tech-docs
收藏Hugging Face2024-12-10 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/saidsef/tech-docs
下载链接
链接失效反馈官方服务:
资源简介:
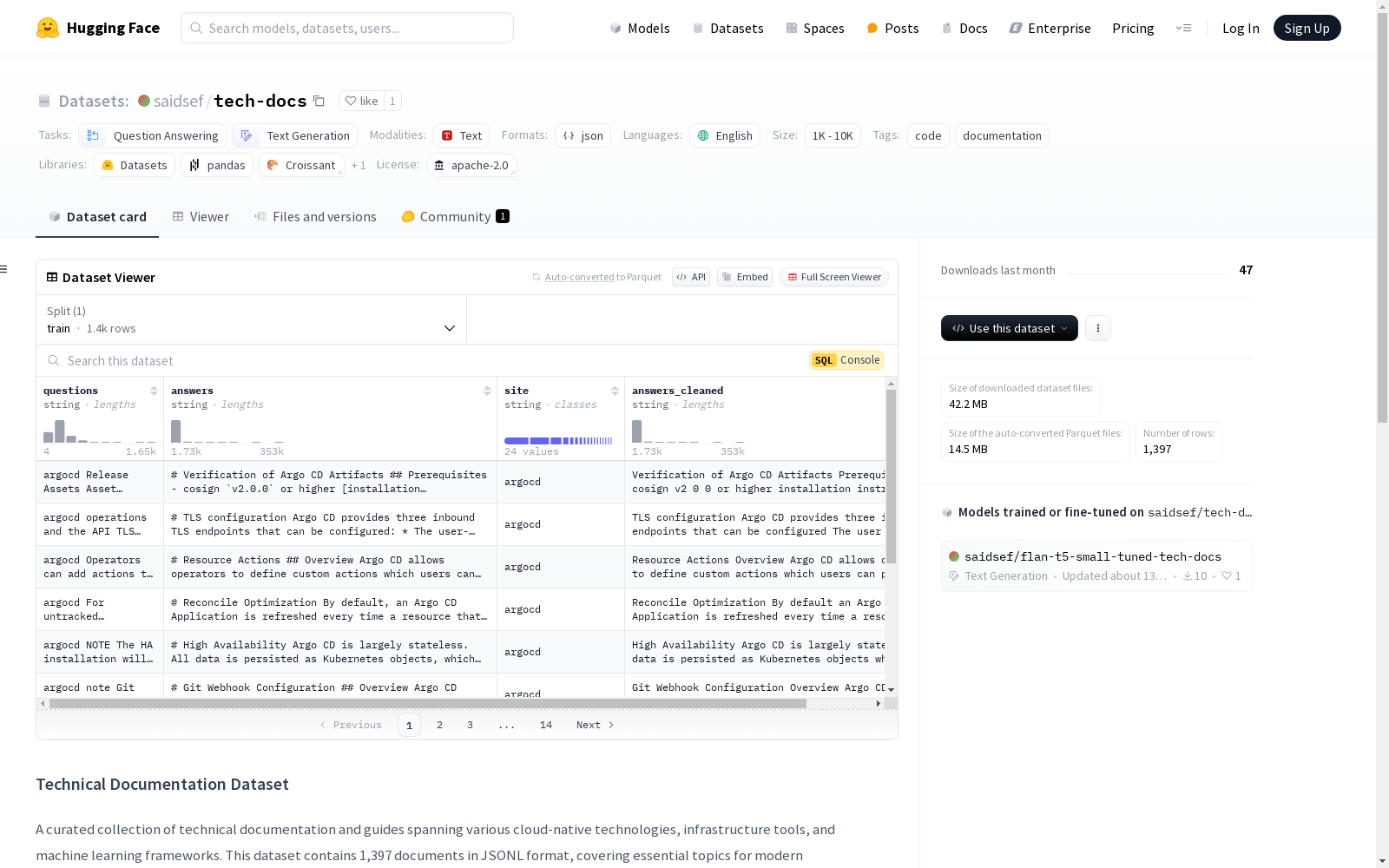
这是一个精选的技术文档和指南集合,涵盖了各种云原生技术、基础设施工具和机器学习框架。数据集包含1,397个JSONL格式的文档,覆盖了现代软件开发和DevOps实践的关键主题。文档涵盖多个领域,包括云平台、Kubernetes生态系统、基础设施即代码、可观测性、服务网格和机器学习等。数据集适用于技术文档系统、知识库、搜索实现和训练与文档相关的机器学习模型。
This is a curated collection of technical documents and guides covering various cloud-native technologies, infrastructure tools, and machine learning frameworks. The dataset contains 1,397 documents in JSONL format, covering key topics of modern software development and DevOps practices. The documents span multiple domains, including cloud platforms, Kubernetes ecosystem, Infrastructure as Code (IaC), observability, service mesh, machine learning and more. The dataset is suitable for technical documentation systems, knowledge bases, search implementations, and training machine learning models related to documentation.
