openslr-140-hq-Kazakh
收藏Hugging Face2024-08-24 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/voice-biomarkers/openslr-140-hq-Kazakh
下载链接
链接失效反馈官方服务:
资源简介:
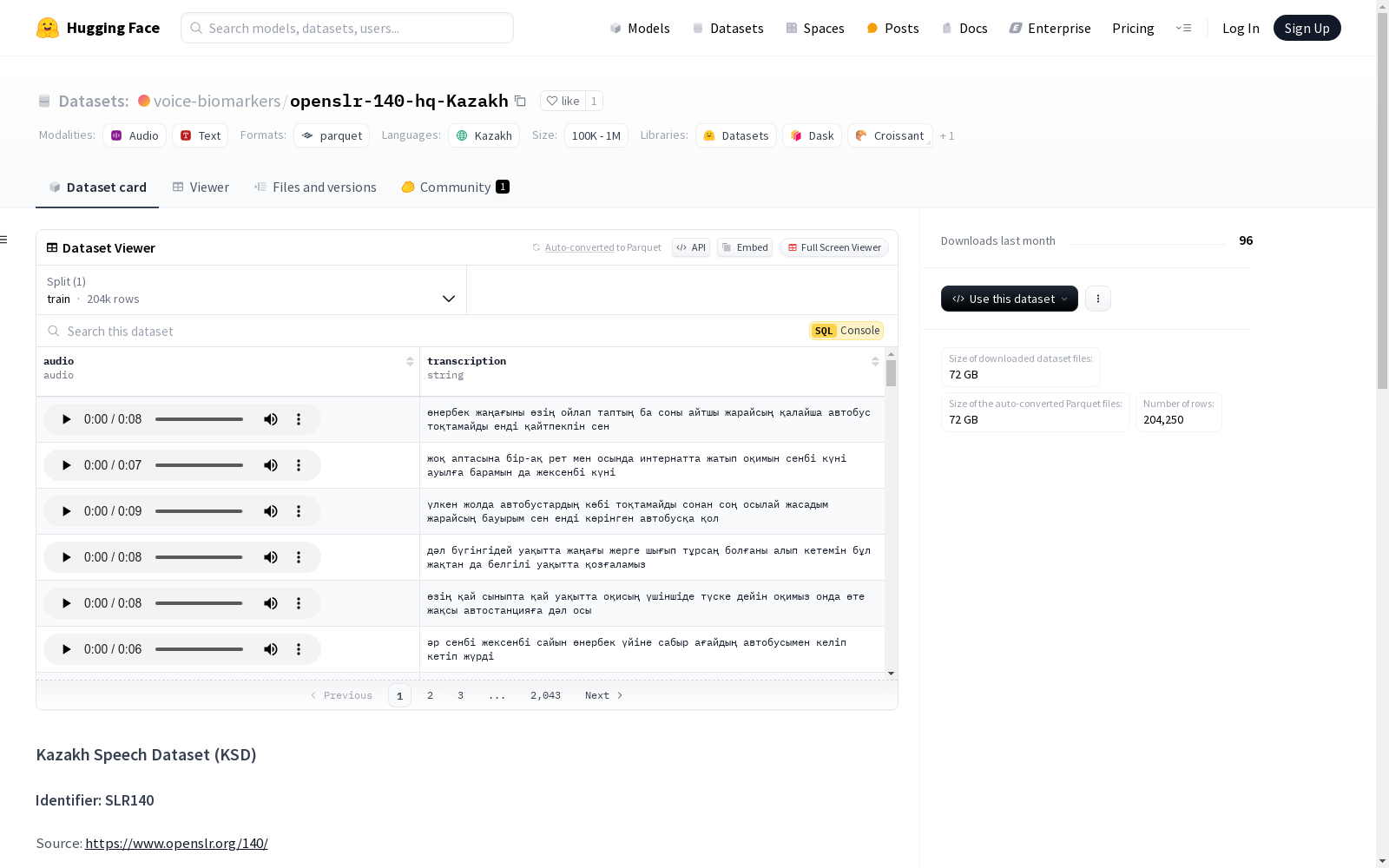
这是一个高质量的开源哈萨克语语音语料库,由Al-Farabi哈萨克国立大学的人工智能和大数据系开发。该语料库包含约554小时的转录音频记录,包括204250个由来自不同地区和年龄组的参与者以及男女双方说出的语句。所有音频文件都是使用移动设备(iOS和Android)录制的,并由哈萨克语母语者进行选择性检查以确保高质量。数据集主要用于训练自动语音识别系统。音频文件的技术特性是.wav格式,16 kB,22和44 kHz。
This is a high-quality open-source Kazakh speech corpus developed by the Department of Artificial Intelligence and Big Data of Al-Farabi Kazakh National University. The corpus contains approximately 554 hours of transcribed audio recordings, including 204,250 utterances spoken by participants from different regions and age groups, as well as both male and female speakers. All audio files were recorded using mobile devices (iOS and Android) and selectively verified by native Kazakh speakers to ensure high quality. This dataset is primarily used for training automatic speech recognition (ASR) systems. The technical specifications of the audio files are WAV format, 16 kB, with sampling rates of 22 kHz and 44 kHz.
