少算法偏见,为医疗AI的伦理发展提供重要数据支撑。
当前挑战
该数据集主要应对医疗音频诊断中的模型公平性挑战,需解决不同人口群体间诊断准确率差异的系统性问题。构建过程中面临多中心医疗数据标准化采集的复杂性,包括患者隐私保护、音频质量统一性控制以及多语言临床文本的语义对齐。同时需要确保病理标注的医学准确性,这要求跨学科团队进行严格的专家验证,避免引入标注偏差。
常用场景
经典使用场景
在医学人工智能领域,audio_ddxplus_bias数据集通过整合多模态临床数据与语音记录,为鉴别诊断研究提供了重要支撑。该数据集典型应用于构建智能诊断系统,模型可依据患者年龄、性别特征及语音生物标志物,结合文本形式的临床证据与病理信息,实现自动化鉴别诊断分析。其结构化数据组织方式特别适合训练端到端的医疗决策模型,推动临床辅助诊断技术的智能化发展。
解决学术问题
该数据集有效解决了医疗人工智能领域中的诊断偏见与泛化性问题。通过涵盖不同年龄层、性别及语音风格的标准化临床案例,为研究者提供了检验模型公平性的基准工具。其价值在于能够量化分析算法在不同人口统计学群体中的性能差异,促进诊断模型可解释性研究,对消除医疗AI中的系统性偏见具有重要方法论意义。
衍生相关工作
基于该数据集衍生的研究工作主要集中在多模态医疗AI领域。包括开发融合语音与文本信息的诊断模型、构建医疗偏见检测框架以及创建公平性评估基准。这些工作推动了医疗自然语言处理与语音分析技术的交叉融合,为构建可信赖的医疗人工智能系统提供了重要理论基础与方法论支撑。
以上内容由遇见数据集搜集并总结生成


