ALIA_syntethic_MT
收藏Hugging Face2025-12-16 更新2025-12-17 收录
下载链接:
https://huggingface.co/datasets/HiTZ/ALIA_syntethic_MT
下载链接
链接失效反馈官方服务:
资源简介:
ALIA Synthetic MT是一个从Berria新闻文章衍生的平行语料库,包含2025年发布的内容以及2023年的存档材料。该数据集提供了使用两种不同的大型语言模型(Qwen3-32B和LatxaQ)生成的英语和西班牙语合成翻译。数据集以JSONL文件格式组织,每个条目包含id、eu(巴斯克语)、en(英语)和es(西班牙语)字段。该数据集旨在用于机器翻译模型的训练和评估、合成数据实验以及多语言NLP研究。数据集包含68,863个文档,Qwen3-32B模型平均每个文档有9.50个段落,LatxaQ模型平均每个文档有7.79个段落。
ALIA Synthetic MT is a parallel corpus derived from Berria news articles, containing content released in 2025 and archived materials from 2023. This dataset provides synthetic English and Spanish translations generated using two distinct Large Language Models (LLMs): Qwen3-32B and LatxaQ. The dataset is organized in JSONL file format, with each entry containing fields for id, eu (Basque), en (English), and es (Spanish). It is intended for training and evaluating machine translation models, synthetic data experiments, and multilingual natural language processing (NLP) research. The dataset comprises 68,863 documents, with the Qwen3-32B model averaging 9.50 paragraphs per document and the LatxaQ model averaging 7.79 paragraphs per document.
提供机构:
HiTZ zentroa
创建时间:
2025-12-16
原始信息汇总
ALIA Synthetic MT 数据集概述
数据集基本信息
- 数据集名称:ALIA Synthetic MT
- 许可证:apache-2.0
- 任务类别:翻译
- 涉及语言:巴斯克语 (eu)、英语 (en)、西班牙语 (es)
- 规模类别:100K < n < 1M
