InteractComp
收藏Hugging Face2025-10-29 更新2025-10-30 收录
下载链接:
https://huggingface.co/datasets/Rubbisheep/InteractComp
下载链接
链接失效反馈官方服务:
资源简介:
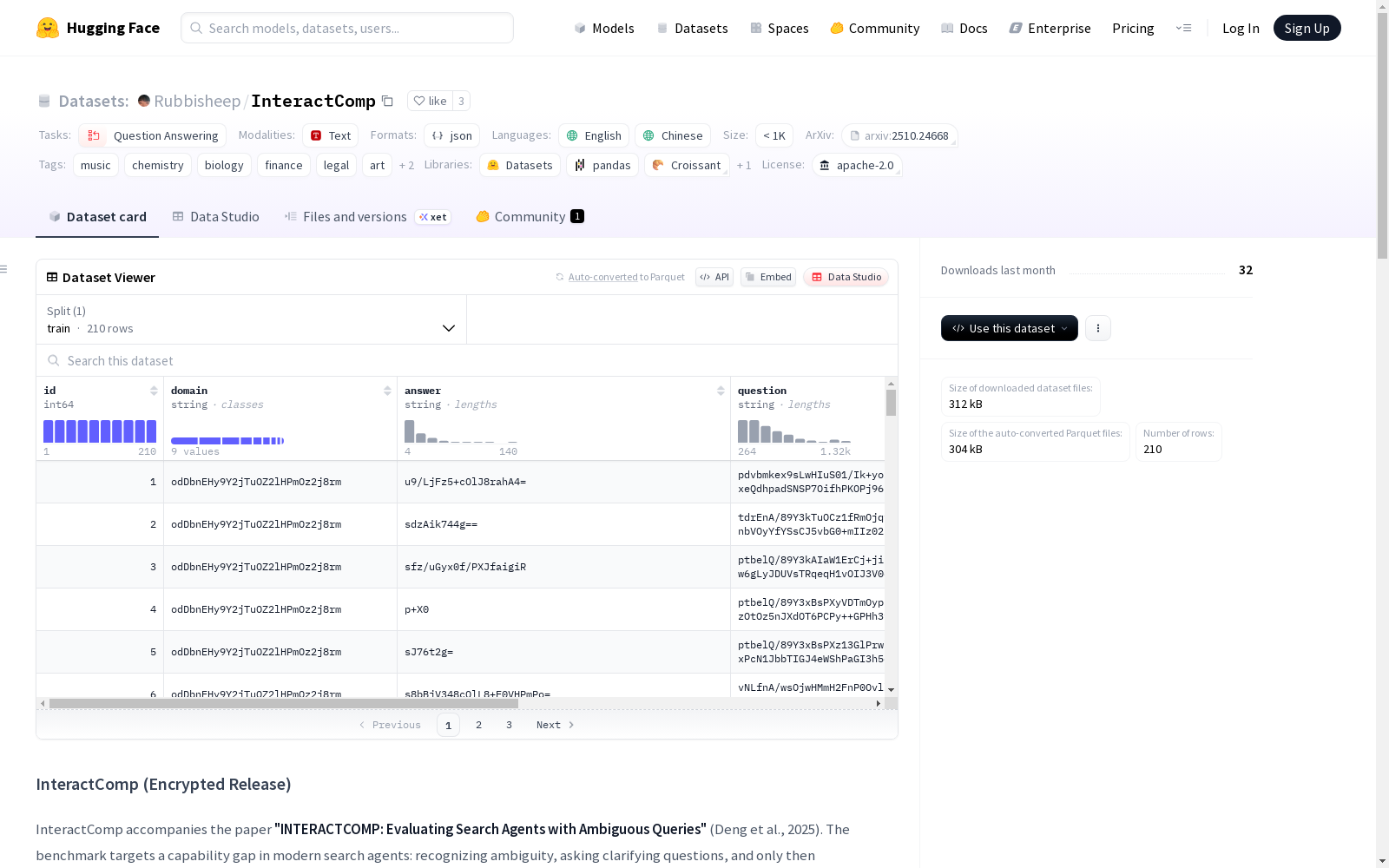
InteractComp数据集是一个用于评估和训练搜索代理在处理模糊查询时的交互能力的数据集。它包含了210个由人类编写的任务,这些任务跨越9个不同的网络领域,每个任务都包含一个模糊问题、相关的上下文信息、正确答案以及任务元数据。数据集通过加密方式发布,以确保数据的安全性和隐私性。
The InteractComp dataset is a dataset designed for evaluating and training the interactive capabilities of search agents when handling ambiguous queries. It includes 210 human-written tasks spanning 9 distinct web domains, with each task containing an ambiguous question, relevant contextual information, a correct answer, and task metadata. The dataset is distributed via encryption to ensure data security and privacy.
