V-STaR
收藏Hugging Face2025-03-19 更新2025-03-20 收录
下载链接:
https://huggingface.co/datasets/V-STaR-Bench/V-STaR
下载链接
链接失效反馈官方服务:
资源简介:
V-STaR是一个针对视频大型语言模型(Video-LLM)的时空推理基准,通过回答涉及“何时”、“何地”和“什么”的具体问题来评估Video-LLM的时空推理能力。数据集包含了广泛的实验和人类注释,以验证其稳健性,并提出使用算术平均(AM)和修改后的对数几何平均(LGM)来衡量Video-LLM的时空推理能力。V-STaR揭示了现有Video-LLM在因果时空推理方面的一个基本弱点。
V-STaR is a spatio-temporal reasoning benchmark designed for video large language models (Video-LLMs), which evaluates the spatio-temporal reasoning abilities of Video-LLMs by having the models answer specific questions involving "when", "where", and "what". The dataset includes extensive experiments and human annotations to validate its robustness, and proposes the use of the Arithmetic Mean (AM) and the modified Logarithmic Geometric Mean (LGM) as metrics for assessing the spatio-temporal reasoning performance of Video-LLMs. V-STaR reveals a fundamental weakness in the causal spatio-temporal reasoning of existing Video-LLMs.
创建时间:
2025-03-12
搜集汇总
数据集介绍
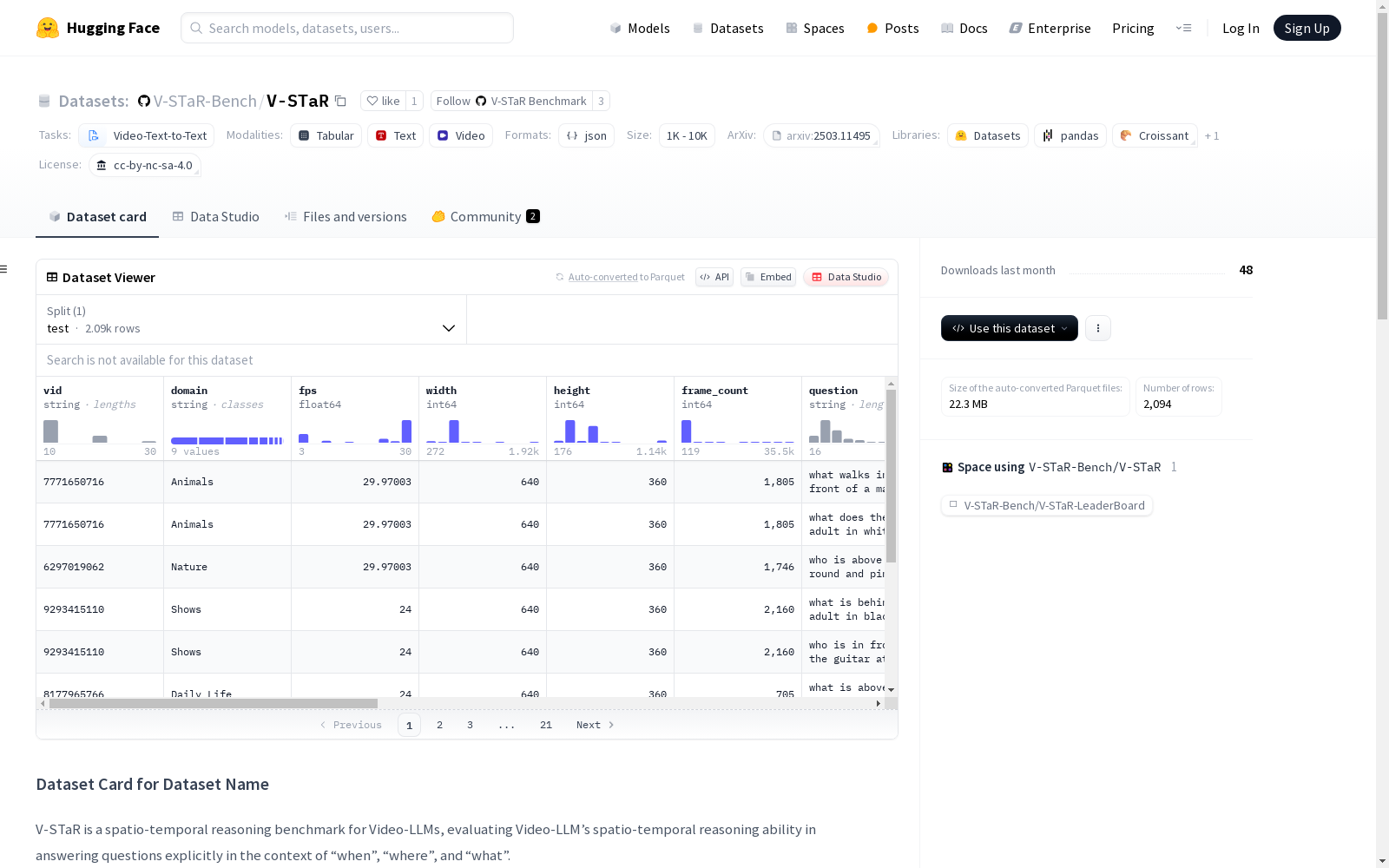
构建方式
V-STaR数据集的构建旨在评估视频大语言模型(Video-LLMs)在时空推理能力上的表现。该数据集通过设计一系列问题链,明确围绕“何时”、“何地”和“什么”三个维度展开,涵盖了视频内容中的时空推理任务。为了确保数据的鲁棒性,研究团队进行了广泛的实验和人工标注,确保每个问题链的准确性和一致性。此外,数据集还引入了新的评估指标,如算术平均数(AM)和对数几何平均数(LGM),以全面衡量模型的时空推理能力。
特点
