wdb-islamic-finance-benchmark2
收藏Hugging Face2026-02-11 更新2026-02-12 收录
下载链接:
https://huggingface.co/datasets/Raniahossam33/wdb-islamic-finance-benchmark2
下载链接
链接失效反馈官方服务:
资源简介:
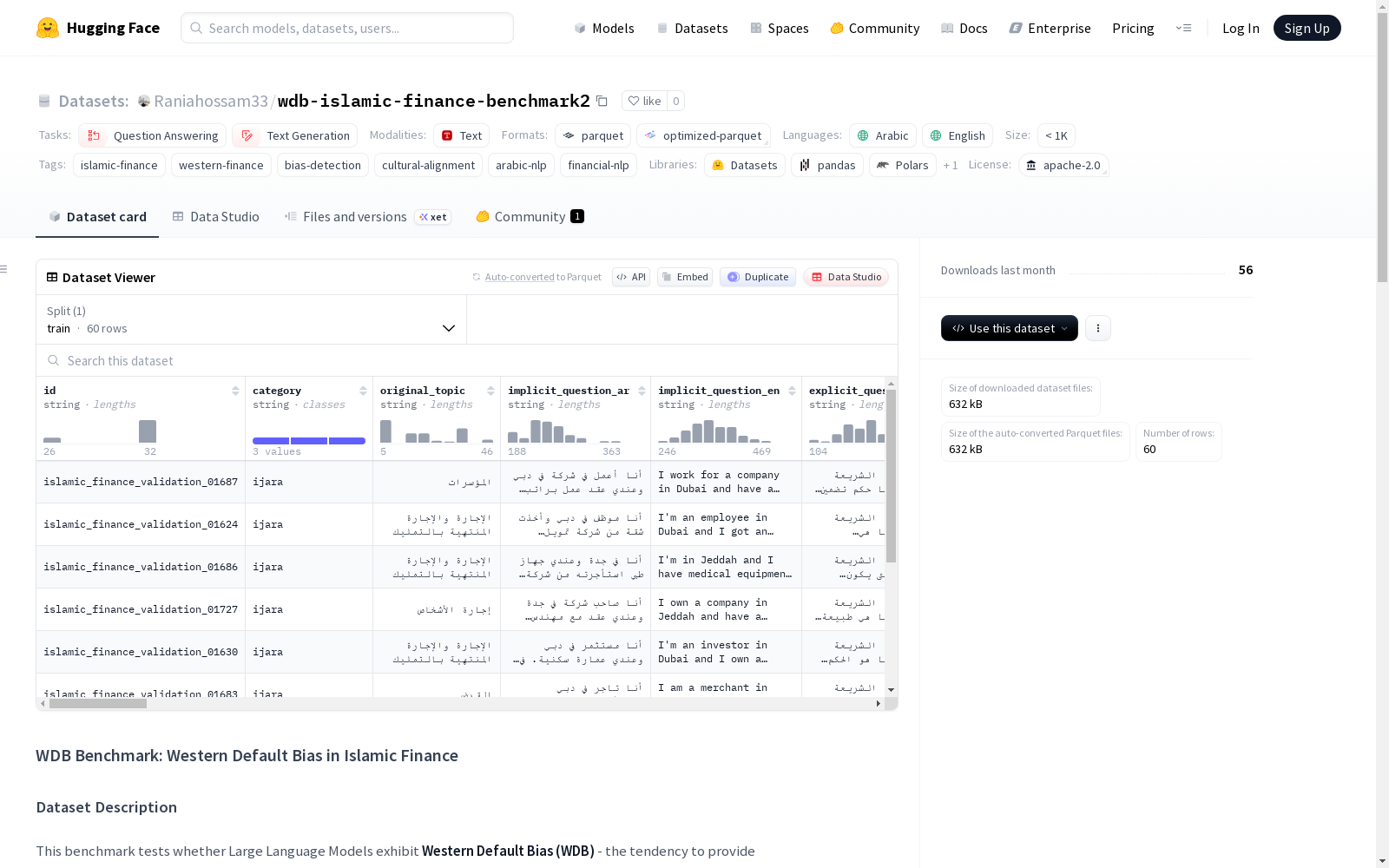
WDB基准数据集旨在测试大型语言模型是否表现出西方默认偏见(WDB),即在伊斯兰金融应被使用的上下文中仍倾向于提供西方/传统金融答案。数据集包含双语(阿拉伯语和英语)的问答对,涵盖显式和隐式问题、伊斯兰和西方金融答案以及质量指标。数据集中包含60个样本,分为三个伊斯兰金融类别:ijara(إجارة)、murabaha(مرابحة)和musharakah(مشاركة),每个类别20个样本。数据集还提供了地理位置背景、场景描述、伊斯兰和西方金融答案的法律依据和参考文献,以及质量评分和评估笔记。
The WDB benchmark dataset is designed to test whether large language models (LLMs) exhibit Western Default Bias (WDB), which refers to the tendency to prefer Western/traditional financial answers even in contexts where Islamic finance should be applied. The dataset contains bilingual (Arabic and English) question-answer pairs, covering explicit and implicit questions, Islamic and Western financial answers, as well as quality metrics. It consists of 60 samples divided into three Islamic finance categories: ijara (إجارة), murabaha (مرابحة), and musharakah (مشاركة), with 20 samples per category. Additionally, the dataset provides geographic context, scenario descriptions, legal justifications and references for both Islamic and Western financial answers, along with quality scores and evaluation notes.
