mevol/protein_structure_NER_model_v1.2
收藏Hugging Face2023-11-01 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/mevol/protein_structure_NER_model_v1.2
下载链接
链接失效反馈资源简介:
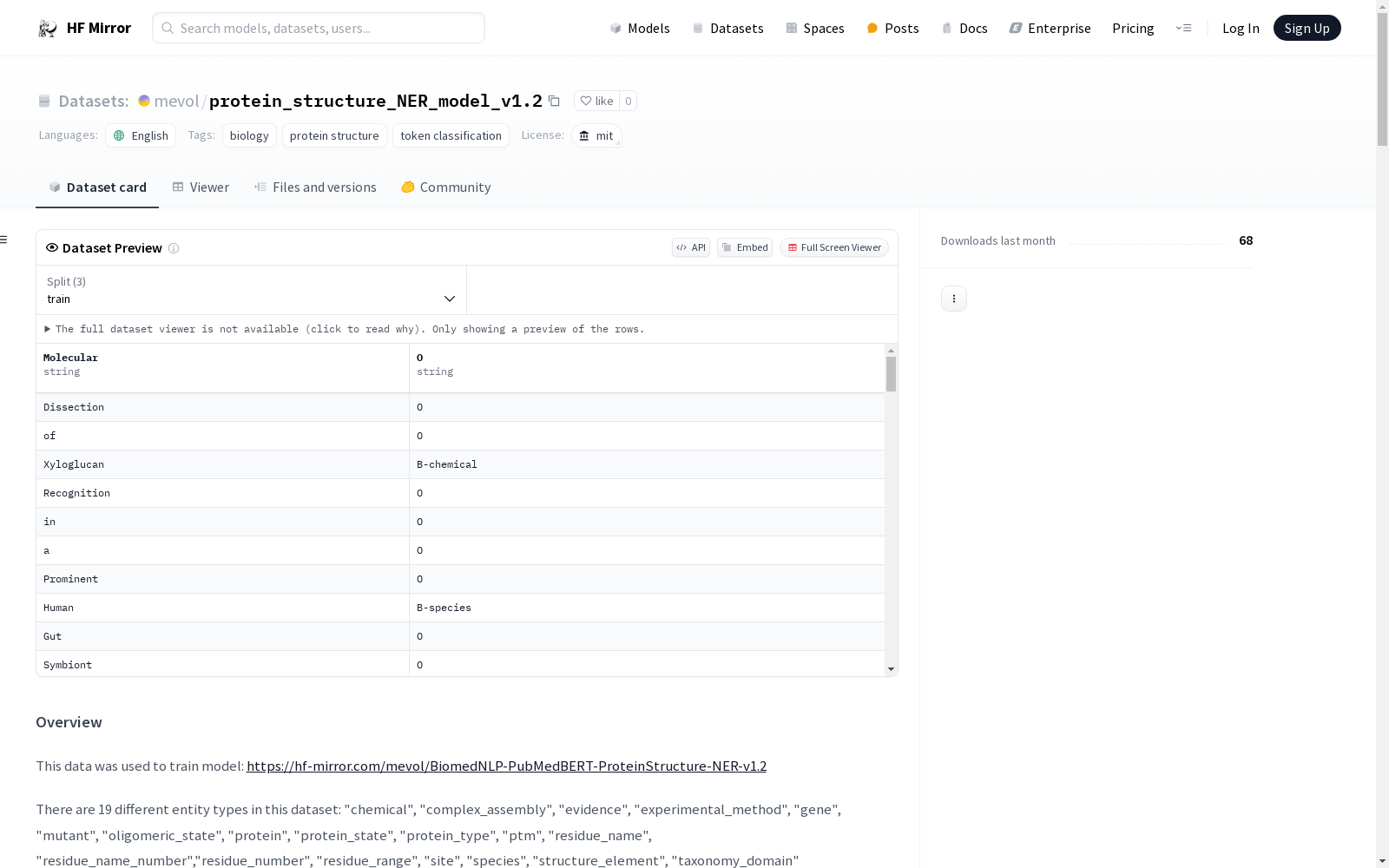
该数据集主要用于训练蛋白质结构命名实体识别(NER)模型,包含19种不同的实体类型,如化学物质、基因、蛋白质等。数据集以IOB格式为主,同时也提供了JSON、XML和CSV格式的注释文件。注释工作使用了TeamTat工具,数据来源于BioC XML文件,并转换为多种格式。数据集包含10个文档,总计10409个注释和1961个句子。
This dataset is primarily used for training protein structure named entity recognition (NER) models. It includes 19 distinct entity types, such as chemicals, genes, proteins, and others. The dataset predominantly adopts the IOB annotation format, while annotation files in JSON, XML and CSV formats are also provided. Annotations were created using the TeamTat tool, with the source data obtained from BioC XML files and converted into multiple formats. The dataset contains 10 documents, with a total of 10,409 annotations and 1,961 sentences.
