elevenlabs_multilingual_v2-technical-speech
收藏Hugging Face2025-01-05 更新2025-01-06 收录
下载链接:
https://huggingface.co/datasets/WpythonW/elevenlabs_multilingual_v2-technical-speech
下载链接
链接失效反馈官方服务:
资源简介:
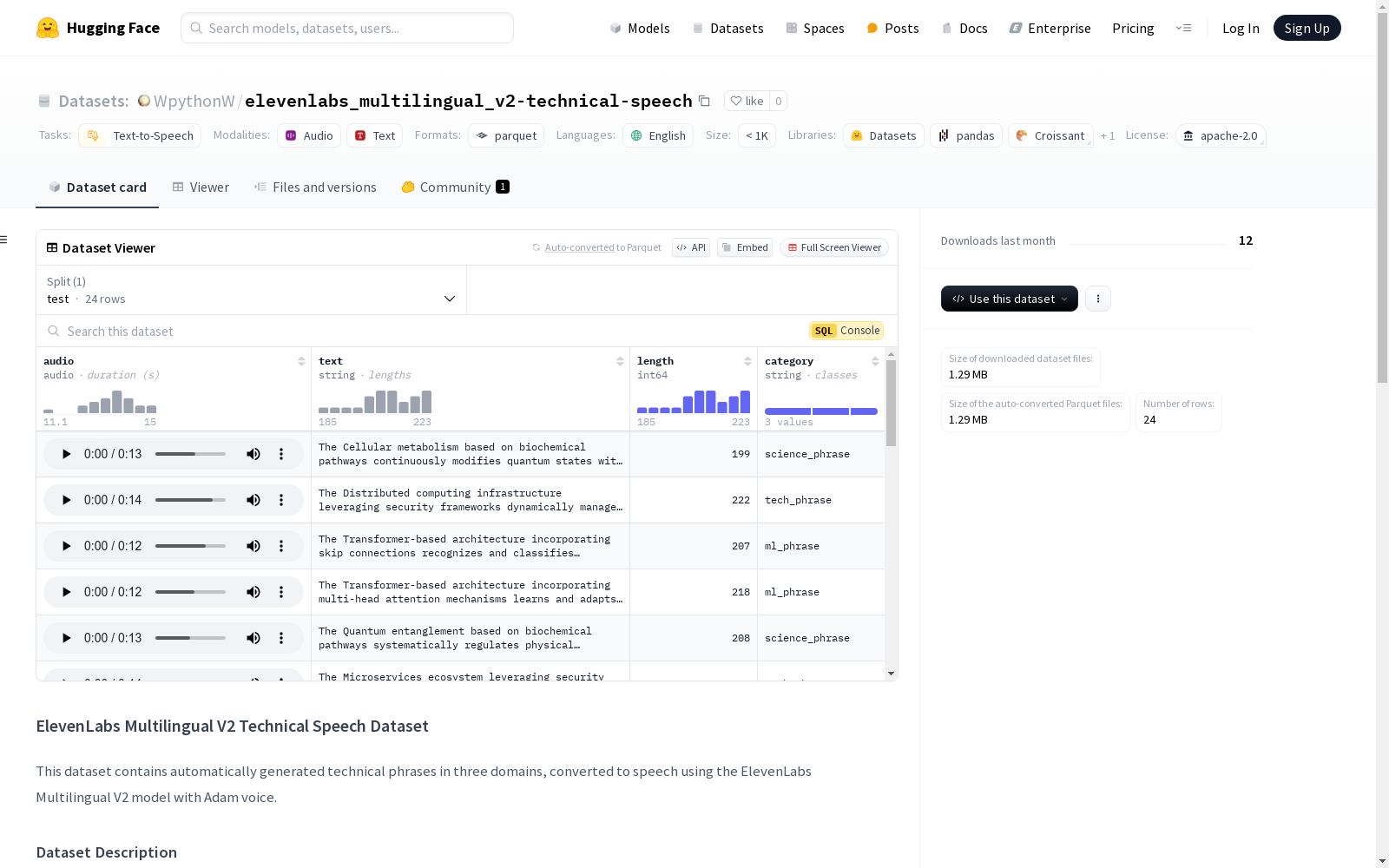
该数据集包含使用ElevenLabs Multilingual V2模型和Adam声音自动生成的技术短语的音频样本,涵盖三个领域:机器学习(ML)、科学和技术。每个条目包含MP3格式的音频文件(22050Hz)、源文本、文本长度和类别标签。数据生成过程使用了预定义的模板来创建连贯的技术陈述,所有音频都是使用ElevenLabs Multilingual V2模型和Adam声音合成的,声音设置包括稳定性、相似性增强、风格和说话者增强。
This dataset comprises audio samples of technical phrases automatically generated using the ElevenLabs Multilingual V2 model and the Adam voice, covering three domains: Machine Learning (ML), Science, and Technology. Each entry contains an MP3-formatted audio file (22050Hz), source text, text length, and category label. The data generation process uses predefined templates to create coherent technical statements, and all audio is synthesized using the ElevenLabs Multilingual V2 model and the Adam voice, with voice settings including stability, similarity enhancement, style, and speaker enhancement.