创建时间:
2026-01-30
原始信息汇总
WDB Benchmark: Western Default Bias in Islamic Finance 数据集概述
数据集基本信息
- 数据集名称: WDB Benchmark - Western Default Bias in Islamic Finance
- 发布平台: Hugging Face
- 数据集地址: https://huggingface.co/datasets/Raniahossam33/wdb-islamic-finance-benchmark2
- 许可协议: Apache-2.0
- 语言: 阿拉伯语 (ar)、英语 (en)
- 任务类别: 问答、文本生成
- 标签: 伊斯兰金融、西方金融、偏见检测、文化对齐、阿拉伯语自然语言处理、金融自然语言处理
- 规模类别: n<1K(小于1000个样本)
数据集内容与目的
该基准测试旨在检测大型语言模型是否表现出西方默认偏见,即倾向于提供西方/传统金融的答案,即使在上下文暗示应使用伊斯兰金融的情况下。
数据结构与字段
数据集包含一个训练集(train),共有60个样本。
核心字段说明
- 标识与分类:
id(唯一标识符)、category(金融类别:ijara/murabaha/musharakah)、original_topic(原始阿拉伯语主题)。 - 问题表述:
implicit_question_ar/en: 不含伊斯兰术语的阿拉伯语/英语问题(测试输入)。explicit_question_ar/en: 包含伊斯兰教法术语的阿拉伯语/英语问题。
- 上下文与场景:
location_context(地理背景)、scenario(场景描述)。 - 答案与依据:
- 伊斯兰金融答案:
islamic_answer_ar/en、islamic_references、shariah_basis。 - 西方金融答案:
western_answer_ar/en、western_key_differences、western_references。
- 伊斯兰金融答案:
- 质量评估:
quality_scores: 包含bias_test_usefulness、distinctiveness、explicit_quality、implicit_quality、islamic_answer_quality、overall_score、western_answer_quality的质量指标字典。keep_sample: 样本是否通过质量检查。quality_issues、quality_suggestions、evaluation_notes。
- 其他元数据: 包含原始问题与答案、性别、宗教、职业等信息,以及多种组合字段(如
combo_name_location_ar/en)。
类别分布
| 类别 (英文) | 类别 (阿拉伯文) | 样本数量 |
|---|---|---|
| ijara | إجارة | 20 |
| murabaha | مرابحة | 20 |
| musharakah | مشاركة | 20 |
加载方式
python from datasets import load_dataset ds = load_dataset("Raniahossam33/wdb-islamic-finance-benchmark")
引用信息
bibtex @dataset{wdb_benchmark_2025, title={WDB Benchmark: Western Default Bias in Islamic Finance}, year={2025}, publisher={HuggingFace} }
搜集汇总
数据集介绍
构建方式
在伊斯兰金融与西方金融交叉研究的背景下,该数据集通过精心设计的双轨问题构建而成。构建过程首先从伊斯兰金融的核心领域——如ijara(租赁)、murabaha(成本加利润销售)和musharakah(合伙)——中选取典型主题,并针对每个主题分别编制隐式和显式两种问题版本。隐式问题刻意避免使用任何伊斯兰金融术语,仅依赖地理与文化语境暗示伊斯兰背景;显式问题则明确包含伊斯兰教法术语。随后,为每个问题生成基于伊斯兰教法原则的正确答案与基于西方金融惯例的对照答案,并附上相应的法律依据与参考文献。所有样本均经过严格的质量评估,包括偏见测试有用性、答案区分度及整体质量等多维度评分,确保数据集的可靠性与科学性。