数据来源与内容
- 来源:基于 Berria 新闻文章,包含2025年发布的内容以及2023年的存档材料。
- 内容:一个平行语料库,提供由大型语言模型生成的英语和西班牙语合成翻译。
数据集配置与结构
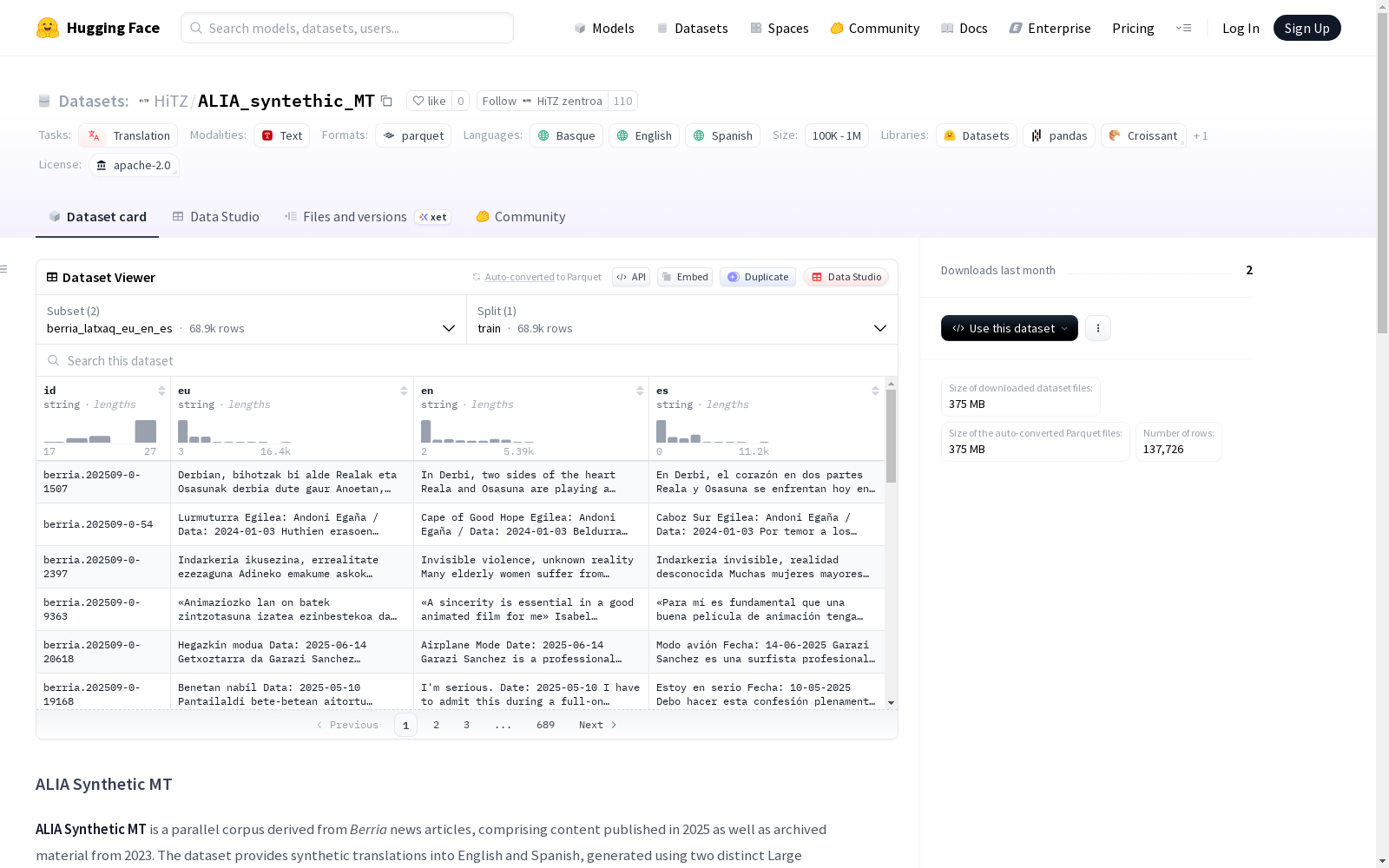
数据集包含两个配置,均采用JSONL格式。每个条目包含以下字段:id(唯一文档标识符)、eu(巴斯克语原文)、en(合成英语翻译)、es(合成西班牙语翻译)。
配置一:berria_latxaq_eu_en_es
- 训练集大小:68,863 个样本
- 训练集字节数:278,100,538 字节
- 下载大小:157,902,013 字节
- 数据集大小:278,100,538 字节
配置二:berria_qwen3_eu_en_es
- 训练集大小:68,863 个样本
- 训练集字节数:363,531,102 字节
- 下载大小:217,240,835 字节
- 数据集大小:363,531,102 字节
翻译模型详情
用于生成翻译的两个大型语言模型:
- Qwen3-32B:一个先进的多语言大语言模型。
- LatxaQ:Qwen3-32B的领域适应迭代版本。它保留了Latxa家族固有的巴斯克语言和文化能力,同时利用了Qwen架构的先进多语言基础。
- 可用性说明:LatxaQ目前是一个非公开的研究模型,计划在来年公开发布。
数据集统计
- 总文档数:68,863
- 平均段落数:Qwen3-32B模型生成的文档平均为9.50段,LatxaQ模型生成的文档平均为7.79段。
预期用途
- 机器翻译模型的训练和评估
- 合成数据实验
- 多语言自然语言处理研究
- 注意:由于翻译是合成的,可能包含模型特定的伪影,因此在解释训练或评估结果时应考虑到这一点。
许可证说明
请参考原始Berria文章的许可证。合成翻译继承与源数据相同的使用限制。
联系与引用
- 联系:如有问题,请联系ALIA / HiTZ团队或在Hugging Face数据集存储库中提交问题。
- 引用:如果在工作中使用此数据集,请引用ALIA项目及所使用的相应翻译模型。
搜集汇总
数据集介绍
构建方式
在机器翻译研究领域,高质量平行语料的获取尤为关键。ALIA Synthetic MT数据集的构建源于对巴斯克语新闻资源的深度挖掘,其核心源文本取自《Berria》新闻社于2023年至2025年间发布的文章。构建过程采用了前沿的大语言模型技术,通过Qwen3-32B与LatxaQ这两个模型,分别对原始巴斯克语文本进行自动化翻译,生成了对应的英语和西班牙语译文,从而形成了一个包含近六万九千个文档的三语平行语料库。
特点
该数据集的一个显著特征在于其双语译文的生成方式,提供了由两个不同模型产出的翻译版本,这为研究模型偏差与翻译质量对比提供了独特资源。数据集严格遵循原文的时间跨度与新闻领域特性,确保了语料的时效性与领域一致性。每个数据条目均包含唯一标识符与三种语言的文本,结构清晰完整,便于直接用于模型训练与评估。
使用方法
