MMSearch
收藏Hugging Face2024-09-20 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/CaraJ/MMSearch
下载链接
链接失效反馈官方服务:
资源简介:
MMSearch数据集是一个用于评估大型多模态模型在多模态搜索任务中表现的综合基准。数据集包含300个手动收集的实例,涵盖14个子领域,确保与现有LMMs的训练数据无重叠。数据集设计了四个评估任务:requery、rerank、summarization和end-to-end,以全面评估模型的搜索能力。
The MMSearch dataset is a comprehensive benchmark for evaluating the performance of large multimodal models (LMMs) in multimodal search tasks. It includes 300 manually curated instances spanning 14 sub-domains, with no overlap with the training data of existing LMMs. Four evaluation tasks are designed for this dataset: requery, rerank, summarization, and end-to-end, to comprehensively assess the models' search capabilities.
创建时间:
2024-09-20
原始信息汇总
MMSearch 数据集概述
基本信息
- 任务类别:
- 问答
- 视觉问答
- 语言:
- 英语
- 标签:
- 多模态搜索
- 数据规模:
- n<1K
配置信息
配置: end2end
- 数据文件:
- 分割: end2end
- 路径: "end2end.parquet"
- 特征:
- sample_id: string
- query: string
- query_image: image
- image_search_result: image
- area: string
- subfield: string
- timestamp: string
- gt_requery: string
- gt_answer: string
- alternative_gt_answers: sequence
- feature: string
- 分割:
- end2end: 300个样本
配置: rerank
- 数据文件:
- 分割: rerank
- 路径: "rerank.parquet"
- 特征:
- sample_id: string
- query: string
- query_image: image
- image_search_result: image
- area: string
- subfield: string
- timestamp: string
- valid: sequencelengths
- not_sure: sequencelengths
- invalid: sequencelengths
- gt_answer: string
- website0_info: struct
- title: string
- snippet: string
- url: string
- website1_info: struct
- title: string
- snippet: string
- url: string
- website2_info: struct
- title: string
- snippet: string
- url: string
- website3_info: struct
- title: string
- snippet: string
- url: string
- website4_info: struct
- title: string
- snippet: string
- url: string
- website5_info: struct
- title: string
- snippet: string
- url: string
- website6_info: struct
- title: string
- snippet: string
- url: string
- website7_info: struct
- title: string
- snippet: string
- url: string
- website0_head_screenshot: image
- website1_head_screenshot: image
- website2_head_screenshot: image
- website3_head_screenshot: image
