MM-Hallu/MM-UPD
收藏Hugging Face2026-04-25 更新2026-04-26 收录
下载链接:
https://hf-mirror.com/datasets/MM-Hallu/MM-UPD
下载链接
链接失效反馈官方服务:
资源简介:
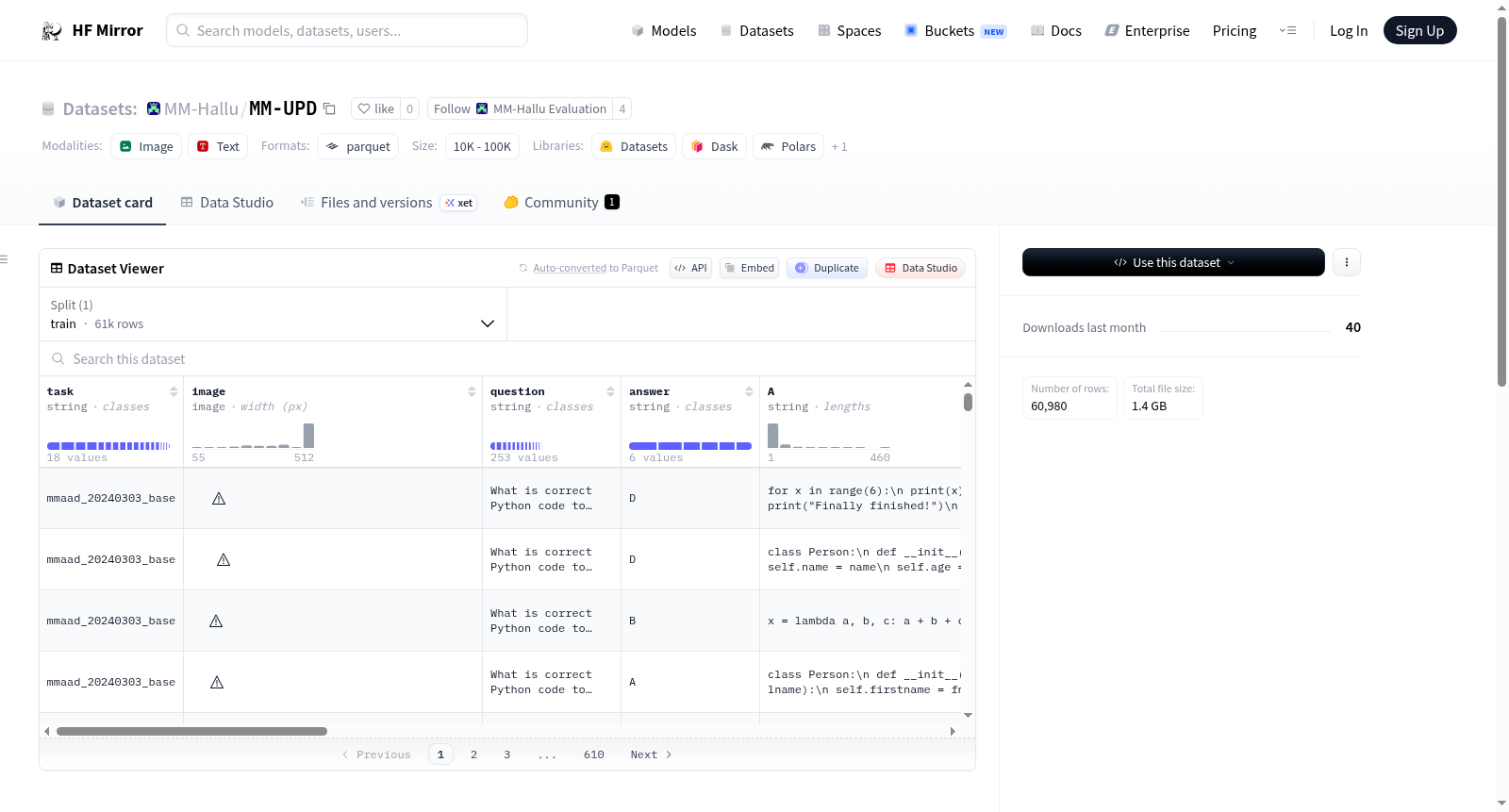
MM-UPD(多模态理解偏好数据集)是一个用于评估多模态模型是否能区分对图像的幻觉描述和真实描述的基准数据集。它包括三个子任务:AAD(属性异常检测)、IASD(不适当答案选择检测)和IVQD(不正确视觉问题检测)。数据集包含任务名称、输入图像、问题、正确答案选项、选项文本、提示、问题类别、二级类别、问题类型和数据源标识符等字段。总共有60,980个示例,分布在18个子任务中。
MM-UPD (Multimodal Understanding Preference Dataset) is a benchmark for evaluating whether multimodal models can distinguish between hallucinated and truthful descriptions of images. It includes three sub-tasks: AAD (Attribute Anomaly Detection), IASD (Inappropriate Answer Selection Detection), and IVQD (Incorrect Visual Question Detection). The dataset contains fields such as task name, input image, question, correct answer option, option text, hint, question category, second-level category, question type, and data source identifier. There are a total of 60,980 examples across 18 sub-tasks.