创建时间:
2024-12-07
原始信息汇总
技术文档数据集
概述
该数据集是一个精选的技术文档和指南集合,涵盖了多种云原生技术、基础设施工具和机器学习框架。数据集包含1,397个文档,格式为JSONL,涵盖了现代软件开发和DevOps实践中的关键主题。
数据集内容
数据集包括以下多个领域的文档:
- 云平台:GCP(83个文档),EKS(33个文档)
- Kubernetes生态系统:Kubernetes参考(251个文档),ArgoCD(60个文档),Cilium(33个文档)
- 基础设施即代码:Terraform(151个文档)
- 可观测性:Prometheus(32个文档),Grafana(43个文档)
- 服务网格:Istio(33个文档)
- 机器学习:scikit-learn(55个文档)
- 其他:包括Docker、Redis、Linux以及各种与Kubernetes相关的工具
格式
每个文档以JSONL格式存储,便于处理和集成到各种应用程序中。数据集托管在Hugging Face上,便于访问和版本控制。
用途
该数据集特别适用于:
- 技术文档系统
- 知识库
- 搜索实现
- 训练与文档相关的机器学习模型
您可以使用标准工具和库直接从Hugging Face仓库访问和下载该数据集。
搜集汇总
数据集介绍
构建方式
该数据集名为tech-docs,精心收集了涵盖多种云原生技术、基础设施工具及机器学习框架的技术文档和指南。其构建方式基于对多个领域的技术文档进行系统性整理,包括云平台(如GCP、EKS)、Kubernetes生态系统(如Kubernetes参考文档、ArgoCD、Cilium)、基础设施即代码(如Terraform)、可观测性工具(如Prometheus、Grafana)、服务网格(如Istio)、机器学习框架(如scikit-learn)等。这些文档以JSONL格式存储,便于处理和集成,确保了数据集的结构化和易用性。
特点
tech-docs数据集的显著特点在于其广泛的技术覆盖面和多样化的应用场景。该数据集不仅涵盖了主流的云平台和Kubernetes生态系统,还涉及基础设施管理、可观测性工具、服务网格以及机器学习框架等多个领域。此外,数据集采用JSONL格式,便于快速处理和集成,适合用于构建技术文档系统、知识库、搜索实现以及训练与文档相关的机器学习模型。
使用方法
该数据集适用于多种技术文档处理场景,包括但不限于构建技术文档系统、创建知识库、实现搜索功能以及训练与文档相关的机器学习模型。用户可以通过Hugging Face平台直接访问和下载数据集,利用标准工具和库进行处理和分析。数据集的JSONL格式使得其易于集成到各种应用程序中,为开发者提供了便捷的数据资源。
背景与挑战
背景概述
随着云计算和DevOps实践的迅猛发展,技术文档在现代软件开发中的作用愈发重要。tech-docs数据集应运而生,由专业团队精心策划,汇集了涵盖云原生技术、基础设施工具及机器学习框架的1,397份技术文档。该数据集不仅涵盖了如GCP、EKS、Kubernetes等主流云平台和工具的文档,还包括了Terraform、Prometheus、Istio等关键技术的详细指南。其创建旨在为技术文档系统、知识库构建及文档相关的机器学习模型训练提供丰富的资源,极大地推动了相关领域的研究与应用。
当前挑战
尽管tech-docs数据集在技术文档领域具有显著的应用价值,但其构建过程中仍面临诸多挑战。首先,技术文档的多样性和复杂性使得数据的标准化和结构化处理变得尤为困难。其次,不同技术领域的文档风格和术语差异较大,如何确保数据集的统一性和可用性是一大难题。此外,随着技术的快速迭代,文档的更新频率极高,如何保持数据集的时效性和准确性也是一项持续的挑战。这些因素共同构成了tech-docs数据集在实际应用中的主要障碍。
常用场景
经典使用场景
tech-docs数据集在技术文档系统中展现了其经典应用场景,尤其适用于构建和优化知识库、实现高效的文档检索系统以及训练与文档相关的机器学习模型。通过该数据集,开发者能够利用丰富的技术文档资源,提升自动化问答和文本生成的能力,从而在复杂的软件开发和DevOps实践中提供精准的技术支持。
实际应用
在实际应用中,tech-docs数据集被广泛用于构建企业级技术文档系统、开发智能搜索工具以及支持DevOps实践中的自动化流程。例如,该数据集可用于训练模型以自动生成技术文档,或用于构建能够快速响应开发者查询的知识库,从而显著提升软件开发和运维的效率。
衍生相关工作
tech-docs数据集的发布催生了一系列相关研究和工作,特别是在技术文档的自动化生成和智能检索领域。基于该数据集,研究者们开发了多种文档解析和信息提取模型,推动了自然语言处理技术在技术文档领域的应用。此外,该数据集还为多个开源项目提供了基础数据支持,促进了技术文档处理工具的发展。
以上内容由遇见数据集搜集并总结生成