创建时间:
2024-08-23
原始信息汇总
Kazakh Speech Dataset (KSD)
基本信息
- 标识符: SLR140
- 来源: OpenSLR
- 类别: 语音
- 许可证: Attribution-ShareAlike 3.0 Unported (CC BY-SA 3.0 US)
数据集概述
- 总时长: 554小时
- 音频文件格式: .wav
- 采样率: 16 kHz, 22 kHz, 44 kHz
- 音频特征:
- 名称: audio
- 数据类型: audio
- 转录文本特征:
- 名称: transcription
- 数据类型: string
数据集划分
- 训练集:
- 文件路径: data/train-*
- 样本数量: 204250
- 字节数: 60099013529.5
数据集大小
- 下载大小: 72019155235
- 数据集大小: 60099013529.5
语言
- 语言: 哈萨克语 (kk)
数据集创建者
引用
bibtex @inproceedings{ mansurova-kadyrbek-2023-kazakh-speech-dataset, title = "The Development of a Kazakh Speech Recognition Model Using a Convolutional Neural Network with Fixed Character Level Filters", author = "Madina Mansurova and Nurgali Kadyrbek", booktitle = "Proceedings of the Big Data and Cognitive Computing", month = "July 20", year = "2023", pages = "5--9", url = "https://doi.org/10.3390/bdcc7030132" }
搜集汇总
数据集介绍
构建方式
openslr-140-hq-Kazakh数据集是由哈萨克国立大学人工智能与大数据部门开发的高质量哈萨克语语音语料库。该数据集包含约554小时的转录音频记录,共计204250条语音样本,涵盖了不同地区、年龄组和性别的参与者。所有音频文件均通过移动设备(iOS和Android)录制,并经过哈萨克语母语者的选择性检查,以确保数据的高质量。音频文件的技术规格为.wav格式,采样率为22和44 kHz,位深为16位。
特点
该数据集的特点在于其广泛覆盖了哈萨克语的多样性,涵盖了不同地区、年龄和性别的语音样本,确保了数据的代表性和多样性。此外,所有音频文件均经过严格的母语者检查,确保了转录的准确性。数据集的高质量使其特别适合用于训练自动语音识别系统,尤其是针对哈萨克语的语音识别任务。音频文件的格式和采样率也为后续的语音处理提供了良好的基础。
使用方法
openslr-140-hq-Kazakh数据集主要用于训练和评估哈萨克语自动语音识别系统。用户可以通过HuggingFace平台下载数据集,并利用其提供的音频文件和转录文本进行模型训练。数据集的结构清晰,包含训练集,用户可以直接加载并使用这些数据进行模型开发。此外,数据集的开放性和高质量使其成为研究哈萨克语语音处理的重要资源,用户还可以根据需要进行数据预处理和特征提取,以优化模型的性能。
背景与挑战
背景概述
openslr-140-hq-Kazakh数据集是由哈萨克斯坦国立大学人工智能与大数据系开发的高质量哈萨克语语音语料库,创建于2023年。该数据集由Nurgali Kadyrbek和Madina Mansurova主导开发,旨在为哈萨克语自动语音识别系统的训练提供支持。数据集包含约554小时的转录音频,涵盖来自不同地区、年龄组和性别的204,250条语音样本。所有音频文件均通过移动设备录制,并经过哈萨克语母语者的质量检查,确保了数据的高质量。该数据集的发布为哈萨克语语音识别领域的研究提供了重要的资源支持,推动了该领域的技术进步。
当前挑战
openslr-140-hq-Kazakh数据集在构建过程中面临多重挑战。首先,哈萨克语作为一种低资源语言,其语音数据的收集和标注成本较高,且缺乏成熟的标注工具和标准。其次,数据集的多样性要求涵盖不同地区、年龄和性别的语音样本,这对数据采集的广度和深度提出了较高要求。此外,确保音频质量的一致性也是一个技术难点,尤其是在移动设备录制的环境下,背景噪声和录音条件的差异可能导致数据质量波动。最后,数据集的规模较大,存储和处理的技术要求较高,这对计算资源和数据处理能力提出了挑战。这些挑战的解决为哈萨克语语音识别技术的发展提供了宝贵的经验。
常用场景
经典使用场景
在语音识别领域,openslr-140-hq-Kazakh数据集被广泛用于训练和评估哈萨克语自动语音识别(ASR)系统。该数据集包含了来自不同地区、年龄和性别的参与者录制的554小时高质量音频,涵盖了丰富的语音变体,为模型训练提供了多样化的语音样本。通过该数据集,研究人员能够构建更加鲁棒的哈萨克语语音识别模型,提升其在真实场景中的表现。
实际应用
在实际应用中,openslr-140-hq-Kazakh数据集为哈萨克语语音助手、语音翻译系统和语音驱动的智能设备提供了关键支持。例如,基于该数据集训练的语音识别模型可以集成到哈萨克语地区的智能客服系统中,提升用户体验。此外,该数据集还可用于开发教育领域的语音学习工具,帮助用户提高哈萨克语发音和听力能力。
衍生相关工作
openslr-140-hq-Kazakh数据集的发布催生了一系列相关研究工作,例如基于卷积神经网络(CNN)的哈萨克语语音识别模型开发。研究人员利用该数据集优化了语音特征提取和模型训练方法,显著提升了哈萨克语语音识别的准确率。此外,该数据集还被用于多语言语音识别系统的对比研究,为跨语言语音技术的融合提供了实验数据支持。
以上内容由遇见数据集搜集并总结生成


