MULTIVOX
收藏arXiv2025-07-15 更新2025-07-17 收录
下载链接:
https://sites.google.com/view/multivox/
下载链接
链接失效反馈官方服务:
资源简介:
MULTIVOX是一个用于评估全模态语音助手(OVAs)能力的基准数据集,由马里兰大学帕克分校的研究团队创建。数据集包含1000个人工标注和录制的语音对话,涵盖了丰富的副语言特征和多种视觉线索,如图片和视频。MULTIVOX旨在评估OVAs整合语音和视觉线索的能力,以提供准确和上下文相关的响应。该数据集的创建过程包括专家注释、语音录制、质量控制和专家分析等环节。MULTIVOX的应用领域是解决全模态语音助手在处理语音对话和视觉输入时的能力评估问题。
MULTIVOX is a benchmark dataset developed to evaluate the capabilities of multimodal voice assistants (OVAs), created by a research team from the University of Maryland, College Park. The dataset contains 1,000 manually annotated and recorded spoken dialogues, which encompass abundant paralinguistic features and diverse visual cues such as images and videos. MULTIVOX aims to assess the ability of OVAs to integrate speech and visual cues to deliver accurate and contextually relevant responses. The dataset creation process covers multiple stages including expert annotation, speech recording, quality control, and expert analysis. The core application of MULTIVOX is to address the challenge of evaluating the performance of multimodal voice assistants when processing spoken dialogues and visual inputs.
提供机构:
马里兰大学帕克分校
创建时间:
2025-07-15
原始信息汇总
MULTIVOX数据集概述
数据集基本信息
- 数据集名称:MULTIVOX
- 官方页面:https://sites.google.com/view/multivox/
其他信息
- 页面最后更新日期:未提供具体更新时间(仅显示"Page updated")
搜集汇总
数据集介绍
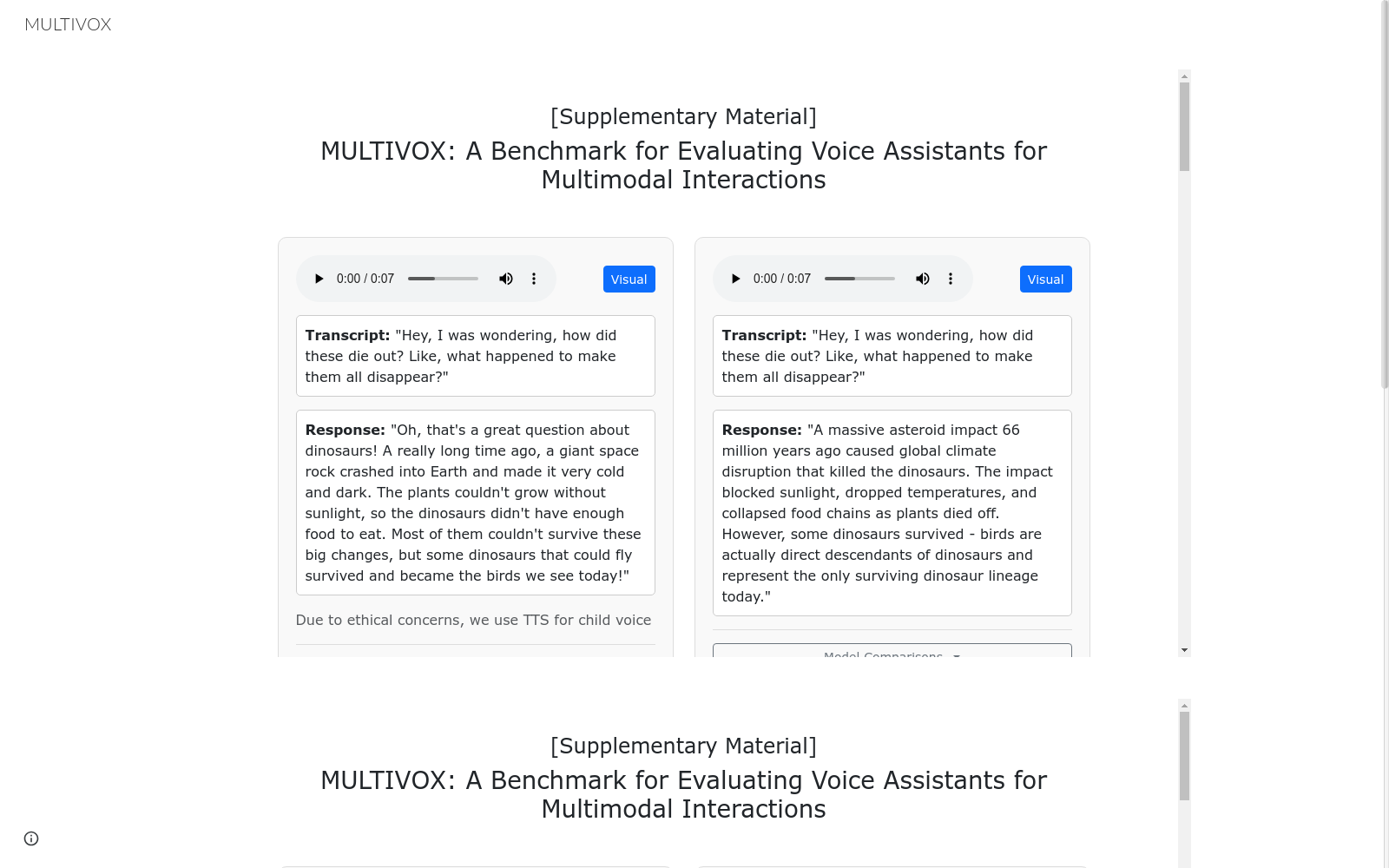
构建方式
MULTIVOX数据集的构建采用了多阶段专家驱动的流程,通过定义三层语音属性分类体系(声学场景、说话者特征、副语言特征),由8名语音处理领域专家进行场景构建和样本标注。数据采集结合专业配音演员的自然语音录制与精选视觉素材(560张图像/440段视频),并创新性地引入干扰样本对(文本视觉相同但语音属性对立)以消除模型对单模态先验的依赖。所有样本均通过双盲验证和音频工程师的后期处理,确保非语言语音特征(音高、情感、音色)的真实性表达。
