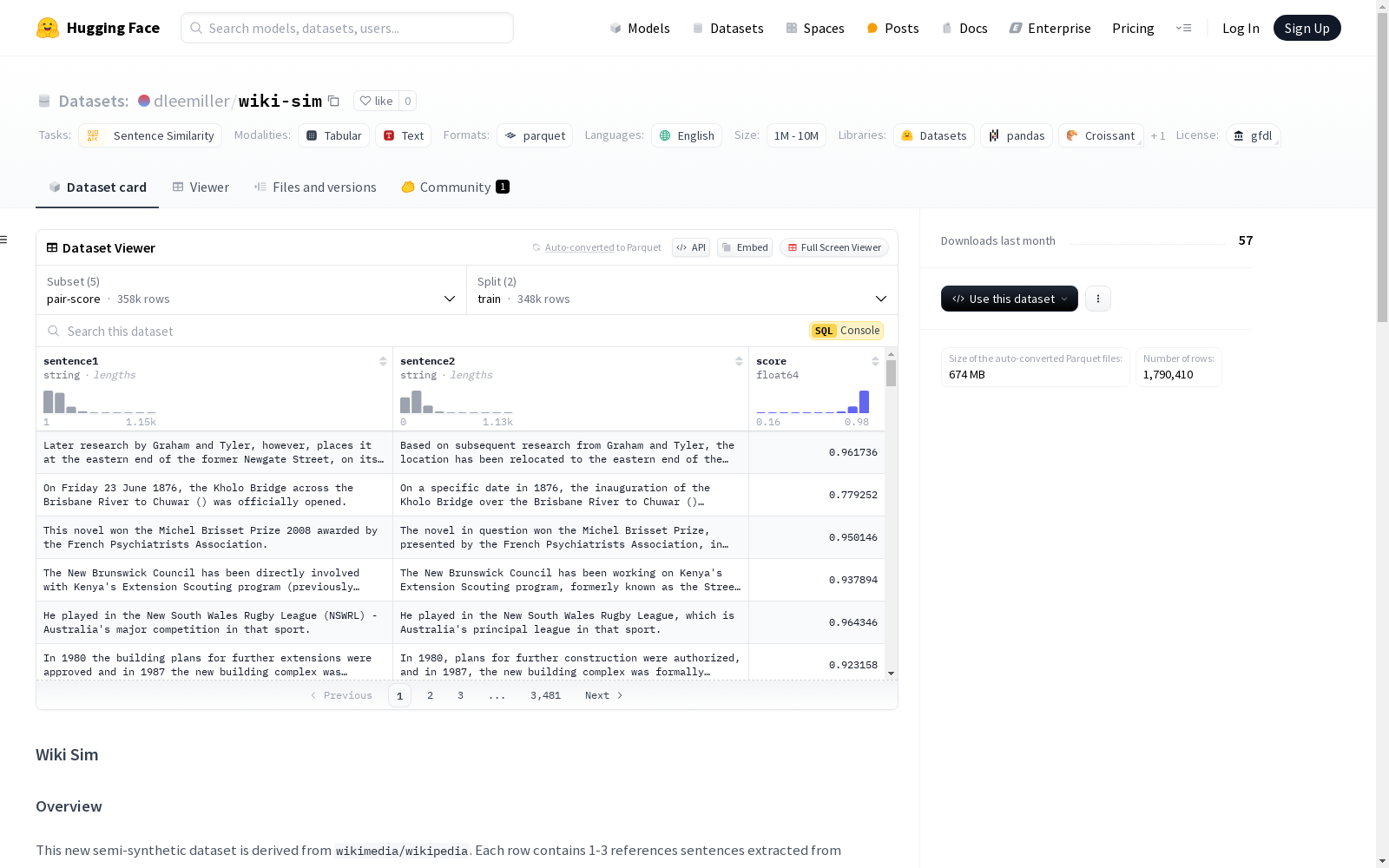
wiki-sim
收藏Hugging Face2024-12-09 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/dleemiller/wiki-sim
下载链接
链接失效反馈官方服务:
资源简介:
Wiki Sim是一个半合成数据集,源自`wikimedia/wikipedia`。每行包含1-3个参考句子,并生成4个相似句子:同义词替换、改写、概念重叠和上下文意义。使用`cross-encoder/stsb-roberta-large`评分,并挖掘硬负样本。数据集用于扩展小型模型和通用嵌入模型的训练,包含多个子集。
Wiki Sim is a semi-synthetic dataset derived from the `wikimedia/wikipedia` corpus. Each row contains 1 to 3 reference sentences, and 4 similar sentences are generated for these references via four distinct strategies: synonym replacement, paraphrasing, concept overlap retention, and contextual meaning preservation. Similarity scores are calculated using the `cross-encoder/stsb-roberta-large` model, and hard negative samples are mined from the dataset. This dataset is designed to augment training for small-scale models and general-purpose embedding models, and includes multiple subsets.
