SynFlow-4k
收藏arXiv2026-04-10 更新2026-04-14 收录
下载链接:
https://kin-zhang.github.io/SynFlow/
下载链接
链接失效反馈官方服务:
资源简介:
SynFlow-4k是由瑞典皇家理工学院和香港科技大学联合开发的大规模合成数据集,专为LiDAR场景流估计设计。该数据集包含4000个序列(约94万帧),通过CARLA模拟器生成,覆盖多样化的道路拓扑和运动模式,标注量达到现有真实数据集的34倍。其创新之处在于采用运动导向的生成策略,优先考虑几何和时序交互复杂性而非传感器特异性真实感。数据集通过精确的物理引擎计算稠密无噪声的场景流标签,为自动驾驶中的3D运动感知提供了高效的预训练基础,显著降低了对真实标注数据的依赖。
SynFlow-4k is a large-scale synthetic dataset jointly developed by KTH Royal Institute of Technology and The Hong Kong University of Science and Technology, specifically designed for LiDAR scene flow estimation. This dataset contains 4000 sequences (approximately 940,000 frames) generated via the CARLA simulator, covering diverse road topologies and motion patterns, with an annotation scale 34 times that of existing real-world datasets. Its core innovation lies in adopting a motion-oriented generation strategy that prioritizes geometric and temporal interaction complexity over sensor-specific photorealism. The dataset computes dense, noise-free scene flow ground truth labels through a precise physics engine, providing an efficient pre-training foundation for 3D motion perception in autonomous driving and significantly reducing the reliance on real-world annotated data.
提供机构:
瑞典皇家理工学院·机器人感知与学习实验室; 香港科技大学
创建时间:
2026-04-10
原始信息汇总
SynFlow数据集概述
数据集名称
SynFlow / SynFlow-4k
核心描述
SynFlow是一个利用CARLA模拟器合成的、用于激光雷达(LiDAR)场景流估计的数据生成流程。它旨在通过合成数据提供多样化、完美标注的激光雷达场景流数据,以解决真实世界数据集中标注成本高、场景多样性有限的问题。该数据集为学习鲁棒的运动先验提供了可扩展的、密集且无噪声的监督源。