研究者可将本数据集直接应用于神经机器翻译模型的训练与微调,尤其适用于涉及巴斯克语的多语言翻译任务。在评估环节,该语料可用于衡量不同翻译模型在新闻领域的性能表现。鉴于译文由模型合成,使用时需注意其中可能存在的模型特定痕迹,建议在分析结果时结合人工评估或其他高质量参考译文进行交叉验证。
背景与挑战
背景概述
在低资源语言机器翻译研究领域,巴斯克语(Euskera)因其独特的语言结构和有限的平行语料资源,长期面临数据稀缺的挑战。ALIA_syntethic_MT数据集由ALIA/HiTZ研究团队于近期构建,其核心研究问题旨在通过大规模语言模型生成高质量合成翻译,以扩充巴斯克语与英语、西班牙语之间的平行语料。该数据集源自《Berria》新闻文章,涵盖2023年至2025年的内容,并利用Qwen3-32B与LatxaQ两种先进模型进行翻译生成,为巴斯克语机器翻译模型的训练与评估提供了关键数据支撑,显著推动了低资源语言自然语言处理技术的发展。
当前挑战
该数据集致力于解决低资源语言机器翻译中数据匮乏的根本性挑战,其构建过程面临多重困难。一方面,巴斯克语作为孤立语言,语法结构与印欧语系差异显著,确保合成翻译在语义忠实性与语言流畅度上的平衡尤为复杂;另一方面,依赖大规模语言模型生成数据可能引入模型特有的偏见与语言风格,影响下游任务的泛化性能。此外,数据集构建需严格遵循原始新闻数据的许可协议,并在模型选择上权衡公开可用性与领域适应性,例如LatxaQ作为非公开研究模型,其可复现性与长期访问性存在一定限制。
常用场景
经典使用场景
在机器翻译研究领域,ALIA Synthetic MT数据集为低资源语言处理提供了宝贵的实验资源。该数据集以巴斯克语新闻文本为源,通过大型语言模型生成了高质量的英语和西班牙语平行译文,典型应用场景包括训练和评估神经机器翻译系统。研究者可利用其对比不同模型生成的合成译文质量,探索数据增强策略,或分析跨语言表示学习中的迁移效应,尤其在处理像巴斯克语这类语法结构独特、资源相对匮乏的语言时,该数据集能够有效支撑翻译模型的性能优化与泛化能力验证。
解决学术问题
该数据集主要针对低资源机器翻译中的数据稀缺问题,为巴斯克语这类语料有限的语言提供了大规模、高质量的平行语料。它有助于解决传统翻译模型因训练数据不足而导致的性能瓶颈,支持研究者深入探究合成数据在提升翻译准确性、缓解领域适应困难以及改善多语言对齐等方面的作用。通过对比Qwen3-32B与LatxaQ两种模型的生成结果,该数据集进一步推动了关于领域适应模型与通用大语言模型在翻译任务中差异性的学术讨论,为低资源自然语言处理技术的创新提供了实证基础。
衍生相关工作
围绕ALIA Synthetic MT数据集,已衍生出一系列聚焦于低资源机器翻译与合成数据效用的经典研究工作。例如,基于该数据集的实验常被用于评估领域适应模型如LatxaQ在保留巴斯克语语言特性方面的效能,并与通用大模型Qwen3-32B进行对比分析。相关研究进一步探索了合成数据在数据增强、噪声鲁棒性训练以及多语言预训练模型微调中的应用策略,这些工作不仅深化了对合成语料质量评估方法的理解,也为后续构建更高效的巴斯克语翻译模型奠定了方法论基础。
以上内容由遇见数据集搜集并总结生成