创建时间:
2024-12-09
原始信息汇总
Wiki Sim 数据集
概述
Wiki Sim 是一个从 wikimedia/wikipedia 派生的半合成数据集。每行包含 1-3 个从原始数据集中提取的参考句子。
对于每个参考句子,使用优化的 DSPy 程序生成 4 个相似句子:
- 同义词替换(用同义词替换单词以保持相同含义)
- 改写(使用不同的结构改写句子,同时保持相同的想法)
- 概念重叠(以不同的方式表达相关概念,而不改变核心含义)
- 上下文意义(修改句子以从上下文中推导出意义,保留原始意图)
此外,使用 cross-encoder/stsb-roberta-large 对每个结果进行评分。通过这种方式,从原始段落中的不同连续句子中挖掘出硬负样本,保留最相似的结果。
目的
该数据集旨在扩展小型模型(如 WordLlama)、通用嵌入模型以及针对 stsb 和相似性任务的基准训练。
数据集
数据集的列包括:
synonymparaphraseconceptual_overlapcontextual_meaningreferencenegativenegative_scoremodel_idcross_encodersynonym_scoreparaphrase_scoreconceptual_overlap_scorecontextual_meaning_score
其中,reference 和 negative 是从 wikimedia/wikipedia 派生的,相似文本列是合成生成的。过滤掉所有负样本分数超过任何相似性分数的行。
结果
4 种指令类型产生不同相似性分数的结果,最相似的是 synonym,最不相似的是 contextual meaning。
子集
pair-score- 随机选择,权重目标为 0.9pair-score-hard- 随机选择,权重目标为 0.85triplet- 随机选择,权重目标为 0.9triplet-hard- 随机选择,权重目标为 0.85raw- 完整数据集
搜集汇总
数据集介绍
构建方式
在构建wiki-sim数据集时,研究者们从`wikimedia/wikipedia`中提取了参考句子,并利用优化的DSPy程序生成了四种类型的相似句子:同义词替换、改写、概念重叠和上下文意义。每种类型都旨在保持或扩展原始句子的核心含义。此外,通过使用`cross-encoder/stsb-roberta-large`对生成的句子进行评分,进一步挖掘了原始段落中不同连续句子之间的硬负样本,确保了数据集的多样性和挑战性。
使用方法
使用wiki-sim数据集时,用户可以根据需求选择不同的配置,如`pair-score`、`pair-score-hard`、`triplet`、`triplet-hard`或`raw`全数据集。这些配置分别针对不同的相似性评分目标,适用于训练和评估小型模型、通用嵌入模型以及针对stsb和相似性任务的基准测试。数据集的多样性和评分机制使其成为提升模型在语义相似性任务中表现的有力工具。
背景与挑战
背景概述
Wiki-Sim数据集是一个基于`wikimedia/wikipedia`的半合成数据集,由专业研究人员或机构于近期创建。该数据集的核心研究问题聚焦于句子相似度的生成与评估,旨在为小型模型如WordLlama以及通用嵌入模型提供训练资源,并针对句子相似度任务(如stsb)进行优化。通过使用优化的DSPy程序,数据集生成了四种不同类型的相似句子:同义词替换、改写、概念重叠和上下文意义修改,并利用`cross-encoder/stsb-roberta-large`对结果进行评分。这一数据集的推出,不仅丰富了句子相似度领域的研究资源,还为模型训练提供了更为精细的负样本挖掘,推动了相关领域的技术进步。
当前挑战
Wiki-Sim数据集在构建过程中面临多项挑战。首先,生成高质量的相似句子需要精确的同义词替换、改写和概念重叠处理,确保生成的句子在语义上与原句高度一致。其次,负样本的挖掘与筛选过程复杂,需确保负样本与正样本之间的相似度差异显著,以提升模型的区分能力。此外,数据集的多样性和平衡性也是一大挑战,需在不同类型的相似句子之间保持合理的分布,以避免模型训练中的偏差。最后,数据集的规模和质量需在生成效率与准确性之间找到平衡,确保数据集既足够大以支持深度学习模型的训练,又具备高质量以提升模型的泛化能力。
常用场景
经典使用场景
在自然语言处理领域,wiki-sim数据集的经典使用场景主要集中在句子相似度任务中。该数据集通过从原始维基百科数据中提取参考句子,并生成四种不同类型的相似句子(同义词替换、改写、概念重叠和上下文意义),为模型提供了丰富的训练样本。这些样本不仅涵盖了语义上的细微差异,还通过交叉编码器评分机制,确保了相似度的精确度。因此,wiki-sim数据集常被用于训练和评估句子嵌入模型,特别是在需要高精度相似度判定的场景中,如文本匹配和信息检索。
解决学术问题
wiki-sim数据集在学术研究中解决了句子相似度任务中的多个关键问题。首先,它通过生成多样化的相似句子,有效缓解了传统数据集中相似样本单一的问题,提升了模型的泛化能力。其次,通过引入交叉编码器评分机制,数据集能够精确区分不同类型的相似度,为研究者提供了更细致的相似度评估标准。此外,该数据集还为小模型如WordLlama的训练提供了支持,推动了轻量级嵌入模型的研究进展。
实际应用
在实际应用中,wiki-sim数据集广泛应用于文本匹配、信息检索和问答系统等领域。例如,在搜索引擎中,该数据集可以帮助提升查询与文档的匹配精度,从而改善用户体验。在自动摘要和文本生成任务中,wiki-sim数据集的相似句子生成机制可以用于生成多样化的文本变体,增强生成模型的创造性和准确性。此外,在法律文书和医疗记录的相似性分析中,该数据集也能提供高精度的相似度判定,支持专业领域的文本分析需求。
数据集最近研究
最新研究方向
在自然语言处理领域,句子相似度任务一直是研究的热点之一。Wiki-Sim数据集通过从维基百科中提取句子并生成多种相似句,为这一领域提供了丰富的资源。最新的研究方向主要集中在利用该数据集优化小模型(如WordLlama)的训练,以及提升通用嵌入模型的性能。此外,该数据集还为句子相似度任务提供了多样化的训练和测试数据,特别是在处理复杂语境下的句子相似度问题上,具有重要的研究价值。通过引入难负样本挖掘技术,Wiki-Sim不仅增强了模型的鲁棒性,还为跨领域应用提供了新的可能性。
以上内容由遇见数据集搜集并总结生成


