nomic-embed-unsupervised-data
收藏魔搭社区2025-12-03 更新2025-01-25 收录
下载链接:
https://modelscope.cn/datasets/nomic-ai/nomic-embed-unsupervised-data
下载链接
链接失效反馈官方服务:
资源简介:
Weakly Supervised Contrastive Training data for Text Embedding models used in [Nomic Embed](https://huggingface.co/collections/nomic-ai/nomic-embed-65c0426827a5fdca81a87b89) models
## Training
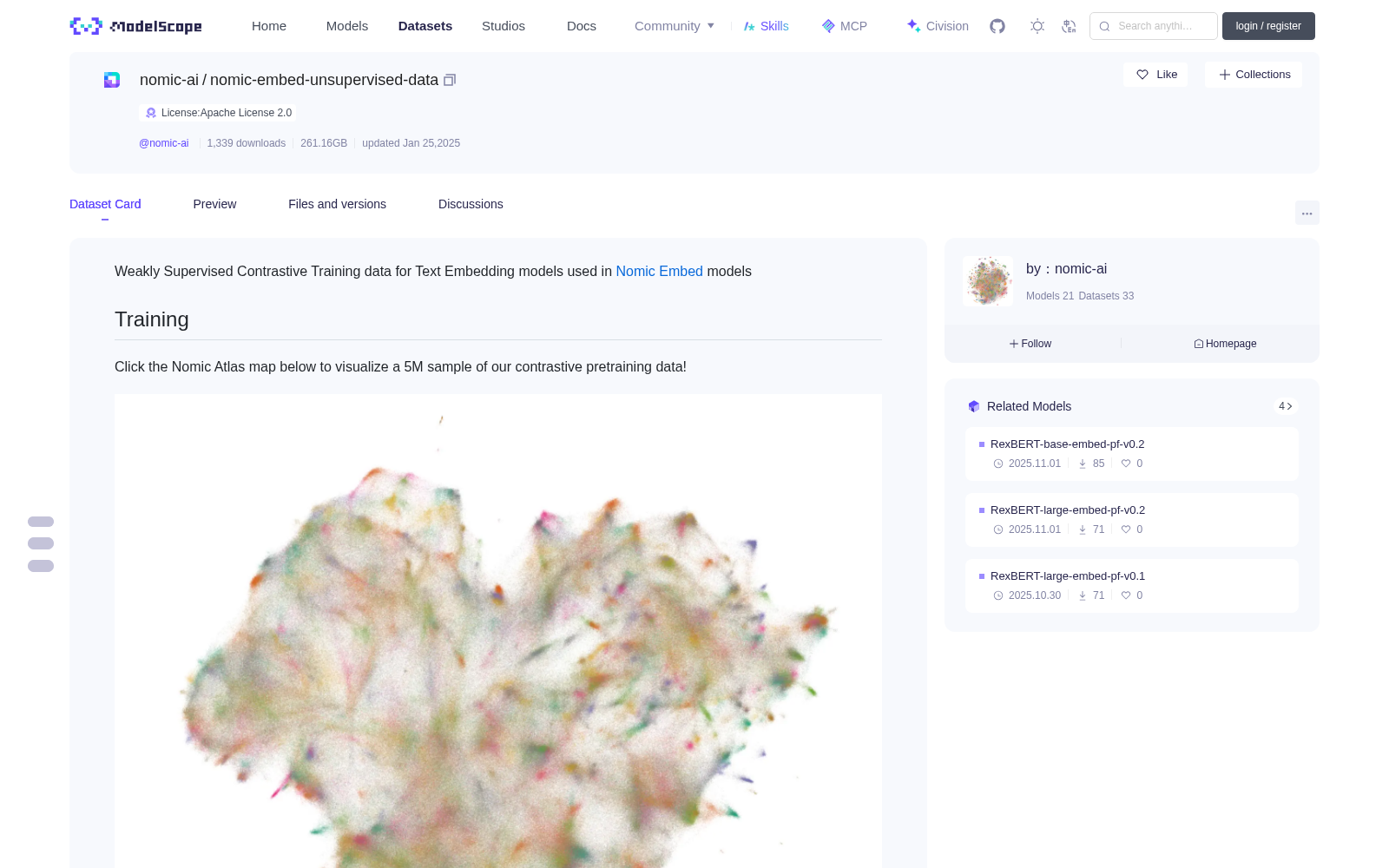
Click the Nomic Atlas map below to visualize a 5M sample of our contrastive pretraining data!
