Video Trimming Benchmark
收藏arXiv2024-12-13 更新2024-12-25 收录
下载链接:
https://ylingfeng.github.io/AVT/
下载链接
链接失效反馈官方服务:
资源简介:
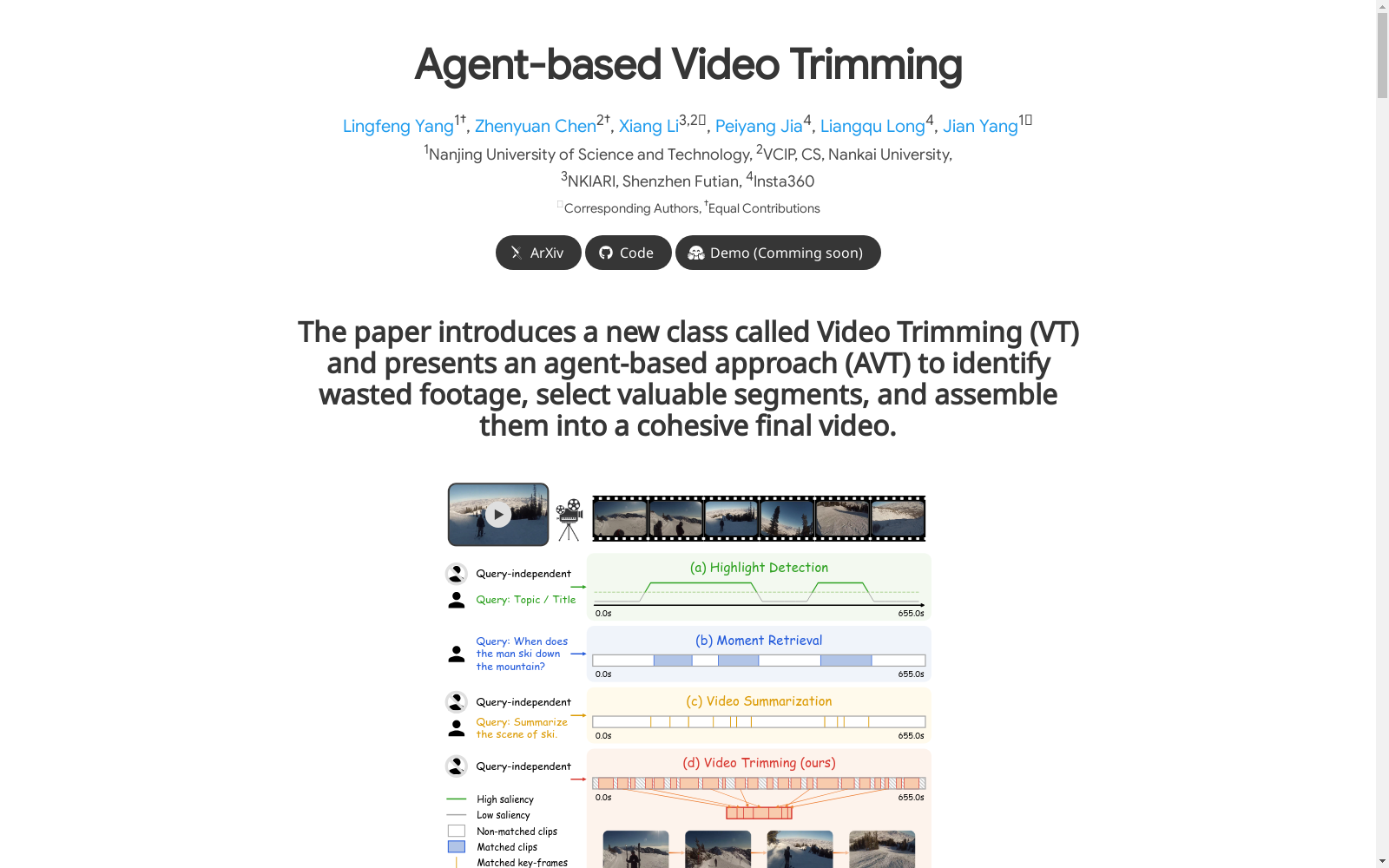
该数据集是为视频修剪任务专门创建的基准数据集,包含了从互联网上获取的原始用户视频,并标注了浪费和亮点标签。数据集的创建旨在通过视频字幕生成、片段过滤和故事编排三个阶段,生成具有连贯故事线的视频。数据集的应用领域主要集中在视频理解和视频编辑,旨在解决长视频中冗余内容过滤和关键片段提取的问题,从而生成更紧凑、更具吸引力的视频内容。
This dataset is a benchmark specifically constructed for the video trimming task. It comprises raw user videos collected from the Internet, annotated with waste and highlight labels. The dataset is developed to produce videos with coherent storylines via three stages: video caption generation, segment filtering, and story arrangement. Its primary application domains focus on video understanding and video editing, aiming to address the challenges of redundant content filtering and key segment extraction from long videos, thereby generating more compact and compelling video content.