- website4_head_screenshot: image
- website5_head_screenshot: image
- website6_head_screenshot: image
- website7_head_screenshot: image
- 分割:
- rerank: 300个样本
配置: summarization
- 数据文件:
- 分割: summarization
- 路径: "summarization.parquet"
- 特征:
- sample_id: string
- query: string
- query_image: image
- image_search_result: image
- area: string
- subfield: string
- timestamp: string
- website_title: string
- website_snippet: string
- website_url: string
- website_original_content: string
- website_retrieved_content: string
- website_fullpage_screenshot: image
- gt_requery: string
- gt_answer: string
- alternative_gt_answers: sequencelengths
- 分割:
- summarization: 300个样本
搜集汇总
数据集介绍
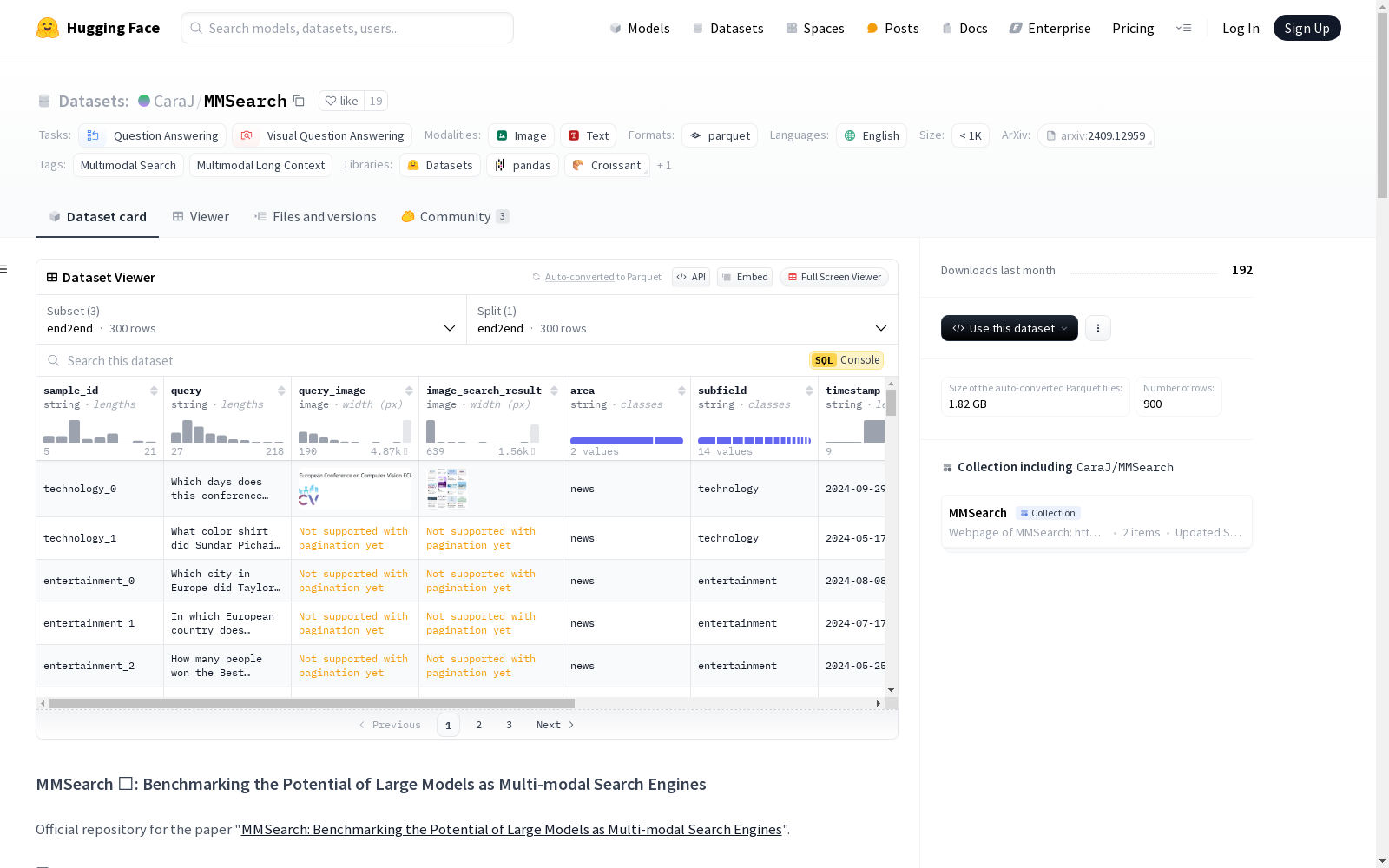
构建方式
MMSearch数据集的构建基于多模态搜索的需求,旨在评估大型多模态模型(LMMs)在搜索任务中的潜力。数据集包含300个手工收集的实例,涵盖14个子领域,确保与现有LMMs的训练数据无重叠。通过设计MMSearch-Engine管道,数据集支持LMMs作为多模态搜索引擎的功能,并采用分步评估策略,包括重新查询、重排序、摘要生成和端到端任务,以全面评估模型的搜索能力。
特点
MMSearch数据集的特点在于其多模态性质,结合了文本和图像数据,涵盖了广泛的领域和子领域。数据集的每个实例包含查询文本、查询图像、搜索结果图像以及相关的元数据,如时间戳、领域和子领域信息。此外,数据集提供了多个真实答案和替代答案,增强了评估的多样性和挑战性。通过分步任务设计,数据集能够深入分析LMMs在不同搜索阶段的表现。
使用方法
MMSearch数据集的使用方法包括加载数据集文件、执行分步任务评估以及生成端到端搜索结果。用户可以通过HuggingFace平台访问数据集,并使用提供的评估代码对LMMs进行测试。数据集支持三种独立任务(重新查询、重排序和摘要生成)和一个端到端任务,用户可以根据需要选择任务类型进行评估。评估结果将加权计算,最终得分反映了模型在多模态搜索中的综合表现。
背景与挑战
背景概述
MMSearch数据集由Dongzhi Jiang等研究人员于2024年提出,旨在评估大型多模态模型(LMMs)在多模态搜索领域的潜力。该数据集包含300个手工收集的实例,涵盖14个子领域,确保与现有LMMs的训练数据无重叠,从而保证答案的唯一性。MMSearch通过设计一个精细的管道MMSearch-Engine,使任何LMM能够作为多模态AI搜索引擎运行。该数据集的发布填补了多模态搜索领域评估框架的空白,为相关研究提供了重要的基准。
当前挑战
MMSearch数据集面临的主要挑战包括:1) 多模态搜索的复杂性,要求模型能够同时处理文本和图像信息,并在长上下文中进行有效检索;2) 数据构建过程中,确保实例的多样性和无重叠性,以避免模型在训练数据中直接找到答案;3) 评估策略的设计,需通过分步任务(如重新查询、重新排序和摘要生成)以及端到端任务来全面评估模型的搜索能力。这些挑战不仅考验模型的综合能力,也对数据集的构建和评估方法提出了高要求。
常用场景
经典使用场景
MMSearch数据集主要用于评估大型多模态模型(LMMs)在多模态搜索任务中的表现。通过提供包含文本和图像的查询,数据集能够模拟真实世界中的多模态搜索场景,帮助研究者测试模型在复杂信息检索任务中的能力。数据集中的任务包括重新查询、重新排序和摘要生成,涵盖了多模态搜索的多个关键环节。
实际应用
在实际应用中,MMSearch数据集可以用于开发和优化多模态搜索引擎,特别是在需要同时处理文本和图像信息的场景中。例如,在电子商务平台中,用户可以通过上传图片并输入文字描述来搜索相关商品。该数据集能够帮助开发者测试和提升搜索引擎的准确性和效率,从而提升用户体验。
衍生相关工作
MMSearch数据集衍生了一系列相关研究工作,特别是在多模态模型的应用和评估方面。例如,基于该数据集的研究推动了多模态模型在视觉问答、图像检索和跨模态信息融合等领域的进展。此外,该数据集还促进了多模态搜索算法的标准化评估框架的建立,为后续研究提供了重要的参考和基准。
以上内容由遇见数据集搜集并总结生成