提供机构:
mevol
原始信息汇总
数据集概述
数据集信息
- 许可证: MIT
- 语言: 英语
- 标签: 生物学, 蛋白质结构, 标记分类
- 配置:
- 配置名称: protein_structure_NER_model_v1.2
- 数据文件:
- 训练集:
annotation_IOB/train.tsv - 开发集:
annotation_IOB/dev.tsv - 测试集:
annotation_IOB/test.tsv
- 训练集:
实体类型
该数据集包含19种不同的实体类型:
- chemical
- complex_assembly
- evidence
- experimental_method
- gene
- mutant
- oligomeric_state
- protein
- protein_state
- protein_type
- ptm
- residue_name
- residue_name_number
- residue_number
- residue_range
- site
- species
- structure_element
- taxonomy_domain
数据格式
数据以IOB格式准备,用于训练、开发和测试。此外,还提供JSON、XML和CSV格式的数据。
数据统计
| 文档ID | BioC XML注释数量 | IOB/JSON/CSV注释数量 | 句子数量 |
|---|---|---|---|
| PMC4850273 | 1121 | 1121 | 204 |
| PMC4784909 | 865 | 865 | 204 |
| PMC4850288 | 716 | 708 | 146 |
| PMC4887326 | 933 | 933 | 152 |
| PMC4833862 | 1044 | 1044 | 192 |
| PMC4832331 | 739 | 718 | 134 |
| PMC4852598 | 1229 | 1218 | 250 |
| PMC4786784 | 1549 | 1549 | 232 |
| PMC4848090 | 987 | 985 | 191 |
| PMC4792962 | 1268 | 1268 | 256 |
| 总计 | 10451 | 10409 | 1961 |
数据文件
- 原始BioC XML文件: 位于
raw_BioC_XML目录下,每个文件名为unique PubMedCentral ID_raw.xml。 - IOB格式文件: 位于
annotation_IOB目录下,包括:all.tsv: 用于创建模型的所有句子和注释,共1961句。train.tsv: 训练集,共1372句。dev.tsv: 开发集,共294句。test.tsv: 测试集,共295句。
- BioC JSON文件: 位于
annotated_BioC_JSON目录下,每个文件名为unique PubMedCentral ID_ann.json。 - BioC XML文件: 位于
annotated_BioC_XML目录下,每个文件名为unique PubMedCentral ID_ann.xml。 - CSV文件: 位于
annotation_CSV目录下,每个文件名为unique PubMedCentral ID.csv。 - JSON文件: 位于
annotation_JSON目录下,文件名为annotations.json。
AI搜集汇总
数据集介绍
构建方式
该数据集通过使用TeamTat注释工具对生物医学文献进行标注,生成了一系列包含蛋白质结构相关实体的注释文件。这些文件首先以BioC XML格式下载,随后转换为IOB、JSON和CSV格式,以适应不同的模型训练和评估需求。具体而言,数据集包括训练、开发和测试三个子集,分别用于模型的训练、调优和验证。
特点
此数据集的显著特点在于其涵盖了19种不同的实体类型,包括化学物质、基因、蛋白质状态等,为蛋白质结构领域的命名实体识别提供了丰富的标注资源。此外,数据集提供了多种格式(如IOB、JSON、XML和CSV),便于不同应用场景下的数据处理和模型训练。
使用方法
使用该数据集时,用户可以根据需求选择合适的格式进行数据加载和处理。例如,对于需要进行命名实体识别任务的模型训练,可以选择IOB格式的文件进行输入。同时,数据集还提供了详细的文档和示例,帮助用户理解和解析注释信息,从而更有效地利用数据集进行研究和开发。
背景与挑战
背景概述
在生物信息学领域,蛋白质结构识别与命名实体识别(NER)是关键任务之一。mevol/protein_structure_NER_model_v1.2数据集由mevol团队创建,旨在通过提供丰富的蛋白质结构相关实体标注数据,推动生物医学文本处理技术的发展。该数据集包含了19种不同的实体类型,如化学物质、基因、蛋白质等,这些数据以IOB格式进行标注,并可转换为JSON、XML和CSV格式。数据集的构建基于PubMedBERT模型,通过TeamTat工具进行标注,涵盖了多个生物医学文献,为蛋白质结构识别提供了高质量的训练和测试数据。
当前挑战
尽管mevol/protein_structure_NER_model_v1.2数据集在蛋白质结构识别领域具有重要意义,但其构建过程中仍面临多项挑战。首先,生物医学文本的复杂性和多样性使得实体标注任务异常艰巨,需要高度专业化的知识和工具支持。其次,数据集的标注一致性和准确性是确保模型性能的关键,但不同标注者的主观差异可能导致标注质量的不一致。此外,数据集的规模和覆盖范围虽然广泛,但仍需不断扩展以应对日益增长的生物医学文献数量和多样性。最后,数据格式的多样性虽然提供了灵活性,但也增加了数据处理和模型训练的复杂性。
常用场景
经典使用场景
在生物信息学领域,mevol/protein_structure_NER_model_v1.2数据集被广泛用于蛋白质结构命名实体识别(NER)任务。该数据集通过标注蛋白质相关的多种实体类型,如化学物质、基因、突变体等,为模型训练提供了丰富的语料。其经典使用场景包括但不限于:利用该数据集训练的模型,能够自动识别和分类生物医学文献中的蛋白质相关实体,从而加速生物信息学研究中的数据提取和分析过程。
实际应用
在实际应用中,mevol/protein_structure_NER_model_v1.2数据集被广泛应用于生物医学文献的自动化处理和信息提取。例如,在药物研发过程中,研究人员可以利用该数据集训练的模型,快速识别和分析与药物靶点相关的蛋白质结构信息,从而加速药物筛选和设计。此外,该数据集还可用于临床研究中的文献综述和数据整合,提高研究效率和数据质量。
衍生相关工作
基于mevol/protein_structure_NER_model_v1.2数据集,衍生了一系列相关的经典工作。例如,研究人员利用该数据集开发了多种蛋白质结构命名实体识别模型,这些模型在多个生物医学文本处理任务中表现优异。此外,该数据集还被用于构建和验证生物医学知识图谱,促进了生物信息学领域的知识发现和应用。这些衍生工作不仅丰富了生物信息学的研究工具,也为相关领域的进一步发展提供了坚实的基础。
以上内容由AI搜集并总结生成