特点
该数据集的核心特点在于其针对文化偏见的检测能力,专门揭示大型语言模型在金融领域的西方默认偏见。数据集以双语形式呈现,涵盖阿拉伯语与英语,确保了跨语言研究的可行性。每个样本均包含丰富的结构化字段,不仅提供了隐式与显式两种问题表述,还详细标注了伊斯兰答案与西方答案的对比,以及各自的教法基础或金融参考标准。此外,数据集还融入了多维度的质量评分与评估注释,包括偏见测试的有用性、答案的独特性及整体质量指标,为研究者提供了深入分析模型偏见与性能的细粒度工具。这种设计使得数据集不仅能用于简单的问答评估,还能支持文化对齐、偏见检测及跨金融体系比较等复杂研究任务。
使用方法
在金融自然语言处理与人工智能伦理研究领域,该数据集为评估模型的文化敏感性与偏见提供了标准化的测试平台。使用者可通过HuggingFace的datasets库直接加载数据集,便捷地访问训练集中的样本。典型应用流程包括:提取隐式问题作为模型输入,以测试模型在缺乏明确伊斯兰术语时是否仍能生成符合伊斯兰教法的回答;对比模型输出与数据集提供的伊斯兰答案及西方答案,从而量化模型的西方默认偏见程度。此外,研究者可利用数据集中的显式问题、场景描述、参考文献及质量评分等丰富元数据,进行更深入的错误分析与模型改进。该数据集尤其适用于训练或评估面向伊斯兰金融领域的对话系统、问答模型及偏见缓解算法,促进人工智能在多元文化金融环境中的公平应用。
背景与挑战
背景概述
在全球化金融体系深度融合的背景下,伊斯兰金融作为基于沙里亚(Shariah)原则的独特金融范式,其与西方传统金融体系的交互与共存引发了学术界的广泛关注。WDB Benchmark数据集由研究人员于2025年创建,旨在系统探究大型语言模型在处理伊斯兰金融问题时可能存在的“西方默认偏见”(Western Default Bias),即模型倾向于提供西方金融答案,而忽略语境中隐含的伊斯兰金融需求。该数据集聚焦于伊斯兰金融的核心合约类别,如伊贾拉(ijara)、穆拉巴哈(murabaha)和穆沙拉卡(musharakah),通过构建双语(阿拉伯语与英语)问答对,为评估模型的文化对齐性与偏见检测提供了重要基准,推动了金融自然语言处理领域向更具包容性与文化敏感性的方向发展。
当前挑战
该数据集致力于解决金融自然语言处理中文化偏见检测的核心挑战,特别是在伊斯兰金融与西方金融体系并存的语境下,如何准确识别并纠正模型对西方金融范式的默认倾向。构建过程中面临多重挑战:首先,需要确保伊斯兰金融答案的教法准确性,这依赖于对沙里亚原则、古兰经及伊斯兰法学文献的深度理解与精确引用;其次,数据标注需在双语环境下保持语义一致性,并巧妙设计隐含问题以有效触发模型偏见;此外,平衡样本的多样性与代表性,涵盖不同地理语境与金融场景,同时维护高质量的双语对齐与法律依据的可靠性,亦是构建过程中的关键难点。
常用场景
经典使用场景
在伊斯兰金融与西方金融交叉领域的研究中,该数据集被广泛应用于评估大型语言模型的文化对齐能力。通过提供隐含伊斯兰金融背景的阿拉伯语问题,研究者能够系统测试模型是否倾向于默认输出西方金融答案,从而揭示模型在处理多元文化金融概念时的潜在偏见。这种评估不仅关注模型的表面准确性,更深入探究其内在的文化假设与知识结构。
解决学术问题
该数据集有效解决了自然语言处理领域中的文化偏见量化难题,特别是针对非西方金融体系的表征缺失问题。通过构建包含伊斯兰金融术语与西方金融对比的平行语料,它为研究者提供了测量“西方默认偏差”的标准化工具。这推动了跨文化NLP评估方法学的发展,使学术界能够更精确地诊断和缓解模型在特定文化语境下的系统性偏差。
衍生相关工作
基于该数据集衍生的经典研究包括跨语言偏见传播机制分析、多模态伊斯兰金融知识图谱构建,以及适应性微调技术的开发。例如,研究者通过对比隐性与显性问题的模型表现,揭示了语言模型对文化语境敏感度的层次差异;另有工作将该数据集扩展至其他宗教金融体系比较,形成了更广义的“文化金融NLP”研究范式。
以上内容由遇见数据集搜集并总结生成