关键特性
- 数据性质:合成数据。
- 生成工具:基于CARLA模拟器。
- 标注质量:完美标注。
- 数据优势:提供多样化场景、可扩展的密集监督、无噪声。
- 应用目标:用于激光雷达场景流估计。
数据集构成与场景
数据集包含多种驾驶场景的合成数据:
- 城市驾驶场景
- 高速公路驾驶场景
- 乡村及郊区场景
效果与验证
- 训练效果:仅在SynFlow-4k数据集上训练的模型,在真实世界基准测试中展现出强大的零样本泛化能力。
- 微调效果:当在少量真实数据子集上进行微调后,其性能显著超过领域内基线模型。
- 定性结果示例:在TruckScenes序列上的比较表明,SynFlow-4k模型产生的运动模式更接近真实情况,在转弯动力学下更连贯;而领域内模型由于标注数据有限(仅20%标注),在同一物体上表现出较不一致的运动。
获取与状态
- 生成流程代码和数据集将在同行评审后公开。
- 更多详细信息可查阅主论文PDF。
相关引用
bibtex @article{zhang2026synflow, author = {Zhang, Qingwen and Zhu, Xiaomeng and Jiang, Chenhan and Jensfelt, Patric}, title = {SynFlow: Scaling Up LiDAR Scene Flow Estimation with Synthetic Data}, journal = {arXiv preprint arXiv:2604.09411}, year = {2026}, }
搜集汇总
数据集介绍
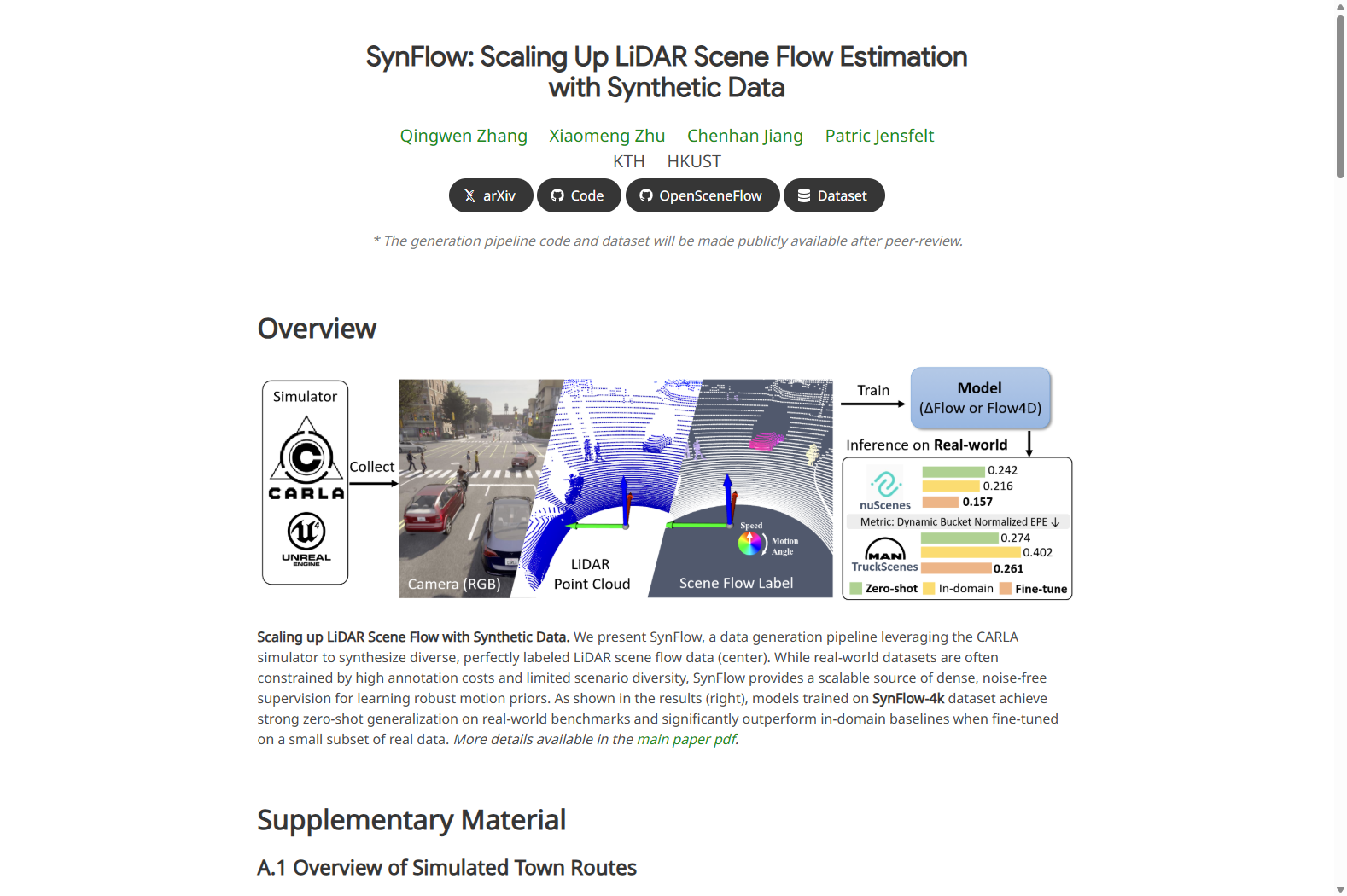
构建方式
在激光雷达场景流估计领域,获取密集且高质量的真实运动标注面临巨大挑战。SynFlow-4k数据集通过创新的合成数据生成范式构建,其核心是基于CARLA仿真器设计的一套以运动为导向的生成流程。该流程摒弃了对传感器特定真实感的过度追求,转而通过拓扑离散化、速度区间覆盖以及多智能体交互三大策略,主动合成涵盖圆环、交叉口、高速公路等多种道路拓扑的多样化运动模式。最终,该流程自动化生成了包含约94万帧、4000个序列的大规模合成数据,其标注规模达到现有真实世界基准的34倍,为模型学习提供了纯净且丰富的运动监督信号。
特点
SynFlow-4k数据集的核心特点在于其规模性与运动先验的强泛化能力。该数据集通过仿真环境主动控制,实现了对长尾道路结构和复杂交互场景的密集覆盖,提供了真实世界日志中往往稀缺的动力学细节。其标注不仅无噪声,而且具备与骨干网络架构无关的强可迁移性。实验表明,仅在该合成数据上训练的模型,能够在零样本条件下泛化至不同传感器配置的真实世界数据集,其性能甚至可媲美或超越部分在真实数据上全监督训练的基线模型,这验证了物理一致的运动关系本身具有高度的跨域可迁移性。
使用方法
SynFlow-4k数据集主要服务于激光雷达场景流模型的训练与评估,其使用方法灵活高效。研究者可直接使用该数据集进行大规模监督预训练,以获取强健的通用运动先验。随后,可通过零样本评估直接测试模型在nuScenes、TruckScenes等真实基准上的泛化能力。更为实用的方式是将其作为预训练基础,仅需使用5%至20%的真实标注数据进行微调,即可使模型性能显著超越从零开始在全部可用真实数据上训练的基线,从而极大降低对昂贵真实标注的依赖。此外,该合成数据亦可与大规模真实世界预训练模型结合,互补地提升模型在长尾交互场景下的性能。