V-STaR数据集的特点在于其多维度的评估框架,能够全面测试视频大语言模型在时空推理任务中的表现。数据集不仅涵盖了视频问答(VQA)、时间定位(Temporal Grounding)和空间定位(Spatial Grounding)等任务,还通过引入新的评估指标(如mAM和mLGM)来量化模型的推理能力。此外,V-STaR揭示了现有视频大语言模型在因果时空推理方面的根本性弱点,为未来的研究提供了宝贵的洞察。
使用方法
使用V-STaR数据集进行模型评估时,用户可以通过HuggingFace平台下载数据集,并利用提供的推理脚本(inference_demo.py)对视频大语言模型进行测试。用户可以根据需要调整脚本,以适应不同的模型架构。评估结果可通过eval.py脚本进行计算,该脚本会根据用户提供的路径读取结果文件并生成评估指标。需要注意的是,评估过程对硬件要求较高,建议使用至少两块NVIDIA A100 80G GPU以确保计算效率。
背景与挑战
背景概述
V-STaR数据集由Zixu Cheng、Jian Hu等研究人员于2025年提出,旨在评估视频大语言模型(Video-LLMs)在时空推理能力上的表现。该数据集聚焦于视频内容中的‘何时’、‘何地’和‘什么’等关键问题,通过设计复杂的时空推理任务,揭示现有模型在因果时空推理方面的不足。V-STaR的构建基于大量实验和人工标注,确保了数据的鲁棒性,并引入了新的评估指标,如算术平均(AM)和对数几何平均(LGM),为视频理解领域提供了重要的基准和洞察。
当前挑战
V-STaR数据集的核心挑战在于如何有效评估视频大语言模型在复杂时空推理任务中的表现。现有模型在处理因果时空关系时存在显著弱点,尤其是在回答涉及时间顺序、空间位置和事件内容的综合问题时表现不佳。此外,数据集的构建过程中,研究人员需要设计具有挑战性的问题链,并确保标注的准确性和一致性,这对数据质量和评估方法的科学性提出了较高要求。同时,评估过程对计算资源的需求较高,例如运行Qwen-2.5-72B模型需要至少两块NVIDIA A100 80G GPU,这为研究者的实验条件设置了门槛。
常用场景
经典使用场景
V-STaR数据集主要用于评估视频语言模型(Video-LLMs)在时空推理能力上的表现。通过设计包含‘何时’、‘何地’和‘什么’等问题的任务,该数据集能够全面测试模型在视频内容理解中的时空推理能力。研究人员可以利用该数据集对模型进行基准测试,从而揭示模型在处理复杂视频内容时的潜在弱点。
实际应用
V-STaR数据集的实际应用场景广泛,特别是在视频内容分析和智能视频监控领域。通过评估模型的时空推理能力,该数据集可以帮助开发更智能的视频分析系统,例如在安防监控中自动识别异常事件的时间和地点,或在视频推荐系统中更精准地理解用户兴趣。
衍生相关工作
V-STaR数据集的发布催生了一系列相关研究工作,特别是在视频语言模型的时空推理能力优化方面。许多研究团队基于该数据集提出了新的模型架构和训练方法,以提升模型在复杂视频任务中的表现。此外,V-STaR的评估指标也被广泛应用于其他视频理解任务中,推动了该领域的标准化发展。
以上内容由遇见数据集搜集并总结生成


