ayan4m1/myanimelist-recommendations
收藏Hugging Face2026-03-28 更新2026-03-29 收录
下载链接:
https://hf-mirror.com/datasets/ayan4m1/myanimelist-recommendations
下载链接
链接失效反馈官方服务:
资源简介:
---
license: mit
task_categories:
- question-answering
language:
- en
size_categories:
- 1K<n<10K
---
---
许可证:MIT许可证
任务类别:
- 问答(question-answering)
语言:
- 英语(en)
样本规模类别:
- 样本数量介于1000至10000之间
---
提供机构:
ayan4m1
搜集汇总
数据集介绍
构建方式
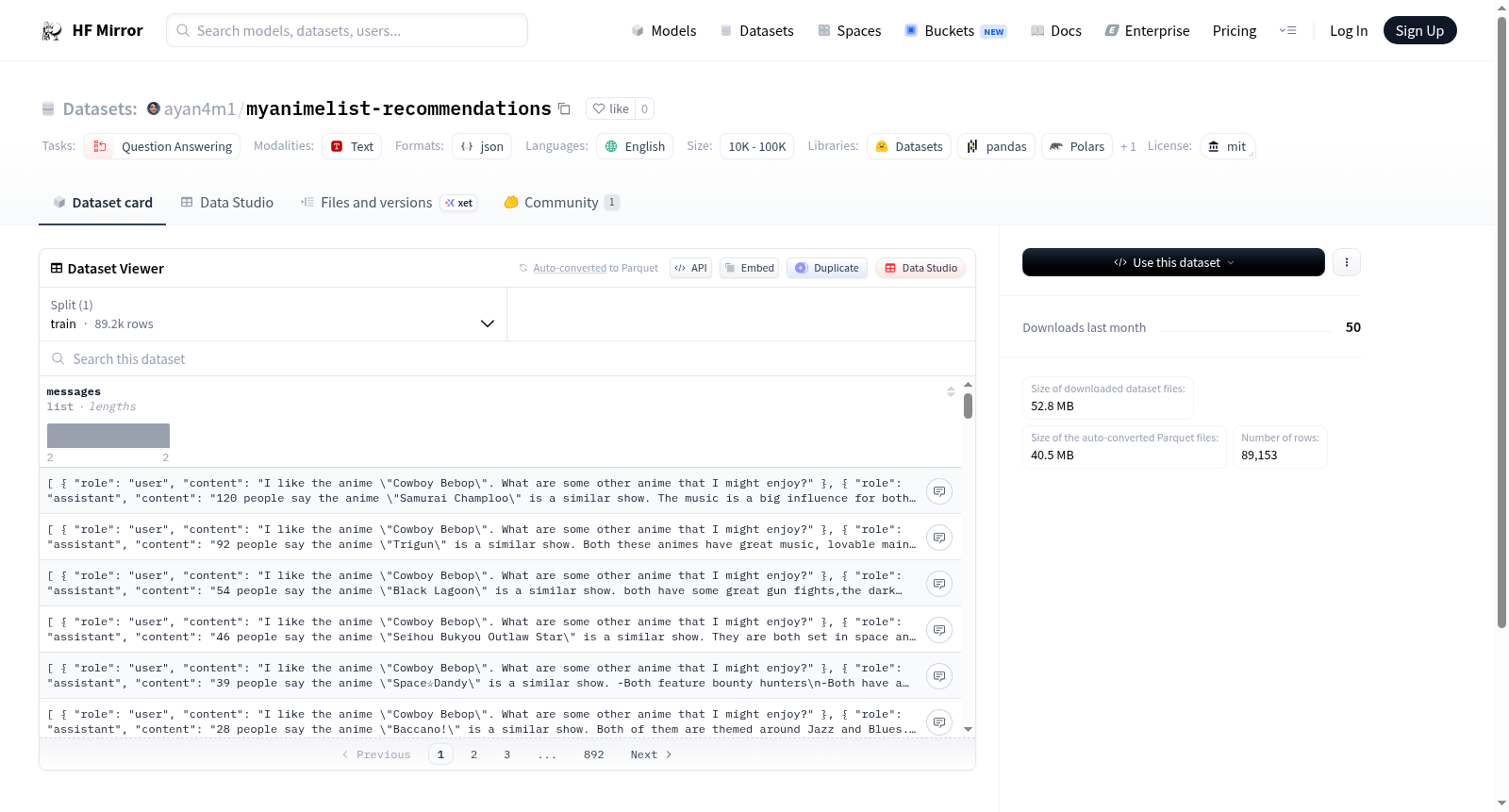
在动漫推荐系统研究领域,数据集的构建往往依赖于真实用户交互记录。本数据集通过自动化爬取技术,从知名动漫社区MyAnimeList的推荐功能页面系统性地采集信息,涵盖了该平台上约四千部最受欢迎的动漫作品,确保了数据来源的广泛性和代表性。这一构建过程注重数据的原始性和完整性,为推荐算法研究提供了扎实的基础。
特点
该数据集的核心特点在于其聚焦于用户生成的推荐关系,而非简单的评分或观看记录。它捕捉了动漫作品间的关联模式,反映了社区用户的集体偏好和认知结构。数据规模适中,介于一万到十万条之间,既保证了足够的分析深度,又避免了处理超大规模数据带来的复杂性,适用于多种机器学习模型的训练与验证。
使用方法
研究人员可将此数据集应用于问答或推荐系统任务中,探索动漫作品间的语义关联或构建个性化推荐模型。使用前需进行常规的数据清洗与预处理,如处理缺失值或格式化文本。随后,可以将其划分为训练集、验证集和测试集,用于模型训练、调优和性能评估,以推动推荐算法在动漫领域的发展。
背景与挑战
背景概述