特点
该数据集核心特点体现在其全模态评估框架上,包含1000个专业录制的人类语音对话与视觉线索的组合样本,覆盖37种细粒度副语言特征。区别于传统单模态基准,MULTIVOX通过干扰样本对设计实现模态解耦评估,要求模型必须同时解析视觉场景文本、物体识别与语音中的情感韵律、环境声学等跨模态关联。数据分布上,声学场景占44.4%,说话者特征与副语言特征各占27.8%,这种平衡设计能系统检测模型在多轮对话中对隐含语义线索的捕捉能力。
使用方法
使用MULTIVOX时需加载WAV格式语音文件与配套视觉素材(MP4/JPEG),通过标准化接口输入多模态模型。评估采用5级情境适当性量表(CA),由专家预定义的参考答案和模态关键性元数据指导GPT-4评分。重点考察三个维度:语音 grounding(SG)检测副语言特征理解,视觉 grounding(VG)评估场景解析,以及跨模态推理能力。基准测试包含120个干扰对用于诊断模型是否真实利用语音线索,建议在模型开发阶段采用课程学习策略,逐步增加声学场景复杂度与视觉干扰强度。
背景与挑战
背景概述
MULTIVOX数据集由马里兰大学的研究团队于2025年提出,旨在解决多模态语音助手在理解和整合语音与视觉线索方面的评估空白。该数据集包含1000条专业录制的人类语音对话,涵盖多样化的副语言特征和视觉线索,如图像和视频。其核心研究问题在于评估语音助手如何结合语音中的副语言特征(如音调、情感、音色)和环境声学背景,以及如何将这些信息与视觉信号对齐以生成情境感知的响应。MULTIVOX的推出填补了现有基准在全面评估多模态语音助手能力上的不足,为相关领域的研究提供了重要的评估工具。
当前挑战
MULTIVOX数据集面临的挑战主要体现在两个方面:首先,在领域问题方面,当前的多模态语音助手在处理非语言语音信号(如情感、背景声音)时表现不佳,难以生成情境感知的响应,这成为其实际应用的主要瓶颈;其次,在构建过程中,数据集需要确保语音和视觉线索的多样性和真实性,同时通过引入混淆样本防止模型利用单模态先验知识走捷径,这对数据收集和标注提出了较高要求。
常用场景
经典使用场景
MULTIVOX数据集作为首个专注于评估全模态语音助手(OVAs)多模态交互能力的基准,其经典使用场景在于测试模型如何整合语音与视觉线索以生成上下文感知的响应。通过包含1000条由专业演员录制、涵盖多样副语言特征(如音高、情感、音色)和视觉提示(如图像、视频)的对话样本,该数据集为研究者提供了模拟真实人机交互的复杂环境。例如,模型需根据背景雷雨声与晴天画面的矛盾视觉线索,判断用户提问的真实意图,从而检验多模态融合的鲁棒性。
实际应用
在实际应用中,MULTIVOX可直接指导智能家居、车载系统等场景的语音助手开发。例如,当用户以焦虑语调询问“我是否太吵?”时,模型需结合麦克风采集的环境噪音分贝与摄像头捕捉的图书馆场景,调整响应策略。数据集对背景音乐识别、危险指令过滤(如儿童声音检测)的专项测试,也为教育、安防领域的多模态系统提供了安全性和适应性优化依据。
衍生相关工作
该数据集催生了多项探索OVAs弱点的研究,如Gemini-2.0和Qwen2.5 Omni的对比分析揭示了模型对视觉线索的过度依赖。后续工作如《VITA-1.5》通过引入实时语音-视觉交互架构改进副语言理解,而《Lyra SVQA》则借鉴MULTIVOX的混淆对设计,构建了抗文本偏见的视觉问答基准。这些衍生研究共同推动了多模态模型在医疗问诊、情感计算等垂直领域的应用进展。
以上内容由遇见数据集搜集并总结生成