[](https://atlas.nomic.ai/map/nomic-text-embed-v1-5m-sample)
We train our embedder using a multi-stage training pipeline. Starting from a long-context [BERT model](https://huggingface.co/nomic-ai/nomic-bert-2048),
the first unsupervised contrastive stage trains on a dataset generated from weakly related text pairs, such as question-answer pairs from forums like StackExchange and Quora, title-body pairs from Amazon reviews, and summarizations from news articles.
In the second finetuning stage, higher quality labeled datasets such as search queries and answers from web searches are leveraged. Data curation and hard-example mining is crucial in this stage.
For more details, see the Nomic Embed [Technical Report](https://static.nomic.ai/reports/2024_Nomic_Embed_Text_Technical_Report.pdf) and corresponding [blog post](https://blog.nomic.ai/posts/nomic-embed-text-v1).
Training data to train the models is released in its entirety. For more details, see the `contrastors` [repository](https://github.com/nomic-ai/contrastors)
# Join the Nomic Community
- Nomic: [https://nomic.ai](https://nomic.ai)
- Discord: [https://discord.gg/myY5YDR8z8](https://discord.gg/myY5YDR8z8)
- Twitter: [https://twitter.com/nomic_ai](https://twitter.com/nomic_ai)
# Citation
If you find the model, dataset, or training code useful, please cite our work
```bibtex
@misc{nussbaum2024nomic,
title={Nomic Embed: Training a Reproducible Long Context Text Embedder},
author={Zach Nussbaum and John X. Morris and Brandon Duderstadt and Andriy Mulyar},
year={2024},
eprint={2402.01613},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
# 用于Nomic Embed系列模型的弱监督对比训练数据集
> 数据集来源:[Nomic Embed](https://huggingface.co/collections/nomic-ai/nomic-embed-65c0426827a5fdca81a87b89)
## 训练流程
点击下方的Nomic Atlas地图,即可可视化我们对比预训练数据的500万样本子集!
[](https://atlas.nomic.ai/map/nomic-text-embed-v1-5m-sample)
我们采用多阶段训练流水线对文本嵌入模型(Text Embedding Model)进行训练。以长上下文BERT模型(BERT)作为初始模型,第一阶段的无监督对比预训练将基于弱相关文本对构成的数据集开展训练,此类文本对包括StackExchange、Quora等论坛的问答对,亚马逊评论的标题-正文对,以及新闻文章的摘要内容。
在第二阶段的微调环节中,我们将采用质量更高的标注数据集,例如网页搜索场景下的查询语句与对应答案。此阶段的数据整理与难例挖掘至关重要。
如需了解更多细节,请参阅Nomic Embed技术报告(Technical Report)与对应博客文章:
- 技术报告:[https://static.nomic.ai/reports/2024_Nomic_Embed_Text_Technical_Report.pdf](https://static.nomic.ai/reports/2024_Nomic_Embed_Text_Technical_Report.pdf)
- 博客文章:[https://blog.nomic.ai/posts/nomic-embed-text-v1](https://blog.nomic.ai/posts/nomic-embed-text-v1)
本模型的全部训练数据已完整开源发布。更多细节请参阅`contrastors`代码仓库:[https://github.com/nomic-ai/contrastors](https://github.com/nomic-ai/contrastors)
## 加入Nomic社区
- Nomic官网:[https://nomic.ai](https://nomic.ai)
- Discord社区:[https://discord.gg/myY5YDR8z8](https://discord.gg/myY5YDR8z8)
- Twitter账号:[https://twitter.com/nomic_ai](https://twitter.com/nomic_ai)
## 引用声明
如果您认为本模型、数据集或训练代码对您的工作有所帮助,请引用我们的成果:
bibtex
@misc{nussbaum2024nomic,
title={Nomic Embed: Training a Reproducible Long Context Text Embedder},
author={Zach Nussbaum and John X. Morris and Brandon Duderstadt and Andriy Mulyar},
year={2024},
eprint={2402.01613},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
提供机构:
maas创建时间:
2025-01-19
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集用于Nomic Embed模型的弱监督对比训练,包含从StackExchange、Quora等论坛的问答对、Amazon评论的标题-正文对以及新闻摘要等弱相关文本对。数据集大小为261.16GB,采用Apache 2.0许可证,旨在支持文本嵌入模型的预训练和微调阶段。
以上内容由遇见数据集搜集并总结生成