在推荐系统与自然语言处理领域,用户生成内容的挖掘为个性化服务提供了关键数据支撑。myanimelist-recommendations数据集源于知名动漫社区MyAnimeList,其创建时间未明确标注,但依托该平台长期积累的用户互动数据,核心研究问题聚焦于如何基于社区驱动的推荐信息,提升动漫推荐算法的准确性与多样性。该数据集由数据采集者从网站“推荐”功能中提取,涵盖了约4000部高人气动漫,为研究社区偏好、协同过滤及问答系统提供了实证基础,对娱乐信息检索领域具有参考价值。
当前挑战
该数据集旨在应对动漫推荐系统中的领域挑战,即如何从稀疏且主观的用户反馈中,精准建模复杂偏好并处理长尾分布问题。在构建过程中,挑战主要源于数据采集的局限性:仅依赖热门动漫条目可能导致样本偏差,忽略小众作品的推荐价值;同时,网络爬取过程可能受网站结构变动或反爬机制影响,需解决数据完整性与时效性维护的困难。此外,原始推荐文本的噪声处理与标准化标注,也是提升数据集可用性的关键环节。
常用场景
经典使用场景
在推荐系统与信息检索领域,myanimelist-recommendations数据集为动漫内容个性化推荐提供了关键支撑。该数据集源自知名动漫社区MyAnimeList的推荐功能,涵盖了约4000部高人气动漫的用户推荐数据,常被用于训练和评估协同过滤、基于内容的推荐算法。研究人员利用这些数据构建用户-动漫交互矩阵,模拟真实场景下的推荐行为,以优化模型的准确性和多样性。
衍生相关工作
围绕该数据集,已衍生出多项经典研究工作,包括基于神经网络的混合推荐模型、利用图卷积网络处理动漫关系图谱的算法,以及结合自然语言处理技术分析用户评论的增强推荐系统。这些工作不仅扩展了推荐算法的理论边界,还推动了跨模态学习在娱乐产业的应用,为后续研究提供了丰富的技术参考与实验范式。
数据集最近研究
最新研究方向
在动漫推荐系统领域,基于myanimelist-recommendations数据集的研究正聚焦于跨模态内容理解与个性化生成。研究者们利用该数据集中的用户推荐对,结合深度学习模型,探索如何从文本评论中提取细粒度情感特征,并将其与动漫的视觉、叙事元素相融合,以构建更精准的推荐算法。这一方向与当前人工智能在娱乐产业的应用热潮紧密相连,例如生成式AI在内容创作中的兴起,推动了推荐系统向解释性和创造性方向发展。此类研究不仅提升了用户体验,还为动漫产业的智能化分发提供了数据支撑,具有重要的商业与学术价值。
以上内容由遇见数据集搜集并总结生成