背景与挑战
背景概述
在自动驾驶领域,可靠的三维动态感知依赖于能够预测任意物体运动的模型,然而密集、高质量运动标注数据的稀缺严重制约了相关研究进展。针对这一瓶颈,由瑞典皇家理工学院与香港科技大学的研究团队于2026年联合提出了SynFlow-4k数据集。该数据集的核心研究问题在于如何通过可扩展的合成数据生成范式,为激光雷达场景流估计提供大规模、高质量的监督信号。SynFlow-4k摒弃了传统追求传感器级真实感的思路,转而采用以运动为导向的生成策略,利用CARLA模拟器合成了涵盖4000个序列、约94万帧的密集标注数据,其标注规模达到现有真实世界基准的34倍。这一工作范式转变,为学习具有强领域不变性的运动先验知识提供了全新路径,显著推动了可泛化三维运动估计领域的发展。
当前挑战
SynFlow-4k数据集旨在解决激光雷达场景流估计这一核心领域问题所面临的挑战。该任务要求预测连续点云之间密集、点对点的三维运动,其核心挑战在于获取真实世界数据的精确稠密运动标注极其困难且成本高昂,而基于几何一致性的自监督方法则受限于代理信号的噪声和约束不足。在数据集构建过程中,研究团队面临的主要挑战是如何设计生成策略以超越对传感器特定真实感的模仿,转而专注于合成具有高度多样性的运动学模式。这需要精心设计拓扑离散化、速度机制覆盖以及多智能体交互等核心策略,以程序化方式生成涵盖复杂道路拓扑和丰富运动模式的交互场景,从而确保合成数据能够提供可迁移至真实世界的稳健运动先验。
常用场景
经典使用场景
在自动驾驶领域,激光雷达场景流估计旨在预测动态环境中连续点云之间的密集三维运动场,为下游路径规划与交互提供几何中心化的动态表征。SynFlow-4k数据集通过其大规模合成数据生成流程,为这一任务提供了经典的使用场景。该数据集在CARLA仿真环境中构建了涵盖多种道路拓扑与交通密度的交互场景,生成约940k帧带有精确标注的序列,其规模达到现有真实世界基准的34倍以上。研究者通常利用该数据集训练场景流估计模型,以学习鲁棒的运动先验,进而在零样本或少量标注条件下实现向真实世界数据的泛化。
实际应用
SynFlow-4k数据集在自动驾驶系统的动态感知模块中具有直接的实际应用价值。训练于该数据集的模型能够零样本泛化至不同传感器配置的真实世界环境,如nuScenes和TruckScenes等基准,甚至在卡车场景中超越领域内监督基线31.8%。在实际部署中,该数据集可作为高效的预训练基础,仅需5%的真实标注进行微调,即可达到或超越使用全量标注训练的模型性能。这大幅减少了自动驾驶系统开发中对昂贵真实数据标注的依赖,提升了动态环境理解的鲁棒性与经济性,为安全导航与决策提供了可靠支撑。
衍生相关工作
SynFlow-4k数据集的推出催生了一系列围绕合成数据与场景流估计的经典研究工作。其基础框架SynFlow验证了运动导向的合成策略的有效性,启发了后续研究探索仿真数据在三维动态感知中的潜力。相关衍生工作包括将合成数据与大规模真实世界数据集(如Argo-v2、Waymo)进行互补融合的研究,例如UniFlow模型,结合两者后能在行人等动态类别上实现显著性能提升。此外,该数据集也促进了针对不同骨干架构(如DeFlow、Flow4D)的零样本泛化能力分析,证明了其提供的运动先验具有架构无关的通用性,为领域内数据驱动方法的创新奠定了坚实基础。
以上内容由遇见数据集搜集并总结生成