提供机构:
南京理工大学, 南开大学, 深圳福田, Insta360
创建时间:
2024-12-13
搜集汇总
数据集介绍
构建方式
Video Trimming Benchmark数据集的构建基于用户生成的原始视频,这些视频通常包含拍摄中的缺陷,如遮挡、抖动或过度曝光。数据集从YouTube上收集了42个视频,涵盖了日常生活、体育和旅行日志三大类别。每个视频的平均时长为10分钟,并由10名标注者对视频片段进行质量评估,标注等级分为0(浪费)、1(模糊)、2(正常)和3(亮点)。通过这种标注方式,数据集为视频修剪任务提供了丰富的基准数据。
特点
Video Trimming Benchmark数据集的特点在于其多样性和真实性。数据集不仅包含了长时间、未经编辑的原始视频,还涵盖了多种主题和场景,如家庭生活、户外运动和旅行记录。每个视频片段都经过详细的标注,标注内容包括视频的质量缺陷(如遮挡、抖动、过度曝光等)以及视频的上下文属性(如活动内容、地点、时间和人物)。这种多层次的标注使得数据集能够支持复杂的视频修剪任务,尤其是针对视频片段的选择和叙事连贯性的研究。
使用方法
Video Trimming Benchmark数据集的使用方法主要围绕视频修剪任务的评估和算法开发。研究人员可以利用该数据集训练和测试视频修剪算法,特别是那些能够自动识别和过滤低质量片段、选择高亮片段并生成连贯叙事的算法。数据集中的标注信息可以用于评估算法的修剪效果,例如通过比较算法生成的修剪视频与人工标注的高亮片段。此外,数据集还支持零样本高亮检测任务,研究人员可以在YouTube Highlights和TVSum等基准数据集上进行跨数据集验证,以评估算法的泛化能力。
背景与挑战
背景概述
随着用户生成视频的快速增长,视频内容的冗余性和长度问题日益凸显,亟需一种能够高效提取关键信息的算法。尽管在视频高光检测、时刻检索和视频摘要等领域取得了显著进展,现有方法主要关注特定时间区间的选择,往往忽略了片段之间的相关性及其组合潜力。为此,南京理工大学、南开大学等机构的研究团队于2024年提出了名为Video Trimming(VT)的新任务,旨在检测冗余片段、选择有价值的内容,并将其组合成具有连贯叙事的最终视频。该任务通过Agent-based Video Trimming(AVT)算法实现,分为视频结构化、片段过滤和故事组合三个阶段。AVT算法不仅显著提升了视频修剪的效率,还在YouTube Highlights、TVSum等基准数据集上展示了优越的性能。
当前挑战
Video Trimming任务面临的主要挑战包括:1) 视频内容的高效提取与组合。现有方法往往仅关注片段的选择,而忽略了片段之间的连贯性和叙事逻辑,导致最终视频缺乏整体性。2) 视频片段的质量评估。在构建过程中,如何准确识别并过滤掉低质量的片段(如遮挡、抖动、过曝等)是一个关键难题。3) 多源视频的处理。实际应用中,输入视频可能来自多个来源,如何从不同视频中提取并组合出连贯的叙事内容,增加了算法的复杂性。4) 长视频的处理。长视频通常包含大量冗余信息,如何在保证叙事完整性的同时,高效地修剪出精华内容,是另一个重要挑战。
常用场景
经典使用场景
Video Trimming Benchmark 数据集在视频内容理解与编辑领域具有广泛的应用,尤其是在用户生成视频的自动剪辑任务中。该数据集通过提供大量未编辑的原始视频片段,帮助研究者开发和评估视频剪辑算法,特别是那些能够从冗长的视频中提取关键片段并生成连贯叙事的算法。其经典使用场景包括视频高光检测、片段过滤和故事编排,旨在从长视频中提取出最具吸引力和信息量的片段,形成简洁且富有逻辑的最终视频。
实际应用
在实际应用中,Video Trimming Benchmark 数据集为视频编辑工具的开发提供了重要支持。例如,社交媒体平台可以利用该数据集中的算法,自动为用户生成短视频摘要,帮助用户快速浏览长视频中的关键内容。此外,该数据集还可用于视频内容推荐系统,通过提取视频中的高光片段,提升用户的观看体验。在教育和培训领域,该数据集可以帮助自动生成教学视频的精华部分,提高学习效率。总之,该数据集在视频内容自动化和智能化处理方面具有广泛的应用前景。
衍生相关工作
Video Trimming Benchmark 数据集衍生了许多相关的研究工作,特别是在基于代理的视频剪辑算法领域。例如,基于多模态大语言模型(MLLMs)的视频剪辑算法(如AVT)通过结合视频结构化、片段过滤和故事编排,显著提升了视频剪辑的效果。此外,该数据集还推动了视频高光检测和视频摘要任务的研究,许多工作在此基础上提出了新的模型和评估方法。例如,UniVTG 和 UVCOM 等模型在视频片段检索和高光检测任务中取得了显著进展,进一步推动了视频内容理解领域的发展。
以上内容由遇见数据集搜集并总结生成