创建时间:
2025-01-05
搜集汇总
数据集介绍
构建方式
ElevenLabs Multilingual V2 Technical Speech数据集的构建采用了自动生成技术短语的方法,涵盖了机器学习、科学和技术三个领域。通过预定义的模板生成连贯的技术陈述,随后利用ElevenLabs Multilingual V2模型和Adam声音进行语音合成。语音合成的参数包括稳定性、相似性增强、风格和说话者增强等,确保了语音的自然度和一致性。
特点
该数据集的特点在于其多样化的技术领域覆盖和高质量的语音合成。每个样本包含MP3格式的音频文件、源文本、文本长度和类别标签,音频采样率为22050Hz。数据集通过自动生成的短语和专业的语音合成技术,提供了丰富的技术语音资源,适用于文本到语音转换任务的研究和应用。
使用方法
使用ElevenLabs Multilingual V2 Technical Speech数据集时,研究人员和开发者可以通过加载音频文件和对应的文本信息,进行文本到语音模型的训练和评估。数据集的结构化格式便于直接应用于机器学习管道,支持对技术语音合成的深入分析和优化。通过调整语音合成参数,用户可以进一步探索不同设置对语音质量的影响。
背景与挑战
背景概述
ElevenLabs Multilingual V2 Technical Speech数据集由ElevenLabs团队创建,旨在为多语言技术语音合成领域提供高质量的语音数据。该数据集于近期发布,主要聚焦于机器学习和科学技术领域的多语言技术短语生成。通过使用ElevenLabs Multilingual V2模型和Adam语音合成技术,数据集生成了涵盖机器学习、科学和技术三个领域的语音样本。这些样本不仅包含了音频文件,还附带了源文本、文本长度和类别标签,为语音合成和自然语言处理研究提供了丰富的实验材料。该数据集的发布为多语言技术语音合成领域的研究提供了新的基准,推动了语音合成技术在技术领域的应用。
当前挑战
ElevenLabs Multilingual V2 Technical Speech数据集在构建过程中面临多重挑战。首先,技术领域的文本生成需要确保内容的准确性和专业性,这对模板设计和生成算法提出了较高要求。其次,多语言语音合成的质量依赖于模型的稳定性和语音的自然度,如何在保持语音清晰度的同时提升语音的情感表达和风格多样性是一个技术难点。此外,数据集的规模相对较小,可能限制了其在复杂任务中的泛化能力。如何扩展数据集规模并保持数据质量,是未来研究中的一个重要挑战。
常用场景
经典使用场景
在语音合成技术的研究中,elevenlabs_multilingual_v2-technical-speech数据集被广泛用于评估和优化多语言技术语音生成模型。该数据集通过提供包含机器学习、科学和技术领域的音频样本,帮助研究人员测试模型在不同技术语境下的表现。
衍生相关工作
基于elevenlabs_multilingual_v2-technical-speech数据集,许多研究工作得以展开,包括改进多语言语音合成模型、开发新的语音识别算法以及探索技术语音在不同应用场景中的优化策略。这些工作进一步推动了语音技术在实际应用中的普及和提升。
数据集最近研究
最新研究方向
在语音合成领域,ElevenLabs Multilingual V2 Technical Speech数据集为多语言技术语音生成提供了新的研究视角。该数据集通过自动生成的技术短语,结合ElevenLabs Multilingual V2模型和Adam语音,生成了涵盖机器学习、科学和技术三个领域的语音样本。当前研究热点集中在如何进一步提升语音合成的自然度和多语言适应性,特别是在技术领域的专业术语处理上。此外,该数据集的应用还推动了语音合成技术在智能助手、教育工具和跨语言通信中的创新应用,具有重要的学术和商业价值。
以上内容由遇见数据集搜集并总结生成