提供机构:
MM-Hallu
搜集汇总
数据集介绍
构建方式
MM-UPD(多模态理解偏好数据集)是专为评估多模态模型是否具备区分图像真实描述与幻觉描述能力而设计的基准数据集。该数据集精心整合了60,980个样本,横跨18个子任务,其构建过程基于对原始数据源的系统转换与标注。每个样本均包含图像、问题、正确选项字母、选项文本、提示信息、类别及来源等字段,通过多维度的标注策略确保样本覆盖属性异常检测、不当答案选择检测及错误视觉问题检测三大核心任务,从而构建出严谨且富有挑战性的评估框架。
特点
该数据集以多模态幻觉检测为核心,聚焦于AAD(属性异常检测)、IASD(不当答案选择检测)和IVQD(错误视觉问题检测)三个子任务,呈现出高度结构化的任务划分特点。每个样本均提供图像与问题的配对,并附有明确的标准答案选项与多级类别标签(如category与l2-category),使得模型表现可被精细分析。此外,数据集包含可选的hint字段以提供额外上下文,并区分了standard、aad、iasd、ivqd等题型,充分体现了其任务多样性与评估粒度。
使用方法
使用MM-UPD数据集时,研究者可直接从HuggingFace加载默认配置的Parquet格式数据,按train-*.parquet文件读取训练样本。每个样本通过字段如image、question、answer及A/B/C/D选项进行模型输入与推理验证,适用于多模态模型的零样本评估或微调训练。建议利用task字段区分不同子任务,结合category与type信息进行分组评估,从而系统性考察模型在幻觉检测、视觉问答准确性等维度的能力,并借助hint字段开展上下文敏感性分析。
背景与挑战
背景概述
MM-UPD(多模态理解偏好数据集)由相关研究机构于近期创建,聚焦于多模态模型在图像描述真实性判别中的核心能力评估。该数据集旨在解决多模态大模型在面对图像时容易产生幻觉描述或错误选择的问题,通过设计三个子任务——属性异常检测(AAD)、不当答案选择检测(IASD)以及错误视觉问答检测(IVQD),系统性地衡量模型对图像内容准确理解的能力。包含60,980个样本,覆盖18个子任务,为多模态领域提供了一套严谨的基准测试工具,对推动模型细粒度感知与抗幻觉能力研究具有重要影响。
当前挑战
该数据集所应对的领域挑战在于多模态模型普遍存在的幻觉现象,即对图像生成不真实或不准确的语言描述,这严重制约了模型在医疗诊断、自动驾驶等高风险场景中的可靠性。具体挑战包括:模型难以区分细微的属性偏差(如颜色、形状的误判),面对干扰选项时易选择与视觉事实相悖的答案,且对视觉问答中的错误信息缺乏有效判别力。在构建过程中,挑战则体现在如何设计高质量的反事实样本、确保问题覆盖多样化的视觉常识场景,以及为每项任务定义客观的评判标准,以避免主观偏差并提升数据集的可泛化性。
常用场景
经典使用场景
MM-UPD数据集的经典使用场景在于评估多模态大模型在图像理解任务中辨别真实描述与幻觉描述的能力。该数据集精心设计了三个核心子任务:属性异常检测(AAD)用于检验模型能否识别图像中对象属性的错误表述;不当答案选择检测(IASD)考察模型在选择答案时是否受错误干扰;错误视觉问答检测(IVQD)则评估模型对视觉问答正确性的判断。这些场景共同构成了对多模态模型鲁棒性和忠实性的全面考验,是衡量其是否真正理解视觉内容的基石。
解决学术问题
学术界长期面临多模态模型生成与现实不符的幻觉描述问题,这严重制约了模型在可信视觉推理任务中的应用。MM-UPD通过提供包含近六万条精心标注样本的基准数据集,系统性地揭示了模型在属性、关系和问答层面上的幻觉倾向。该数据集解决了如何量化模型对视觉内容忠实度的难题,推动了多模态幻觉检测与校正研究的发展,其影响在于引领学界从单一的准确性评估转向对模型输出真实性的深层审视。
衍生相关工作
围绕MM-UPD数据集,衍生出多项经典工作。研究者在属性异常检测子任务基础上,开发了基于对比学习和因果推断的幻觉抑制模型,通过显式区分属性绑定与关系推理来提升鲁棒性。另有工作利用该数据集中的IASD任务训练了多模态置信度估计网络,实现了对模型回答不确定性的量化。这些衍生研究不仅深化了对多模态幻觉机制的理解,还催生了面向特定场景的专用去幻框架,持续拓展着多模态学习的边界。
以上内容由遇见数据集搜集并总结生成