创建时间:
2025-10-29
原始信息汇总
InteractComp 数据集概述
数据集基本信息
- 许可证: Apache-2.0
- 任务类别: 问答
- 支持语言: 英语、中文
- 领域标签: 音乐、化学、生物、金融、法律、艺术、医疗、智能体
- 数据规模: 小于1K样本
核心内容
- 任务数量: 210个人工编写的任务
- 覆盖领域: 9个网络领域
- 任务结构: 每个实例包含故意模糊的问题、用于消歧的目标上下文、真实答案和元数据
方法论特点
- 目标-干扰项方法: 选择目标实体和流行干扰项,仅使用共享属性编写问题,提供最小上下文暴露目标独特特征
- 交互敏感性: 模糊性只能通过交互解决
- 透明构建流程: 五步构建过程确保每个项目具有挑战性但易于验证
研究价值
- 评估重点: 评估搜索代理在模糊查询下的交互能力
- 性能表现: 标准设置下GPT-5准确率13.73%,强制广泛交互时超过24%,提供完整消歧上下文可达71.5%
- 纵向发现: 15个月内BrowseComp准确率增长七倍,而InteractComp停滞在6%-14%
技术实现
- 加密方案: 使用共享canary令牌进行XOR加密,SHA-256流派生,Base64编码
- 解密工具: 提供Python解密脚本,支持自定义字段和canary值
- 文件结构: 包含加密数据集文件和解密工具
使用条款
- 用途限制: 非商业研究用途
- 引用要求: 使用需引用相关论文
- 访问控制: 建议保持canary令牌机密性,可生成按接收者加密变体
搜集汇总
数据集介绍
构建方式
在交互式搜索代理研究领域,InteractComp数据集通过严谨的五阶段构建流程实现:首先选定目标实体与干扰项,提取二者共享属性构建模糊问题,随后基于目标实体独特特征生成上下文片段,最终形成包含完整推理路径的标注数据。这种目标-干扰项方法论确保了每个任务必须通过交互才能消解歧义,既避免了捷径推理又保持了验证的透明度。
使用方法
研究者需通过配套解密工具处理加密的JSONL文件,运行Python脚本时指定输入输出路径及密钥字段即可获取明文数据。数据集支持字段级解密与令牌定制,建议通过哈希校验确保数据完整性。该资源专用于非商业的交互代理研究,使用时需遵循论文中的伦理规范并引用相关文献。
背景与挑战
背景概述
InteractComp数据集由Deng等研究人员于2025年创建,旨在填补现代搜索代理在处理模糊查询时的能力空白。该数据集聚焦于交互式搜索场景,要求智能体能够识别查询中的歧义性、主动提出澄清问题,并在充分交互后执行检索或回答任务。其设计覆盖音乐、化学、生物、金融、法律等九个专业领域,通过210项人工构建的任务推动对话系统与信息检索技术的交叉研究。该基准不仅揭示了当前智能体在交互行为上的系统性缺陷,更为多轮对话理解与主动学习机制的发展提供了重要实验平台。
当前挑战
该数据集核心挑战在于解决模糊查询下的交互式搜索问题,要求模型突破传统单轮问答的局限,具备动态感知歧义与主动澄清的能力。构建过程中面临双重挑战:一是需精心设计目标实体与干扰项,通过共享属性构造自然歧义,同时确保上下文片段能唯一标识目标特征;二是必须建立可验证的交互链路,避免模型通过捷径推理获得答案,从而真实反映智能体在多轮对话中的认知与决策能力。
常用场景
经典使用场景
在交互式智能代理研究领域,InteractComp数据集通过精心设计的模糊查询任务,为评估搜索代理的交互能力提供了标准化测试平台。该数据集模拟真实网络搜索场景,要求代理识别查询中的歧义性、主动提出澄清问题,并在获取关键信息后执行检索或回答。这种设计使得研究者能够系统性地衡量代理在动态对话环境中的表现,尤其适用于多轮交互式问答系统的开发与优化。
解决学术问题
InteractComp直面现代搜索代理在模糊查询处理中的核心缺陷,揭示了当前模型在交互行为上的发展瓶颈。通过长达15个月的纵向研究,该数据集证明尽管代理在明确查询任务上取得显著进步,但在需要主动澄清的模糊场景中性能持续停滞。这一发现促使学界重新审视交互式人工智能的评估范式,推动了针对歧义识别、对话策略生成等关键能力的理论研究与技术突破。
实际应用
该数据集的实际价值体现在智能客服、专业领域知识检索等现实场景中。当用户在音乐、医疗、金融等领域提出含混不清的查询时,基于InteractComp训练的代理能够通过智能对话快速锁定用户真实需求。例如在法律咨询场景中,系统可通过交互式提问厘清案件细节,显著提升信息检索的准确性与服务效率,为构建更人性化的智能交互系统奠定基础。
数据集最近研究
最新研究方向
在交互式搜索智能体领域,InteractComp数据集揭示了当前系统处理模糊查询的能力瓶颈。前沿研究聚焦于开发能够主动识别歧义、生成澄清问题并执行精准检索的对话代理,这一方向因数据集揭示的交互性能停滞现象而备受关注。跨领域任务设计促使研究者探索多模态上下文理解与动态决策机制的融合,特别是在医疗、金融等高风险场景中,交互式搜索的可靠性已成为行业热点。该基准通过目标-干扰项方法论构建的评估体系,为可解释人工智能的发展提供了重要参照,推动着下一代搜索系统从被动响应向主动协作的范式转变。
以上内容由遇见数据集搜集并总结生成


